我是靠谱客的博主 单纯野狼,这篇文章主要介绍【学习笔记】北京理工大学-Python网络爬虫与信息提取一.Requests库二.Beautiful Soup库三.Re库(正则表达式)四.Scrapy爬虫框架,现在分享给大家,希望可以做个参考。
Python网络爬虫与信息提取
- 一.Requests库
- Requests库的7个主要方法
- Response对象的属性
- ☆爬取网页的通用代码框架
- HTTP协议
- 网络爬虫的尺寸
- 如何限制网络爬虫?
- 实例代码
- 二.Beautiful Soup库
- 信息提取
- 三.Re库(正则表达式)
- 正则表达式常用操作符
- Re库
- 四.Scrapy爬虫框架
- requests vs Scrapy
- Scrapy爬虫常用命令
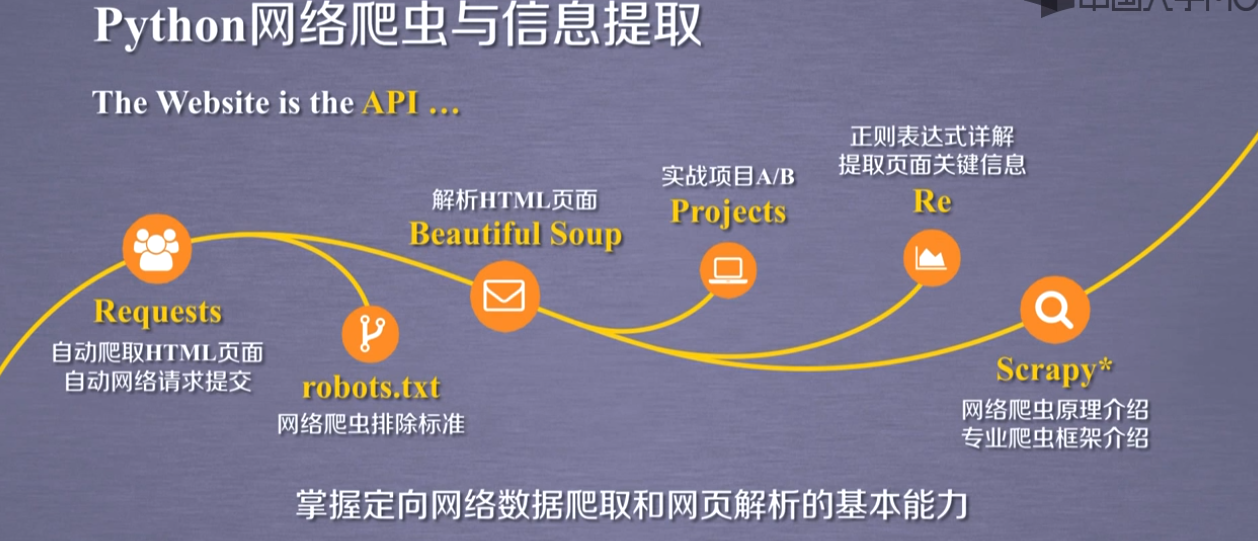
掌握定向网络数据爬取和网页解析基本能力
一.Requests库

Requests库的7个主要方法

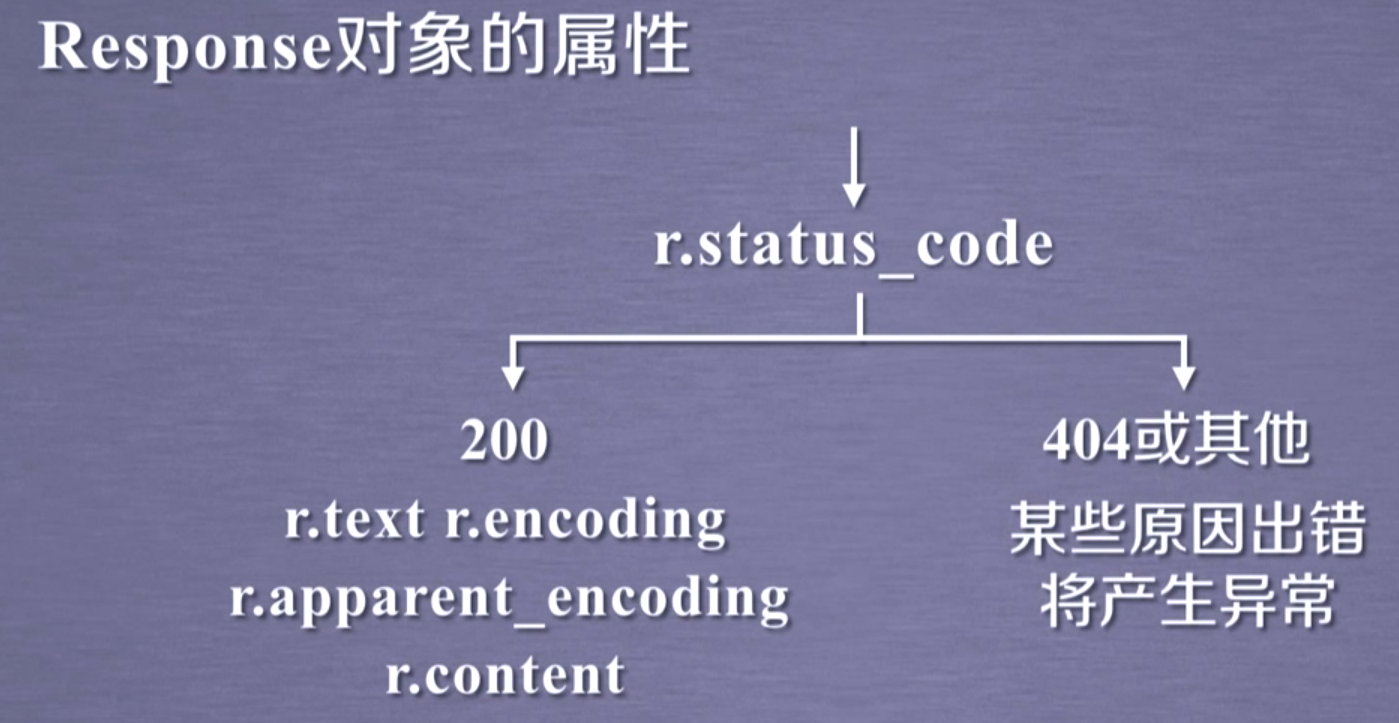
Response对象的属性

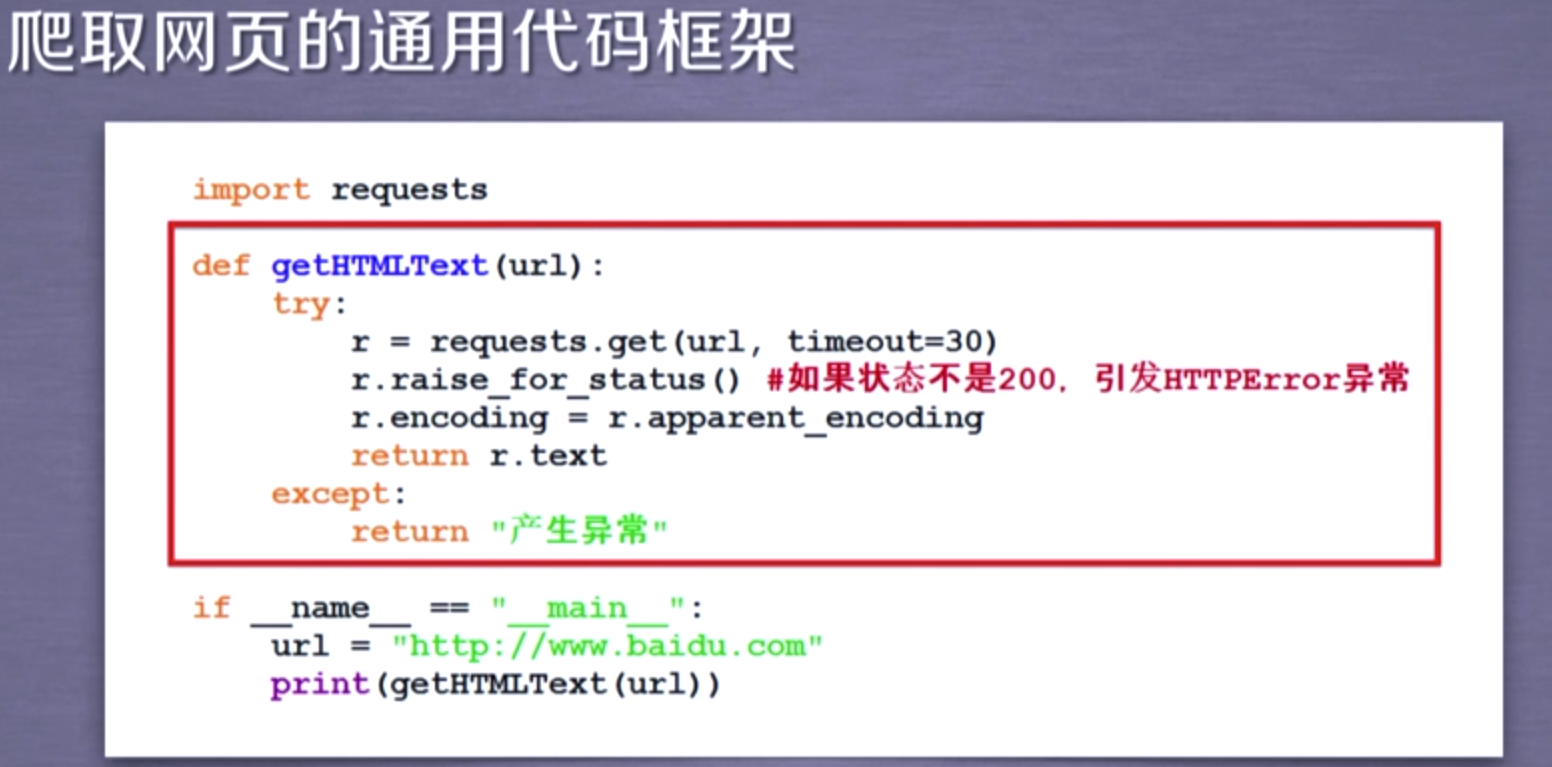
☆爬取网页的通用代码框架
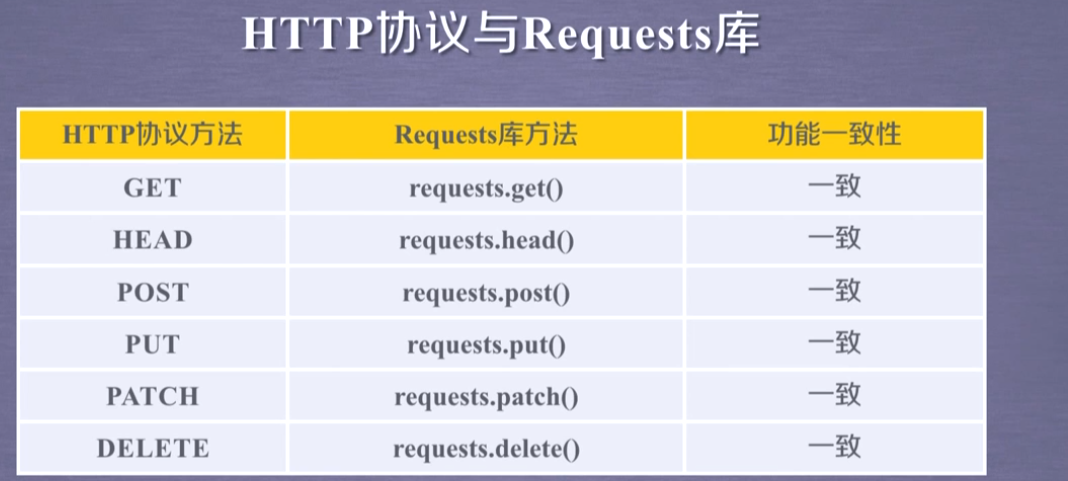
HTTP协议





cookies 英[ˈkʊkiz]
n. 曲奇饼; 精明强干的人; 坚强的人; 网络饼干(网络或互联网使用者发给中央服务器信息的计算机文件);
proxy , proxies:英[ˈprɒksiz]
n. 代理权; 代表权; 代理人; 受托人; 代表; (测算用的)代替物,指标;

最常用的是get方法,对于内容大的用head方法
网络爬虫的尺寸

如何限制网络爬虫?


实例代码
二.Beautiful Soup库
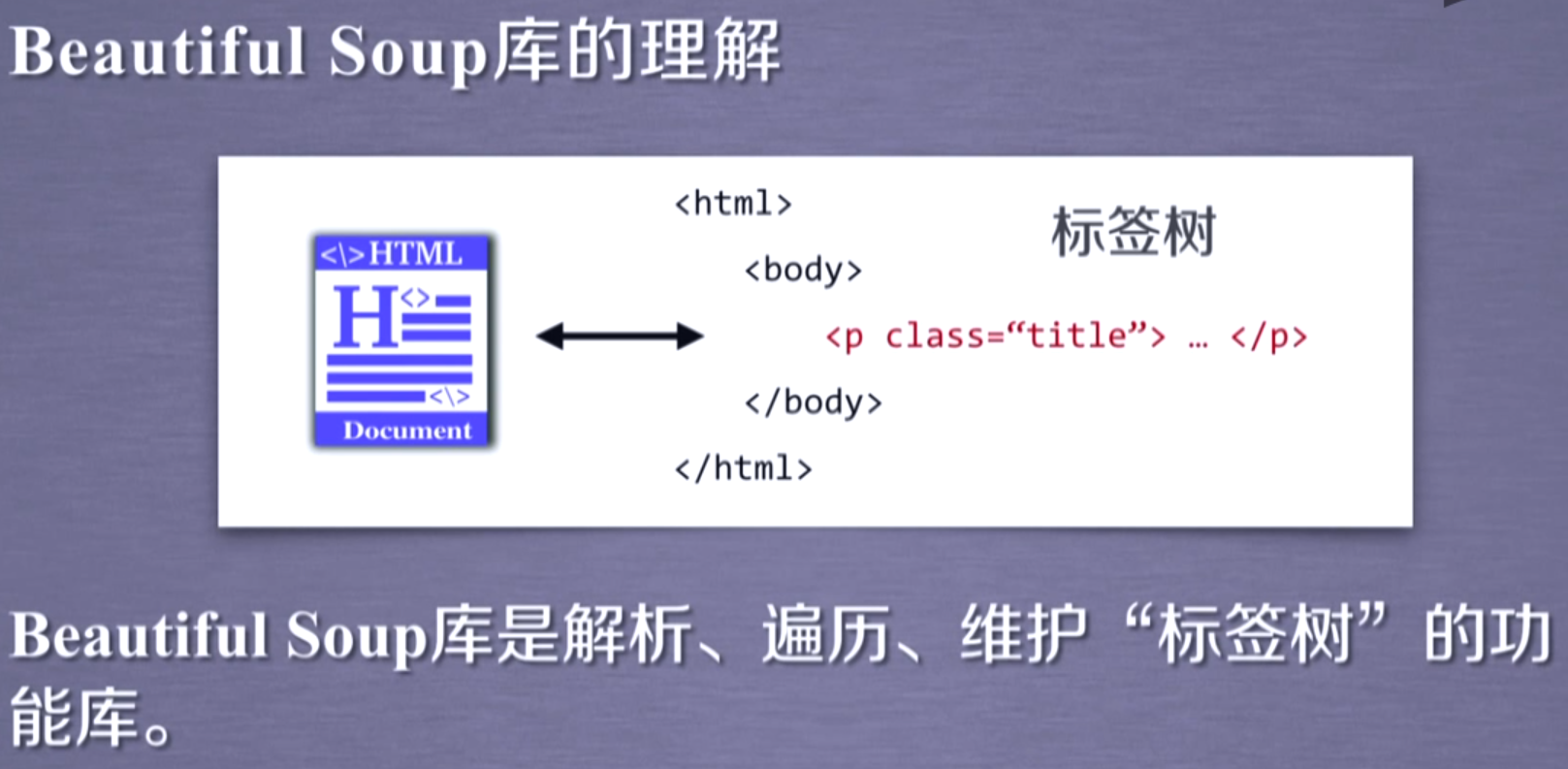
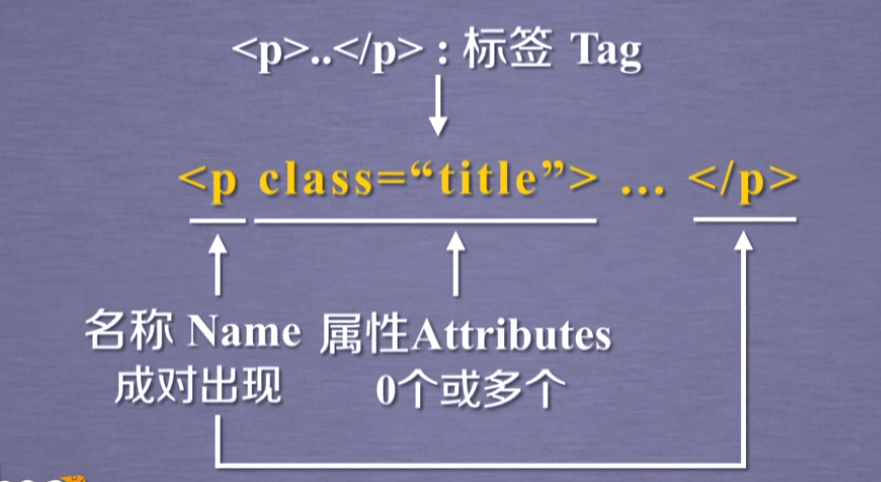

等价↑
BeautifulSoup对应一个 HTML/XML文档 的全部内容
在这里插入图片描述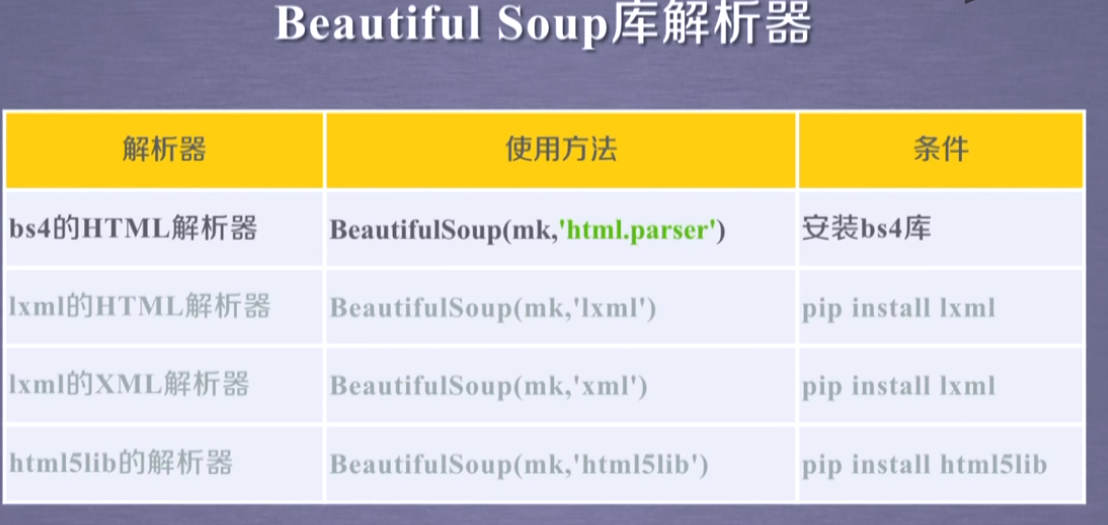

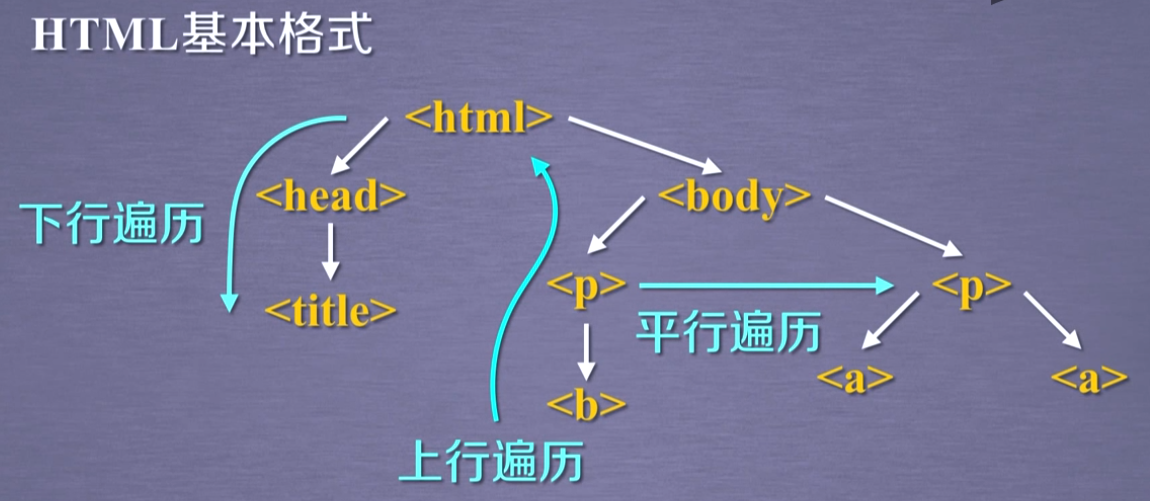

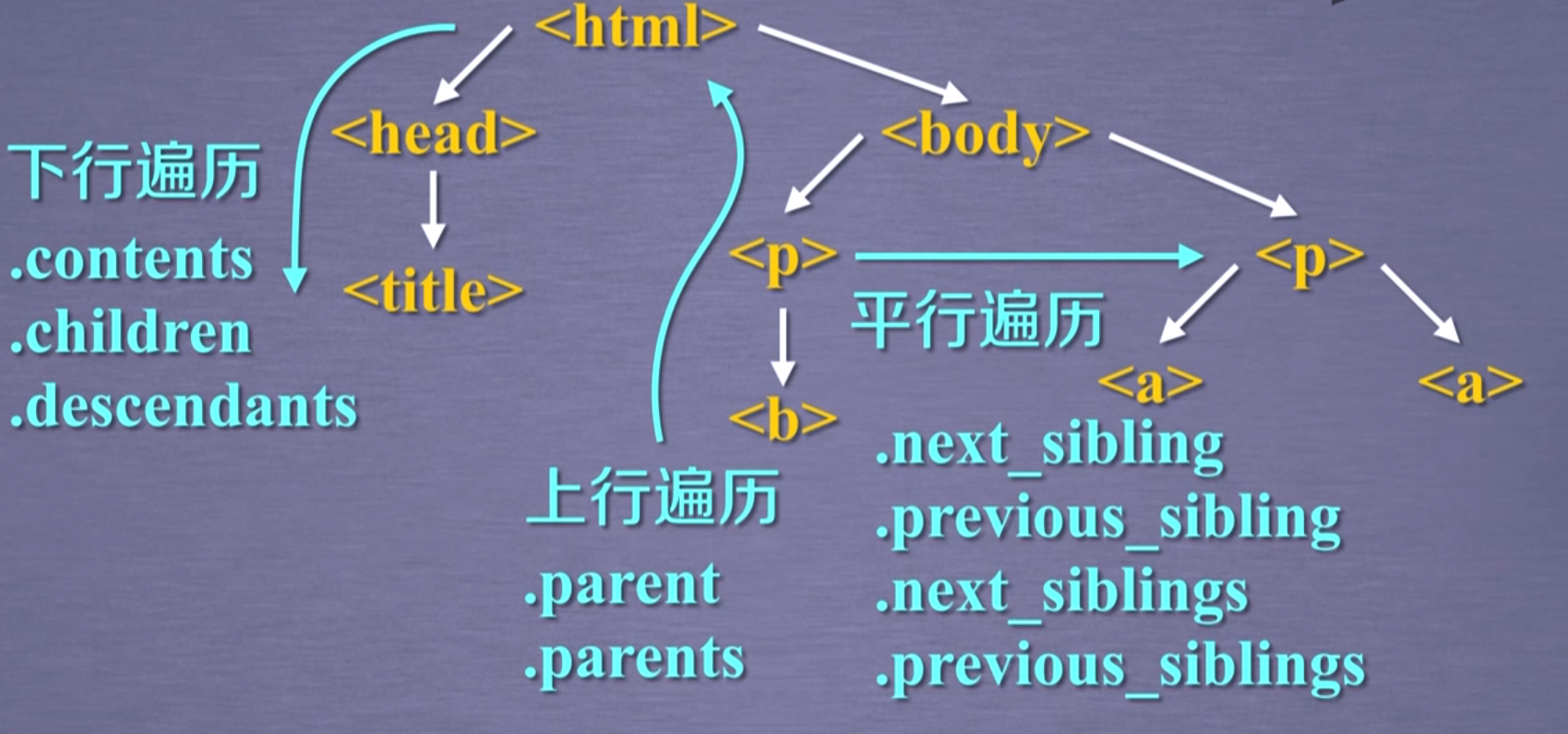
prettify

信息提取











三.Re库(正则表达式)

正则表达式:表示一组字符串的特征

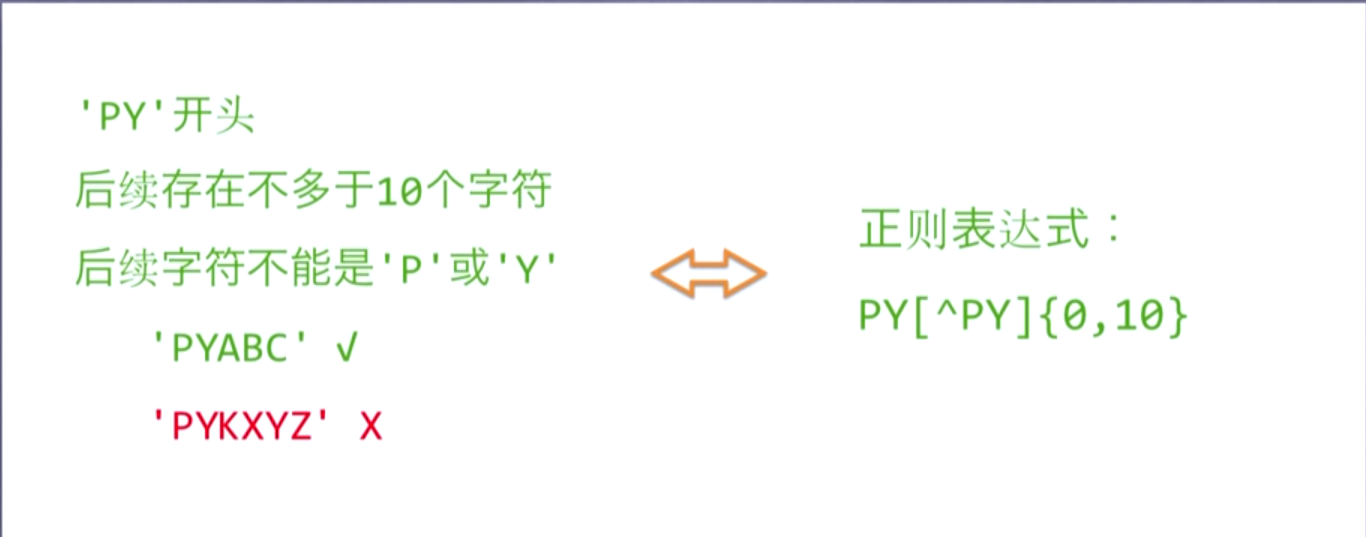


主要应用在字符串匹配中
正则表达式常用操作符
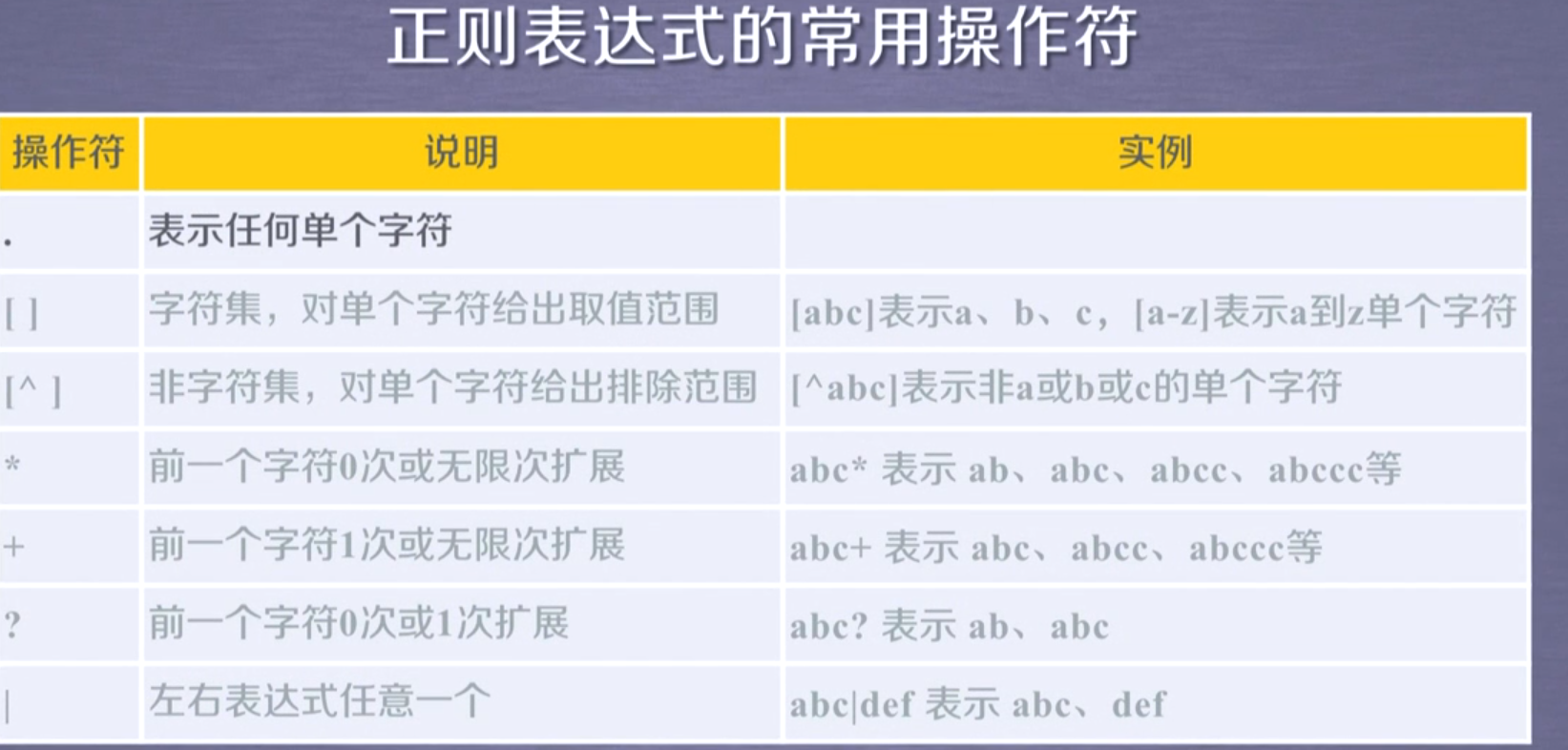
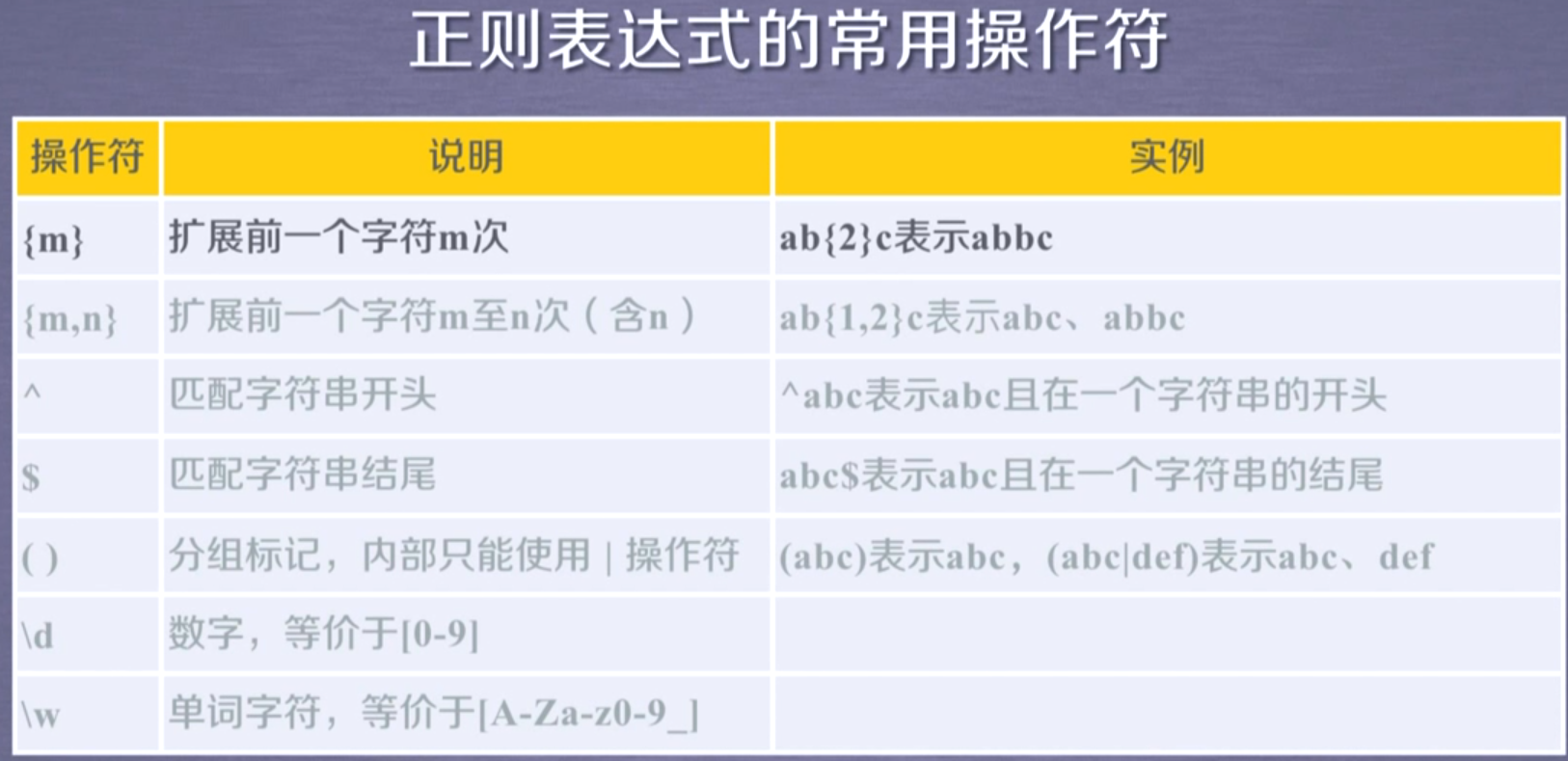

Re库


substitute 英[ˈsʌbstɪtjuːt] 美[ˈsʌbstɪtuːt]
n. 代替者; 代替物; 代用品; 替补(运动员);
v. (以…)代替; 取代;




四.Scrapy爬虫框架
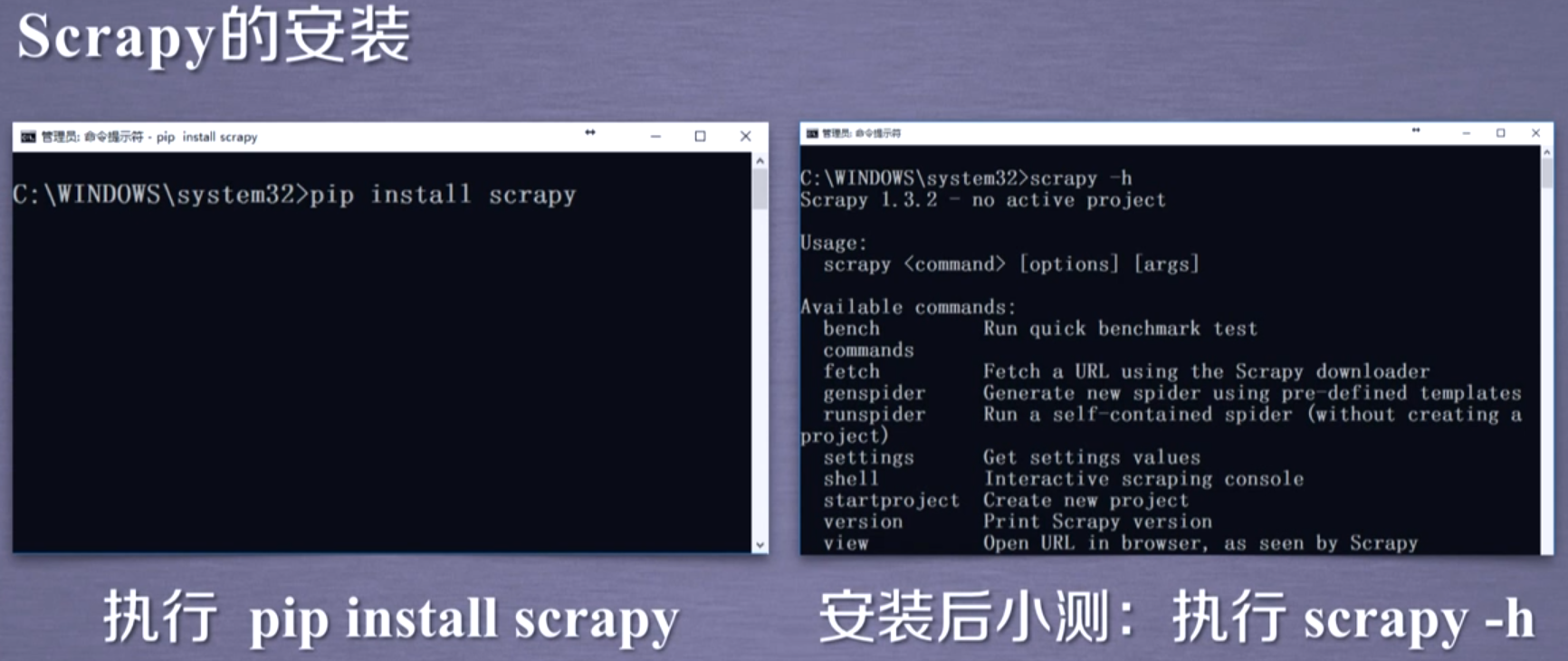

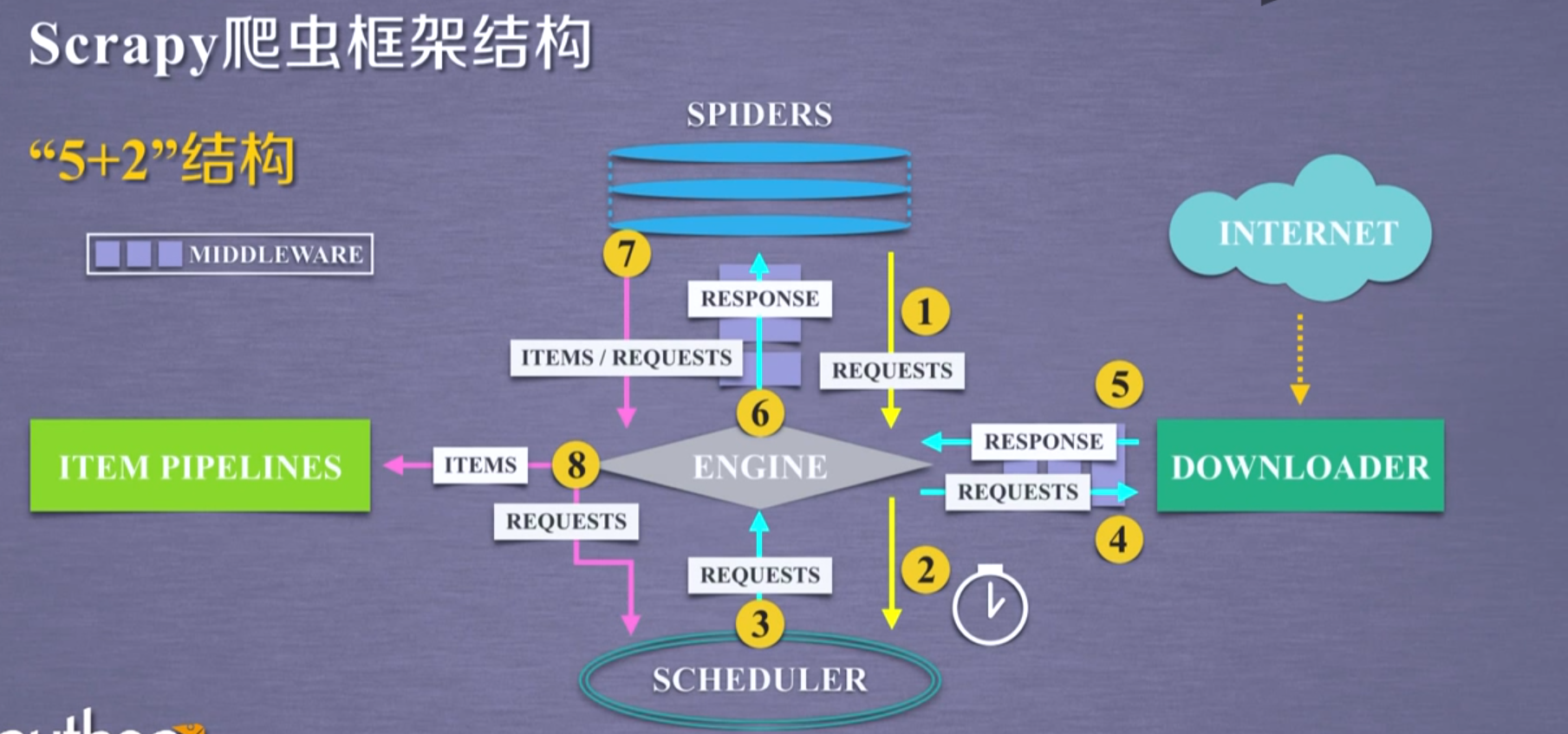
requests vs Scrapy



Scrapy爬虫常用命令


最后
以上就是单纯野狼最近收集整理的关于【学习笔记】北京理工大学-Python网络爬虫与信息提取一.Requests库二.Beautiful Soup库三.Re库(正则表达式)四.Scrapy爬虫框架的全部内容,更多相关【学习笔记】北京理工大学-Python网络爬虫与信息提取一.Requests库二.Beautiful内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复