词向量:
简而言之,词向量就是将一个词转化为稠密向量,对于相似的词,它们的向量也应该相近,如“高兴”和“快乐”。
词的表示有两种表示:
(1)离散表示,基于规则的,如:苹果 [0,0,0,1,0,0,0,0,0,……]向量维度为词表的维度,1就表示当前苹果位于词表的位置。
(2)分布式表示,即将词转化为词向量表示。
然后讨论如何生成词向量:
(1)基于统计方法
在一个事先指定的窗口大小内,统计共现(共现可能是指某两个词连续出现的意思)词的出现次数,然后以窗口内共现词出现的次数作为某个词的词向量。如:有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
则其共现矩阵如下:
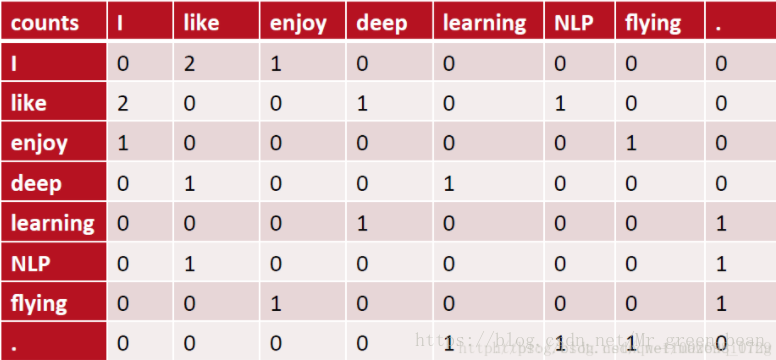
计算出共现矩阵,考虑到共现矩阵数据稀疏(即有很多零)和维度灾难(即维度可能会很大),所以进行奇异值(SVD)分解,得到正交矩阵,然后对正交矩阵进行归一化。如下:
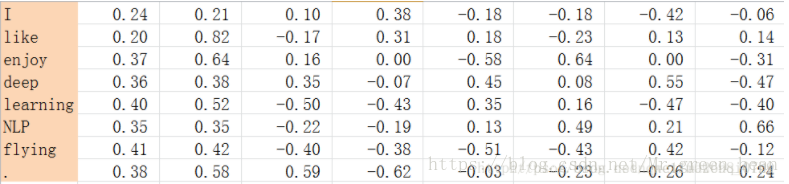
在这里有疑问:矩阵维度又没减少,做这个有什么用?似乎还不如共现矩阵方便。
(2)基于语言模型
通过训练神经网络语言模型(NNLM),词向量作为语言模型的附带产出。
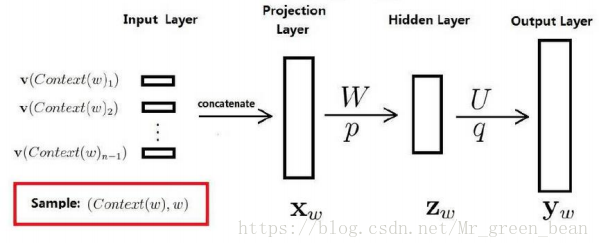
NNLM的基本思想是根据上下文预测当前词为某个特定词的概率。如预测“我今天打篮球”中的“篮球”这个词,现已知
训练样本:v(Context(w)1)(我)、v(Context(w)2)(今天)、v(Context(w)3)(打)
然后拼接上述训练样本,得到投影层中的大向量“我今天打”,先不管隐藏层,输出层为在上下文为上述训练样本时,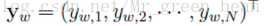 (表示下一个为词典中第i个词的概率)。然后归一化处理:
(表示下一个为词典中第i个词的概率)。然后归一化处理: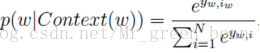 (不知道为什么要归一化)
(不知道为什么要归一化)
较著名的采用NNLM生成词向量的方法有:Skip-gram、CBOW、LBL、NNLM、C&W、GloVe等。
最后
以上就是甜甜鸡最近收集整理的关于词向量简单总结的全部内容,更多相关词向量简单总结内容请搜索靠谱客的其他文章。



![[2020-3-13]BNUZ套题比赛div3 题解目录](https://www.shuijiaxian.com/files_image/reation/bcimg9.png)

![[2020-2-28]BNUZ套题比赛div3解题报告](https://www.shuijiaxian.com/files_image/reation/bcimg11.png)


发表评论 取消回复