决策树实践
目录
决策树实践
CART分类树
CART回归树
DecisionTreeClassifier() 属性介绍
模型训练
总结
CART分类树
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
# 准备数据集
iris = load_iris()
# 获取特征集和分类标识
features = iris.data
labels = iris.target
# 随机抽取33%的数据作为测试集,其余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features,
labels,
test_size=0.33,
random_state=0)
# 创建CART分类树 --默认系数是基尼
clf = DecisionTreeClassifier(criterion='gini')
# 拟合构造CART分类树
clf = clf.fit(train_features, train_labels)
# 用CART分类树做预测
test_predict = clf.predict(test_features)
# 预测结果与测试集结果作比对
score = accuracy_score(test_labels, test_predict)
print("CART分类树准确率 %.4lf" % score)CART回归树
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
from sklearn.tree import DecisionTreeRegressor
# 准备数据集(波士顿房价预测数据集)
boston = load_boston()
# 探索数据
print(boston.feature_names)
# 获取特征集和房价
features = boston.data
prices = boston.target
# 随机抽取33%的数据作为测试集,其余为训练集
train_features, test_features, train_price, test_price = train_test_split(features, prices, test_size=0.33)
# 创建CART回归树
dtr = DecisionTreeRegressor()
# 拟合构造CART回归树
dtr.fit(train_features, train_price)
# 预测测试集中的房价
predict_price = dtr.predict(test_features)
# 测试集的结果评价
print('回归树二乘偏差均值:', mean_squared_error(test_price, predict_price))
print('回归树绝对值偏差均值:', mean_absolute_error(test_price, predict_price))
DecisionTreeClassifier() 属性介绍
到目前为止,sklearn 中只实现了 ID3 与 CART 决策树,所以我们暂时只能使用这两种决策树
criterion,意为标准。它决定了构造的分类树是采用 ID3 分类树,还是 CART 分类树,对应的取值分别是 entropy 或者 gini:
entropy: 基于信息熵,也就是 ID3 算法,实际结果与 C4.5 相差不大;
gini:默认参数,基于基尼系数。CART 算法是基于基尼系数做属性划分的,所以 criterion=gini 时,实际上执行的是 CART 算法。
# 一般建议使用默认的参数,默认参数不会限制决策树的最大深度,不限制叶子节点数,认为所有分类的权重都相等等。
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')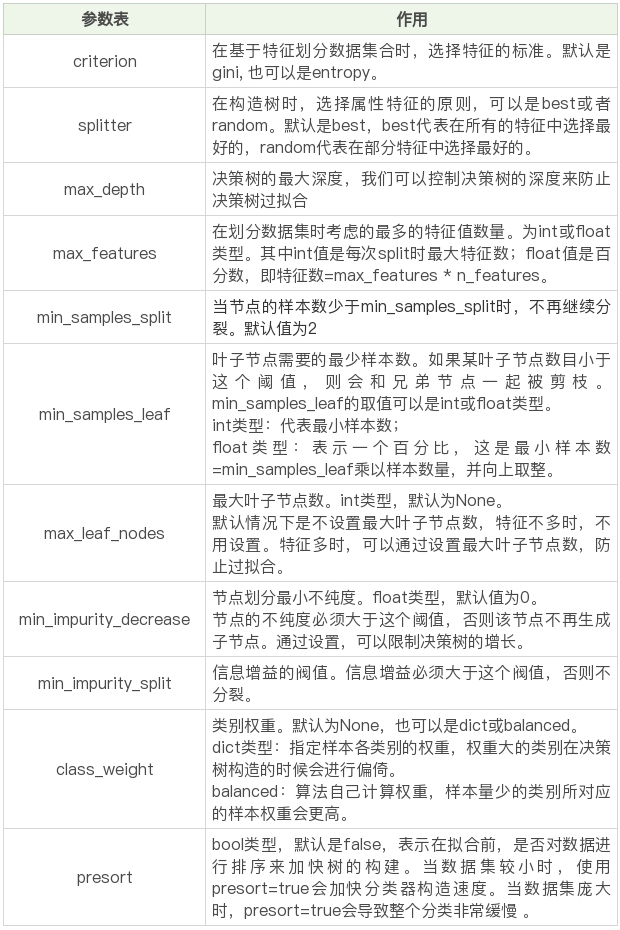
模型训练
# 对训练集进行预测可以分两个阶段 数据获取后:
1.准备阶段:数据探索,清洗数据,特征选择
2.分类阶段:建立模型,模型评估(预测),可视化
Titanic 乘客生存
预测问题描述泰坦尼克海难是著名的十大灾难之一,究竟多少人遇难,各方统计的结果不一。
现在我们可以得到部分的数据,具体数据你可以从 GitHub 上下载:https://github.com/cystanford/Titanic_Data(完整的项目代码见:https://github.com/cystanford/Titanic_Data/blob/master/titanic_analysis.py 你可以跟着学习后自己练习)
其中数据集格式为 csv,一共有两个文件:train.csv 是训练数据集,包含特征信息和存活与否的标签;test.csv: 测试数据集,只包含特征信息。
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import graphviz
import numpy as np
from sklearn.model_selection import cross_val_score
# 数据加载
train_data = pd.read_csv('./train.csv')
test_data = pd.read_csv('./test.csv')
# 数据探索
print(train_data.info())
print('-'*30)
print(train_data.describe())
print('-'*30)
print(train_data.describe(include=['O']))
print('-'*30)
print(train_data.head())
print('-'*30)
print(train_data.tail())
# 数据清洗
# 使用平均年龄来填充年龄中的 nan 值
train_data['Age'].fillna(train_data['Age'].mean(), inplace=True)
test_data['Age'].fillna(test_data['Age'].mean(),inplace=True)
# 使用票价的均值填充票价中的 nan 值
train_data['Fare'].fillna(train_data['Fare'].mean(), inplace=True)
test_data['Fare'].fillna(test_data['Fare'].mean(),inplace=True)
print(train_data['Embarked'].value_counts())
# 使用登录最多的港口来填充登录港口的 nan 值
train_data['Embarked'].fillna('S', inplace=True)
test_data['Embarked'].fillna('S',inplace=True)
# 特征选择
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
train_features = train_data[features]
train_labels = train_data['Survived']
test_features = test_data[features]
# 将符号化对象转化成 数字 0/1 进行表示
# fit_transform 这个函数,它可以将特征向量转化为特征值矩阵
dvec=DictVectorizer(sparse=False)
train_features=dvec.fit_transform(train_features.to_dict(orient='record'))
print(dvec.feature_names_)
# 构造 ID3 决策树
clf = DecisionTreeClassifier(criterion='entropy')
# 决策树训练
clf.fit(train_features, train_labels)
test_features=dvec.transform(test_features.to_dict(orient='record'))
# 决策树预测
pred_labels = clf.predict(test_features)
# 得到决策树准确率
acc_decision_tree = round(clf.score(train_features, train_labels), 6)
print(u'score 准确率为 %.4lf' % acc_decision_tree)
# 使用K折交叉验证 统计决策树准确率(cv = 分几份)
print(u'cross_val_score准确率为 %.4lf' % np.mean(cross_val_score(clf, train_features, train_labels, cv=10)))
# 决策树可视化
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.view()总结
决策树的优势是分类决策可以解释性强,速度快,分类准确率高。分类效果普遍不错,但是对异常值敏感,容易过拟合。
类似贪心算法
每次都是在当前情况下,选择最优选择,这样获得决策容易陷入局部最优和非全局最优
而且在一步步选择中,忽略了特征间的相关性
优化思路,引入随机森林:随机可以提升抗过拟合的能力,森林可以提高准确度
# 1.特征选择是分类模型好坏的关键,通常下特征值不都是数字类型,我们用 DictVectorizer 类进行转化.
# 2.模型没有测试集,可以对训练集进行k折交叉验证.
# 3.Graphviz 可视化工具可以很方便地将决策模型呈现出来,帮助你更好理解决策树的构建。
# 名词区分
# fit 从一个训练集中学习模型参数,其中就包括了归一化时用到的均值,标准偏差等,可以理解为一个训练过程。
# transform: 在fit的基础上,对数据进行标准化,降维,归一化等数据转换操作
# fit_transform: 将模型训练和转化合并到一起,训练样本先做fit,得到mean,standard deviation,然后将这些参数用于transform(归一化训练数据),使得到的训练数据是归一化的,而测试数据只需要在原先fit得到的mean,std上来做归一化就行了,所以用transform就行了。
# 为什么训练集用 fit_transform 测试集用 transform
# transform()和fit_transform()二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)。
# fit_transform(trainData)对部分训练数据先拟合fit,找到部分训练数据的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对训练数据进行转换transform,从而实现数据的标准化、归一化等等。
# 根据对之前部分训练数据进行fit的整体指标,对测试数据集使用同样的均值、方差、最大、最小值等指标进行转换transform(testData),从而保证train、test处理方式相同。
# k折交叉验证
# 使用train_test_split函数,提前拆分训练集测试集,就不需要再用k折交叉验证了
# # 如果没有测试集,可以用k折交叉验证的方式来验证准确率的
# # k折交叉验证就是做k次交叉检验,每次选取 1/k的数据作为验证,其余作为训练.轮流k次,取平均值.
# # 原理就是先分k分,先拿第一份当测试数据,其他训练数据,然后第二份,第三分最后
以上就是温婉世界最近收集整理的关于决策树实践的全部内容,更多相关决策树实践内容请搜索靠谱客的其他文章。








发表评论 取消回复