如果觉得这篇文章对您有所启发,欢迎关注我的公众号,我会尽可能积极和大家交流,谢谢。

opencv2.4版本中封装了可用于人脸识别的类FaceRecognizer,其对应代码在动态链接库opencv_contrib249d.dll中(我用的是opencv2.4.9版本),这个动态链接库在opencv安装目录下可以找到,要想使用FaceRecognizer,首先要保证上述动态链接库正确配置。在此关于opencv的配置问题多说几句,就是建议大家尽量使用VS2010及以上版本来配置opencv,因为在最新的opencv2.4.9版本中已经添加了对vs2010及以上版本的自动支持,无需再用CMaker进行编译了,配置简单可靠。我之前用的是VS2008版本,在自己编译opencv_contrib249d.dll这个库时总提示编译出错,如果你也遇到了这个问题,建议你换装vs2010版本吧,至于具体如何配置网上有很多教程,这里不再赘述。
FaceRecognizer这个类目前包含三种人脸识别方法:基于PCA变换的人脸识别(EigenFaceRecognizer)、基于Fisher变换的人脸识别(FisherFaceRecognizer)、基于局部二值模式的人脸识别(LBPHFaceRecognizer)。对于像我这样的人脸识别初学者,对人脸识别理论了解得不是很透彻,但并不影响对函数的使用,下面就EigenFaceRecognizer来详细的谈一下opencv人脸识别的实现。
首先简单说一下PCA变换原理。在人脸识别过程中,一般把图片看成是向量进行处理,高等数学中我们接触的一般都是二维或三维向量,向量的维数是根据组成向量的变量个数来定的,例如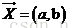 就是一个二维向量,因为其有
就是一个二维向量,因为其有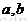 两个参量。而在将一幅图像抽象为一个向量的过程中,我们把图像的每个像素定为一维,对于一幅
两个参量。而在将一幅图像抽象为一个向量的过程中,我们把图像的每个像素定为一维,对于一幅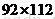 的普通图像来说,最后抽象为一个
的普通图像来说,最后抽象为一个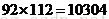 维的高维向量,如此庞大的维数对于后续图像计算式来说相当困难,因此有必要在尽可能不丢失重要信息的前提下降低图像维数,PCA就是降低图像维数的一种方法。图像在经过PCA变换之后,可以保留任意数量的对图像特征贡献较大的维数分量,也就是你可以选择降维到30维或者90维或者其他,当然最后保留的维数越多,图像丢失的信息越少,但计算越复杂。至于具体PCA变换的原理,网上有很多好的博客,也有很多专业论文来论证,有兴趣的可以查阅。
维的高维向量,如此庞大的维数对于后续图像计算式来说相当困难,因此有必要在尽可能不丢失重要信息的前提下降低图像维数,PCA就是降低图像维数的一种方法。图像在经过PCA变换之后,可以保留任意数量的对图像特征贡献较大的维数分量,也就是你可以选择降维到30维或者90维或者其他,当然最后保留的维数越多,图像丢失的信息越少,但计算越复杂。至于具体PCA变换的原理,网上有很多好的博客,也有很多专业论文来论证,有兴趣的可以查阅。
下面来谈一谈具体如何使用这个人脸识别类。首先需要一个人脸库,因为你想让计算机识别人脸,首先得让计算机知道不同的人长什么样不同的脸。网上有很多现成的人脸数据库,我在做实验时选用了ORL数据库。数据库中包含40个人的人脸图像,每人十张,共400张,有bmp和png两种格式,大小均为。数据库中有光照变化(中心光照、左侧光照、右侧光照)、表情变化(开心、正常、悲伤、瞌睡、惊讶、眨眼)、眼镜(戴眼镜或者没戴),且包含男性图片和女性图片,比较适合做人脸识别的仿真实验。唯一的不足就是照片中全部为外国人,如果你想开发出一套人脸识别系统在国内用,建议还是费点功夫自己建一个合适的人脸数据库吧。
人脸库确定之后需要进行训练,即让计算机“学习”这些人脸样本。这时面临的一个问题就是如何把训练样本读进内存中。opencv手册中明确说明EigenFaceRecognizer的训练函数的入口参数是一个图像容器,容器中包含所有训练图像。那么如何创建一个这样的容器并把训练样本全部放进去呢?方法有很多,我在实验中采用CSV文件读取方法。首先创建一个包含所有文件路径名的CSV文件,也就是一个文本文件。假设ORL数据库存放地址为:“E:ORL”;在DOS窗口下输入命令:E:ORL>dir /b/s *.bmp > at.txt,执行成功后发现在ORL文件夹下出现一个文本文件at.txt,里面内容如下(分号后面的标签是人为添加的):
E:ORLs11.bmp;1
E:ORLs110.bmp;1
E:ORLs12.bmp;1
E:ORLs13.bmp;1
E:ORLs14.bmp;1
E:ORLs15.bmp;1
E:ORLs16.bmp;1
E:ORLs17.bmp;1
E:ORLs18.bmp;1
E:ORLs19.bmp;1
E:ORLs101.bmp;10
E:ORLs1010.bmp;10
E:ORLs102.bmp;10
E:ORLs103.bmp;10
E:ORLs104.bmp;10
E:ORLs105.bmp;10
E:ORLs106.bmp;10
E:ORLs107.bmp;10
E:ORLs108.bmp;10
E:ORLs109.bmp;10
CSV文件创建成功后,可以在程序中读取文件了,网上有一段比较好的CSV读取代码,如下所示:
void read_csv(const string& filename, vector<Mat>& images, vector<int>& labels, char separator =';')
{
std::ifstream file(filename.c_str(), ifstream::in);//c_str()函数可用可不用,无需返回一个标准C类型的字符串
if (!file) {
string error_message ="No valid input file was given, please check the given filename.";
CV_Error(CV_StsBadArg, error_message);
}
string line, path, classlabel;
while (getline(file,line))//从文本文件中读取一行字符,未指定限定符默认限定符为“/n”
{
stringstream liness(line);//这里采用stringstream主要作用是做字符串的分割
getline(liness, path, separator);//读入图片文件路径以分好作为限定符
getline(liness, classlabel);//读入图片标签,默认限定符
if(!path.empty()&&!classlabel.empty())//如果读取成功,则将图片和对应标签压入对应容器中
{
images.push_back(imread(path, 0));
labels.push_back(atoi(classlabel.c_str()));
}
}
}
这段代码涉及C++中有关输入输出流iosream的相关知识,这里不作过多描述,如果需要的话可另写一篇文章来专门谈谈void read_csv()这个函数,需要说明的一点是:在使用这个函数的时候必须包含以下几个头文件:
#include <iostream>
#include <fstream>
#include <sstream>
在完成训练数据读取之后就可以真正开始数据训练过程了,首先创建一个图像容器和标签容器来存储训练图像以及对应人脸标签,然后调用void read_csv()填充这两个容器,代码如下:
string fn_csv = "E:\ORL\at.txt";//读取你的CSV文件路径.
vector<Mat> images;// 2个容器来存放图像数据和对应的标签
vector<int> labels;
read_csv(fn_csv, images, labels);//从csv文件中批量读取训练数据
然后创建一个PCA人脸分类器,暂时命名为model吧,创建完成后,调用其中的成员函数train()来完成分类器的训练,代码如下:
Ptr<FaceRecognizer> model = createEigenFaceRecognizer();
model->train(images, labels);
注意,通过createEigenFaceRecognizer()函数来创建分类器时是可以人为指定训练结果的维数以及判别阈值,这里我们采用系统默认的参数。train()函数的执行时间与训练样本图片数目有关,训练ORL的400张图片大约需要一分钟,因此为了避免每次识别时都进行训练,推荐把训练得到的分类器model用save()函数保存成XML文件存储下来,下次用的时候直接用laod()加载就行,具体如下:
model->save("E:\ORL_PCAModel.xml");//保存路径可自己设置,但注意用“\”
训练完成之后开始对新输入的图片进行识别,主要使用成员函数predict()来进行识别。注意predict()入口参数必须为单通道灰度图像,如果图像类型不符,需要先进行转换,predict()函数返回一个整形变量作为识别标签,代码如下:
model->load("E:\ORL\ORL_PCAModel.xml");//加载分类器
Mat testSample = imread("E:\2.bmp",CV_LOAD_IMAGE_GRAYSCALE);//读入人脸图片
int predictedLabel = model->predict(testSample);
函数运行完之后变量predictedLabel中存储了识别结果,整个人脸识别过程完成。
需要注意的一点是:EigenFaceRecognizer在完成人脸识别后,还可以输出一些与训练集相关的结构,比如训练集的均值特征脸、重构特征脸等,不过这些与人脸识别的结果没有太大关系,在这里不作赘述。
前面提到过,FaceRecognizer这个类除了支持PCA方法的人脸识别外,还支持另外两种方法,即Fisher变换和局部二值化模式,它们之间的用法大同小异,都是调用一些API函数,对原理不是很了解也没关系,有关代码我已经上传到网上,当然如果大家需要的话可以在评论中注明。
最后需要说明的一点,opencv中封装的这几个方法并不是单纯的为人脸识别服务的,同时人脸识别也不止有这几种方法。这几个函数本质上可以看成模式分类方法,即分类器。图像处理的很多问题最后都可以归结为分类问题,比如性别识别、警觉度识别、美丽度识别等等,人脸识别只是一个应用实例而已,大家不要被局限住,这是一个工具,一个可以用来解决很多分类问题的工具,有感兴趣的欢迎大家加群51701853一起讨论。
最后
以上就是轻松高山最近收集整理的关于浅谈Openv中人脸识别类FaceRecognizer的全部内容,更多相关浅谈Openv中人脸识别类FaceRecognizer内容请搜索靠谱客的其他文章。








发表评论 取消回复