一 Spark MLlib
数据挖掘=机器学习+数据库环境
Spark MLlib是基于海量数据的机器学习算法库,提供了分类、回归、聚类、协同过滤、降维等功能
包:spark.ml 基于的是DataFrame的数据抽象
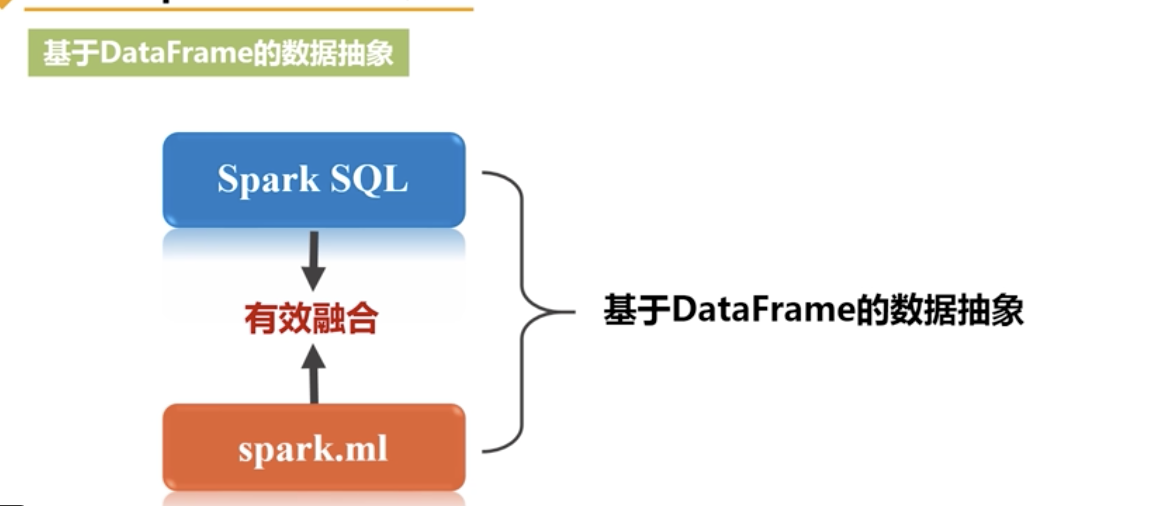
二 Spark MLlib的机器学习流水线
1 transformer: 即训练得到的模型,通过transformer对数据进行预测
方法: transform(DataFrame)
2 Estimator:即算法
方法:fit()方法进行模型训练
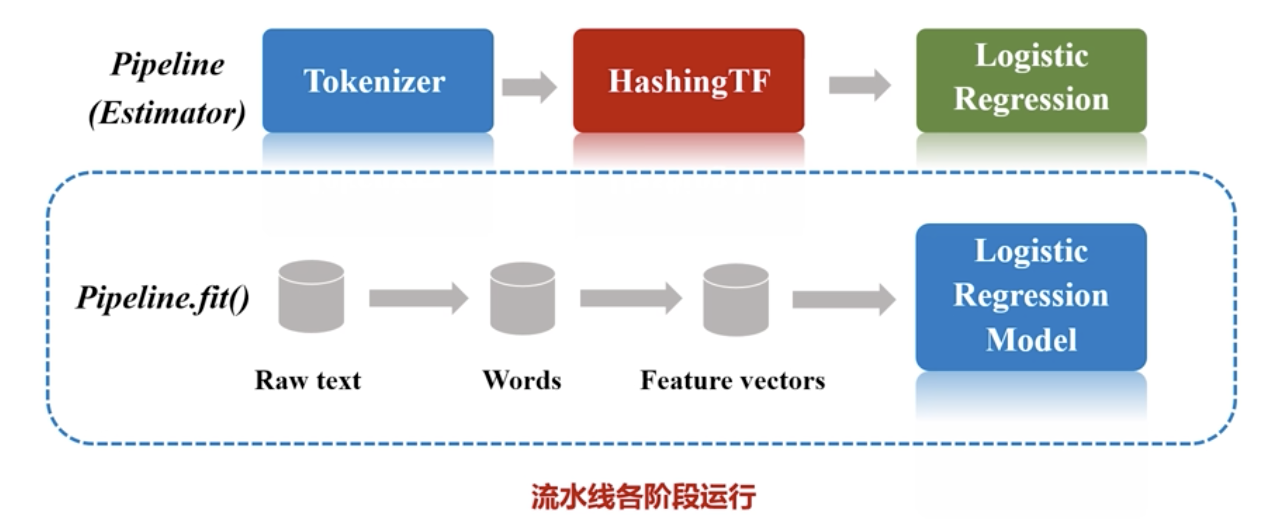
Notice:DataFrame通过Estimator得到transformer,即通过训练得到模型构建pipeline流水线:
定义Pipeline中各个流水线阶段PipelineStage(Estimator,Transformer):
val pipeline=new Pipeline().setStage(Array(stage1,stage2,stage3,...))
三 特征抽取、转化和选择
以进行TF-IDF为例:
import org.apache.spark.ml.feature.{HashingTF,IDF,Tokenizer}
import spark.implicits._ 开启RDD的隐式转换
# 创建一个DataFrame
val sentenceData = spark.createDataFrame(Seq(
(0,"I heard about Spark and I love Spark"),
(0,"I wish Java could user case classes"),
(1,"Logistic regression models are neat")
)).toDF("label","sentence")
#以下进行transform操作后,原来的DataFrame的列宽是不断增加的
# 使用tokenizer对句子进行分词
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordData = tokenizer.transform(sentenceData)
# 分词后进行特征提取
val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(2000)
val featurizedData = hashingTF.transform(wordData)
# 使用IDF对单纯的词频特征向量进行修正
val idf=new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel= idf.fit(featurizedData)
#进行模型训练
val rescaledData = idfModel.transform(featurizedData)
rescaledData.select("features","label").take(3).foreach(println)四 分类与回归
# logistic regression
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.linalg.{Vector,Vectors}
import org.apache.spark.ml.evaluation.MuticlassClassificatinoEvaluator
import org.apache.spark.ml.{Pipeline,PipelineModel}
import org.apache.spark.ml.feature.{IndexToString,StringIndexer,VectorIndexer,HashingTF,Tokenizer}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.classification.LogisticRegressionModel
import org.apache.spark.ml.classification.{BinaryLogisticRegressionSummary,LogisticRegression}
import org.apache.spark.sql.functions;
import spark.implicits._
case class Iris(features:org.apache.spark.ml.linalg.Vector,label:String)
val data=spark.sparkContext.textFile("file:///usr/local/spark/iris.txt").map(_.split(",")).map(p=>Iris(Vectors.dense(p(0).toDOuble,p(1).toDouble,p(2).toDouble)))
val df=spark.sql("select * from iris where label!='Iris-setosa'")
df.map(t=>t(1)+":"+t(0)).collect()/foreach(println)
# 标签数值化
val lableIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexdLabel").fit(df)
val featureIndexer = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").fit(df)
# 数据集split
val Array(trainingData,testData)=df.randomSplit(Array(0.7,0.3))
# 设置logistic的参数
val lr=new LogisticRegression().setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures").setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8)
# 设置labelConverter,把预测类别重新转化成字符型
val labelConverter = new IndexToString().setInputCol("prediction").setOutputCol('predictedLabel').setLabels(labelIndexer.labels)
# 构建pipeline,设置stage, 调用fit()来训练模型
val lrPipeline = new Pipeline().setStages(Array(labelIndexer,featureIndexer,lr,labelConverter))
val lrPipelineModel=lrPipeline.fit(trainingData)
# 进行模型预测
val lrPredictions = lrPipelineModel.transform(testData)
# 输出预测的结果
lrPredictions.select("predictedLabel","label","features","probability").collect().foreach{case ....}
# 模型评估
val evaluator = new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction")
val lrAccuracy = evaluator.evaluate(lrPredictions)
println("Test Error="+(1.0-lrAccuracy))
# 获取模型参数
val lrModel=lrPipelineModel.stages(2).asInstanceOf[LogisticRegressionModel]
println("Coefficients:"+lrModel.coefficients+
"Intercept:"+lrModel.intercept+"numClasses:"+lrModel.numClasses+"numFeatures:"+lrModel.numFeatures)
最后
以上就是稳重宝马最近收集整理的关于Spark(六) Spark MLlib的全部内容,更多相关Spark(六)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复