一、首先需要自己申请一个公众号
1.登陆自己的账号。
2.进入公众号后台首页,新建群发–> 自建图文
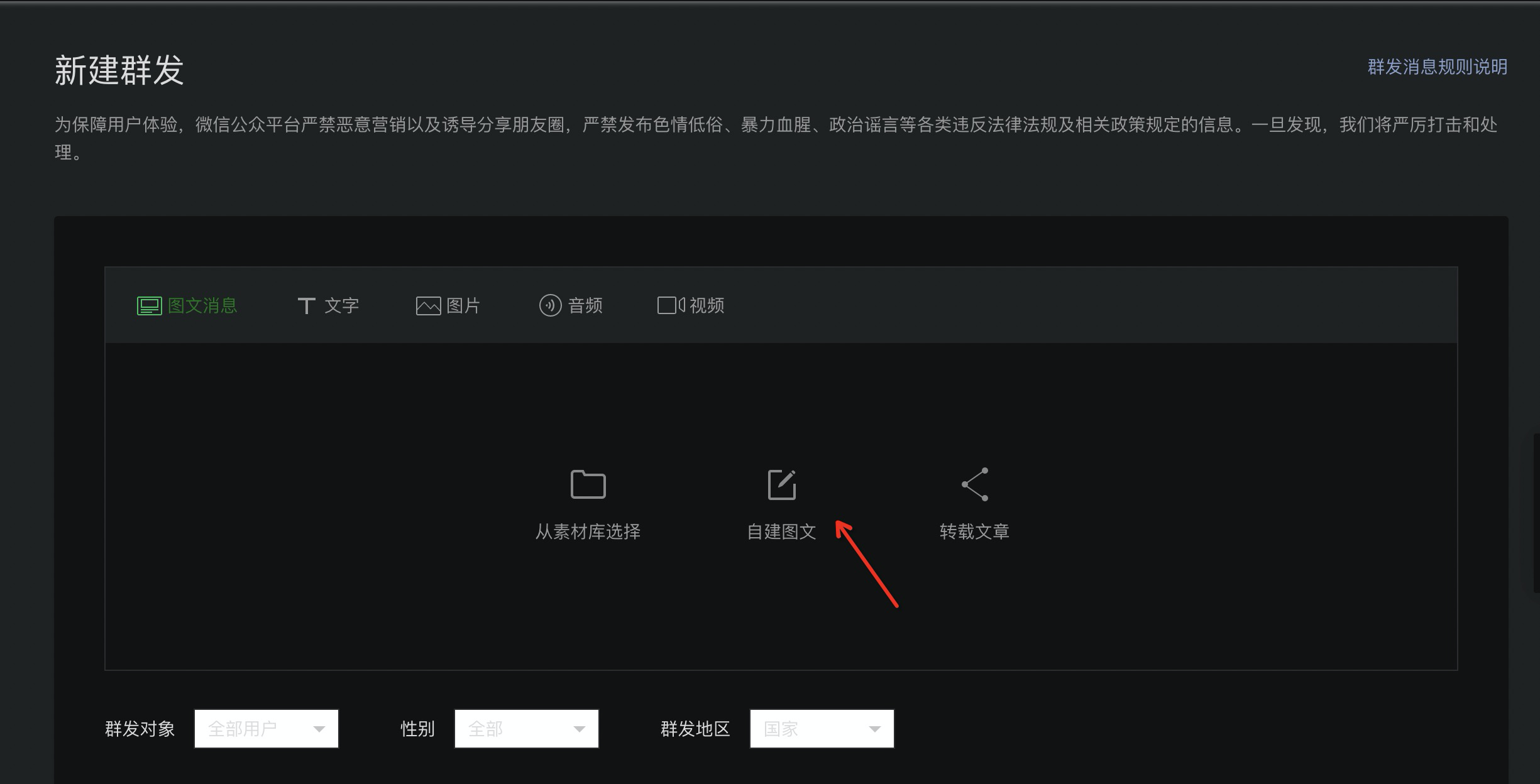
3. 点击超链接
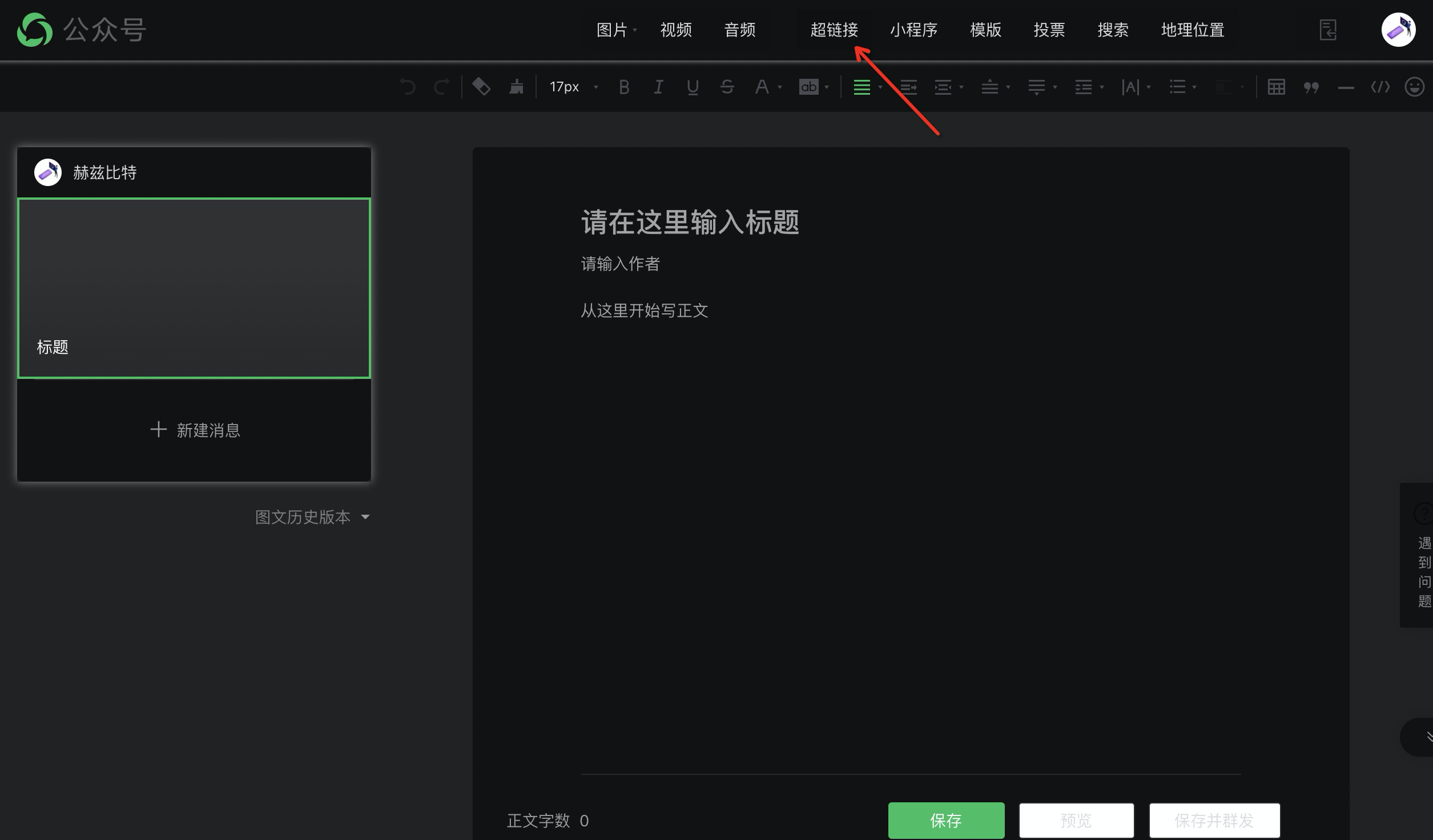
4.选择其他的公众号
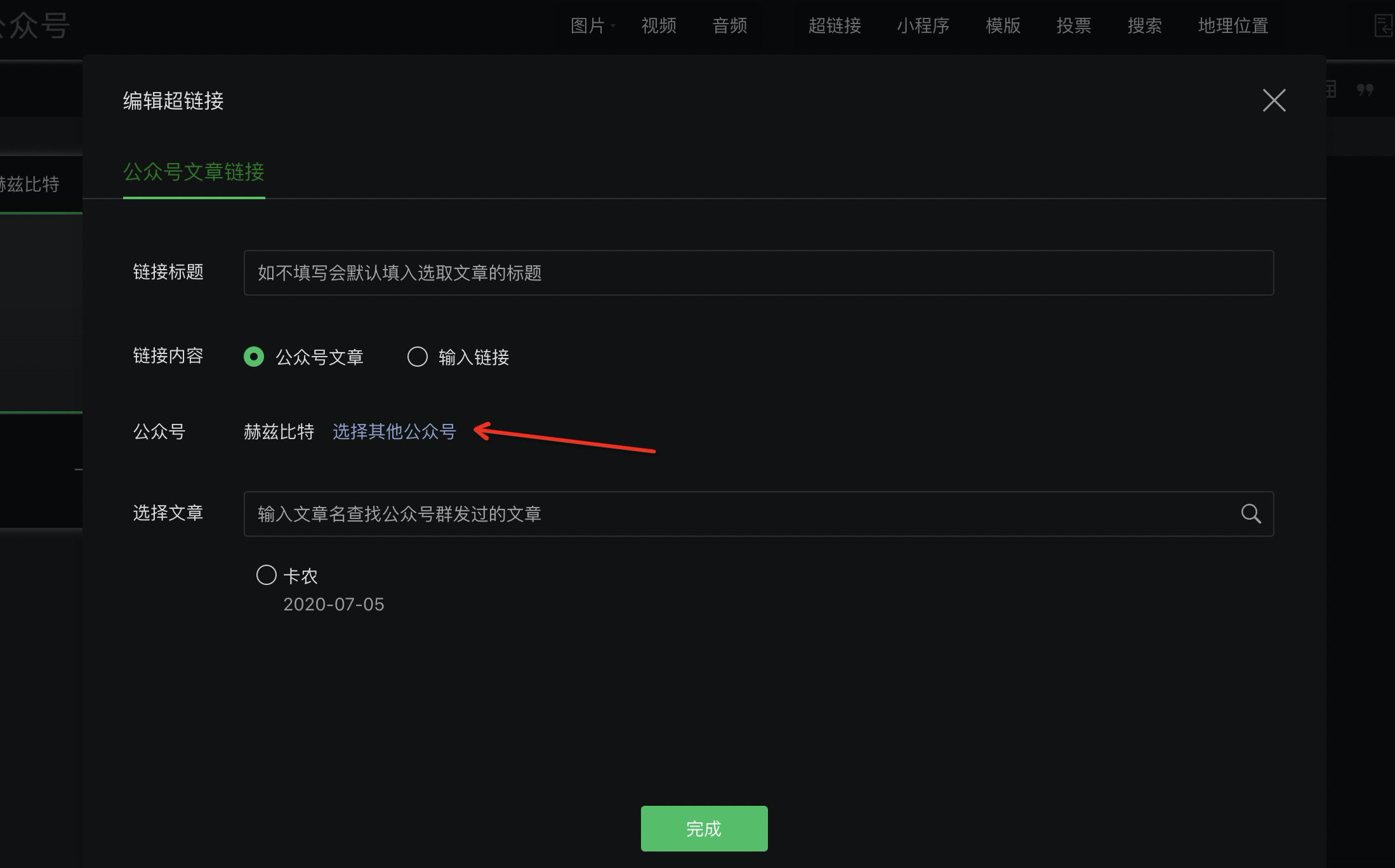
5.搜索想要爬虫的公众号
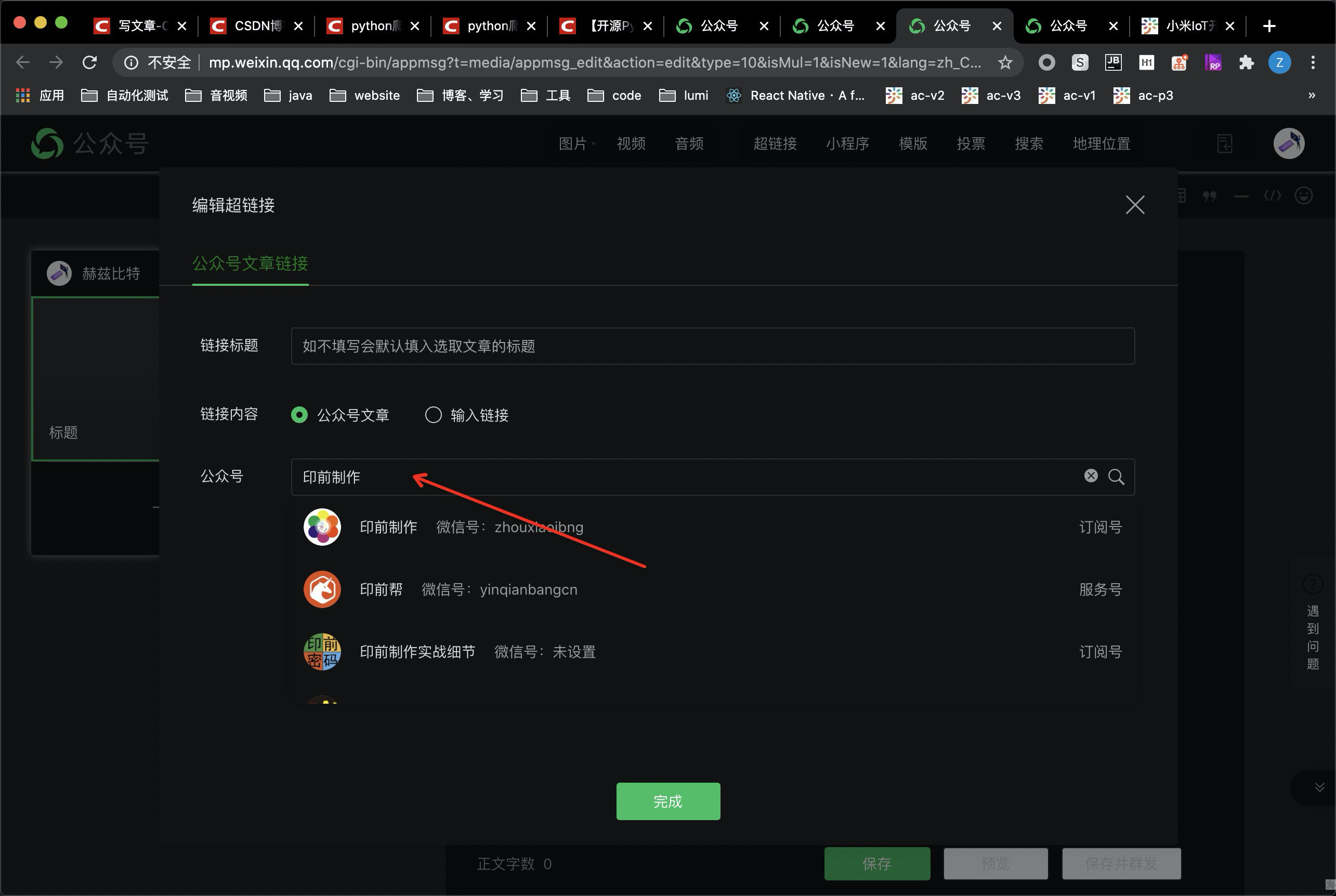
6.通过抓包获取信息,定位请求的url,
请求的参数token和cookies需要你自己申请公众号的账号来获取,下面是获取token和cookies的代码:
#遵循PEP8规则
import time
import json
import re
from selenium import webdriver
from lxml import html
# 获取cookies和token
class C_ookie:
# 初始化
def __init__(self):
self.html = ''
# 获取cookie
def get_cookie(self):
cooki = {}
url = 'https://mp.weixin.qq.com'
Browner = webdriver.Chrome()
Browner.get(url)
time.sleep(10)
# 获取账号输入框
ID = Browner.find_element_by_name('account')
# 获取密码输入框
PW = Browner.find_element_by_name('password')
# 输入账号
id = '你自己申请的公众号的账号'
pw = '你自己申请的公众号的密码'
# id = input('请输入账号:')
# pw = input('请输入密码:')
ID.send_keys(id)
PW.send_keys(pw)
# 获取登录button,点击登录
Browner.find_element_by_class_name('btn_login').click()
# 等待扫二维码
time.sleep(10)
cks = Browner.get_cookies()
for ck in cks:
cooki[ck['name']] = ck['value']
ck1 = json.dumps(cooki)
print(ck1)
with open('ck.txt','w') as f :
f.write(ck1)
f.close()
self.html = Browner.page_source
# 获取token,在页面中提取
def Token(self):
#等待页面加载
time.sleep(5)
etree = html.etree
h = etree.HTML(self.html)
url = h.xpath('//a[@title="首页"]/@href')[0]
print(url)
token = re.findall('d+',url)
tokentxt = json.dumps(token)
print(tokentxt)
with open('token.txt', 'w') as f:
f.write(tokentxt)
f.close()
C = C_ookie()
C.get_cookie()
C.Token()
7.通过抓包把文章里的视频播放链接找到,把标题和下载链接存到csv文件里
import time
import json
import random
import csv
from selenium import webdriver
from lxml import html
import requests
import re
from http import cookiejar
# 获取文章
class getEssay:
def __init__(self):
# 获取cookies
with open('ck.txt','r') as f :
cookie = f.read()
f.close()
self.cookie = json.loads(cookie)
# 获取token
self.header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": 'Mozilla / 5.0(WindowsNT6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.131Safari / 537.36'
}
m_url = 'https://mp.weixin.qq.com'
response = requests.get(url=m_url, cookies=self.cookie)
print(response);
self.token = 000000; ## 填入token.txt保存的token信息。
print(self.token)
# fakeid与name
self.fakeid = []
# 获取公众号信息
def getGname(self):
# 请求头
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&token=%d&lang=zh_CN'%int(self.token),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 地址
url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
# query = input('请输入要搜索的公众号关键字:')
# begin = int(input('请输入开始的页数:'))
query = '印前制作'
begin = 0
begin *= 5
# 请求参数
data = {
'action': 'search_biz',
'token': self.token,
'lang': 'zh_CN',
'f': 'json',
'ajax':' 1',
'random': random.random(),
'query': query,
'begin': begin,
'count': '1'
}
# 请求页面,获取数据
res = requests.get(url=url, cookies=self.cookie, headers=headers, params=data)
print(res.text);
name_js = res.text
name_js = json.loads(name_js)
list = name_js['list']
for i in list:
time.sleep(1)
fakeid = i['fakeid']
nickname =i['nickname']
print(nickname,fakeid)
self.fakeid.append((nickname,fakeid))
# 获取文章url
def getEurl(self, begin):
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&token=%d&lang=zh_CN'%int(self.token),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 遍历fakeid,访问获取文章链接
for i in self.fakeid:
time.sleep(1)
fake = i[1]
data = {
'token': self.token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': begin,
'count': 5,
'fakeid': fake,
'type': 9
}
res = requests.get(url, cookies=self.cookie, headers=headers, params=data)
js = res.text
print(js)
link_l = json.loads(js)
self.parJson(link_l)
# 解析提取url
def parJson(self,link_l):
l = link_l['app_msg_list']
for i in l:
link = i['link']
link = self.getVideo(link)
name = i['title']
self.saveData(name,link)
# 保存数据进csv中
def saveData(self,name,link):
with open('link.csv' ,'a',encoding='utf8') as f:
w = csv.writer(f)
w.writerow((name,link))
print('ok')
def getVideo(self, url):
# 请求要下载的url地址
html = requests.get(url);
# content返回的是bytes型也就是二进制的数据。
# 我用的是正则,也可以使用xpath
jsonRes = html.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
if result:
wxv = result.group(0)
print(wxv)
print(html)
# 页面播放形式
video_url = "https://mp.weixin.qq.com/mp/readtemplate?t=pages/video_player_tmpl&auto=0&vid=" + wxv
print("video_url", video_url)
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/videoplayer?action=get_mp_video_play_url&preview=0&__biz=MzU1MTg5NTQxNA==&mid=2247485507&idx=4&vid=" + wxv
response = requests.get(video_url_temp)
content = response.content.decode()
content = json.loads(content)
print(content)
url_info = content.get("url_info")
if url_info:
video_url2 = url_info[0].get("url")
print(video_url2)
return video_url2
else:
return ""
else:
return ""
if __name__ == '__main__':
G = getEssay()
G.getGname()
for num in range(0,20):
time.sleep(1)
G.getEurl(num*5)
8.批量从csv文件的链接下载视频
import sys
import you_get
import os
import csv
import requests
def download(url,filename):
video_path = filename + ".mp4"
html = requests.get(url)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
if __name__ == '__main__':
# 视频网站的地址
sFileName='link2.csv'
json = {}
with open(sFileName,newline='',encoding='UTF-8') as csvfile:
rows=csv.reader(csvfile)
for row in rows:
print(row[0]+'====='+row[1])
download(row[1],row[0])
最后
以上就是朴实奇异果最近收集整理的关于python爬虫微信公众号视频的全部内容,更多相关python爬虫微信公众号视频内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复