本此博客也是本人和沐晟906完成的第一篇文章,有写得不好的地方希望大家多多指点!
废话不多说直接上干货;本文主要讲解几个部分,(适合一些在读的研究生啥也不会然后接到一些项目无从下手,如果是大佬的话就可以跳过了)先看看网络摄像头的效果吧(在2060的电脑上运行 )
网络摄像头
(1)yolov5的训练
(2)yolov5的界面开发(Pyqt5)
(3)将整个项目打包成EXE
一.yolov5的训练:
很多做深度学习的伙伴肯定有跑过一些网上的目标检测开源项目,比如yolo系列,我跑过YOLOv4(VS编译进行对于我这个小白来说比较麻烦),还是YOLOv5使用pycharm在pytorch的环境下进行训练、测试,之类的(此内容只针对小白);
先从搭建环境开始,首先你要去官网下载anaconda点击此处进入下载教程,就当你已经下载好anaconda了,然后你要下载一个编译器pycharm(简单的来说就是你编写python代码的一个APP),编译器有了现在就要创建一个虚拟环境了(通过anaconda创建一个虚拟环境,在这个环境里面你可以下载很多库模块,比如python—opencv,torch,tensorflow,Pyqt之类的第三方库你才能运行你的深度学习或者你的界面开发)
如果你是做深度学习的话肯定有一个不错的GPU,我是下载的GPU版本的torch,所以都是以我自身的计算机能力下载相关配置:
# 创建(建议下载3.7我也不是很清楚)
conda create -n env_name python=x.x
#如果你要创建pytorch环境你可以如下操作(名字可以自己选择)
conda create -n pytorch python=3.7
# 删除
conda remove -n env_name --all
创建完虚拟环境后你可以在你的anaconda目录下面找到你创建的环境如下图所示:
环境创好了、编译器也下载好了,大家伙不要着急!马上就要去下载YOLOv5的源码(这里面有一个巨大的坑困扰了我几天后面会告诉大家)
直接去GitHub官网下载点击此处下载YOLOV5源码

大家可以看到有很多不同的版本,就是在这里困扰了我很久,我自己下载的是V3.0版本的,但是有一个博主的界面设计使用的源码是V4.0,导致后面加载权重死活加载不出来,界面崩溃;所以大家做界面开发一定要用自己的或者跟博主的一样,好了建议你下载V4.0因为我是4.0版本的如果出现什么问题还可以讨论一下,
点击右上角的Code,Download就可以了,然后解压到自己的电脑如下:
好了!源码下载好了之后,开始安装YOLOv5需要的库,大家打开根目录可以看到有一个requirements.txt如下:

开始安装上面的一些库,win+r输入cmd进入终端激活你刚刚创建的环境(因为你以后要使用这个环境把所以的第三方库下进去就完事了)
#激活环境(你自己的环境)
activate pytorch激活之后就会出现:
![]() 此时你已经进入了环境就可以下载了。
此时你已经进入了环境就可以下载了。
如果你要执行pip install -r requirements.txt,你需要进入源码根目录在路径输入cmd如下:
进入终端后直接输入:(torch,和torchvision先不下载)
pip install -r requirements.txt
#一般情况下都不会成功反正我是这样的所以我是一个一个下载的
#这里忘了告诉大家pip下载是访问外网进行下载所以速度非常慢,加入国内镜像源下载如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib>=3.2.2(默认下载最新版本)
就这样一个一个的下载很笨的方法,gpu-torch官网上可以下载但是对于小白来说很容易失败,或者根本下载不了非常慢,所以我把我的gpu-torch发给大家,

我的CUDA版本是11.1(至于cuda是什么我也不解释了自己百度一下就知道了),我会把CUDA、CUDNN、torch,这一套都放在百度网盘:
链接:https://pan.baidu.com/s/15GASd44zuYZXDhrR-bnzbA
提取码:7eit
CUDA的安装大家可以看一下其他教程,cuda一定要安装在C盘默认位置记住这个位置,
![]() 左图是CUDNN这个很难下载在官网,大家直接在我的网盘里面下载完之后把几个文件夹里面的东西拷贝到CUDA的对应文件夹即可,系统变量一般在安装时会自动添加。这里你的CUDA就安装成功了。
左图是CUDNN这个很难下载在官网,大家直接在我的网盘里面下载完之后把几个文件夹里面的东西拷贝到CUDA的对应文件夹即可,系统变量一般在安装时会自动添加。这里你的CUDA就安装成功了。
下一步安装torch(这个东西在官网下载非常的慢所以用我的梯子)
大家把torch-1.8.0+cu111-cp37-cp37m-win_amd64.whl和另一个torchvision-0.9.0+cu111-cp37-cp37m-win_amd64.whl解压到你刚刚创建的环境里面,解压好之后在路径输入CMD进入终端,进入终端后:
pip install torch-1.8.0+cu111-cp37-cp37m-win_amd64.whl
pip install torchvision-0.9.0+cu111-cp37-cp37m-win_amd64.whl等待几分钟就会下载好,在你的:
这里面基本都是你以后下载的所以三方库!可以测试一下你的gpu-torch是否可以调用:
#进入你的环境
activate pytorch
#输入
python
import torch
torch.cuda.is_available()
#如果输出的结果是
Ture(表示你安装成功了)如果没什么大问题我们就可以直接进入pycharm运行yolov5代码试一试!(一般都会有错误)
(大家也可以去其他地方下载合适的cuda和torch点击此处)
废话不多说让我们进入pycharm吧, 双击它第一次会有一点慢稍微等待一下!
双击它第一次会有一点慢稍微等待一下!
点击file-open打开项目点击我们刚刚下载的YOLOv5源码的文件:
大家像这种都保存在英文路径下。导入我们刚刚的环境点击file-setting-projict-python编译器-点击设置就进入到此界面,然后点击conda-environment
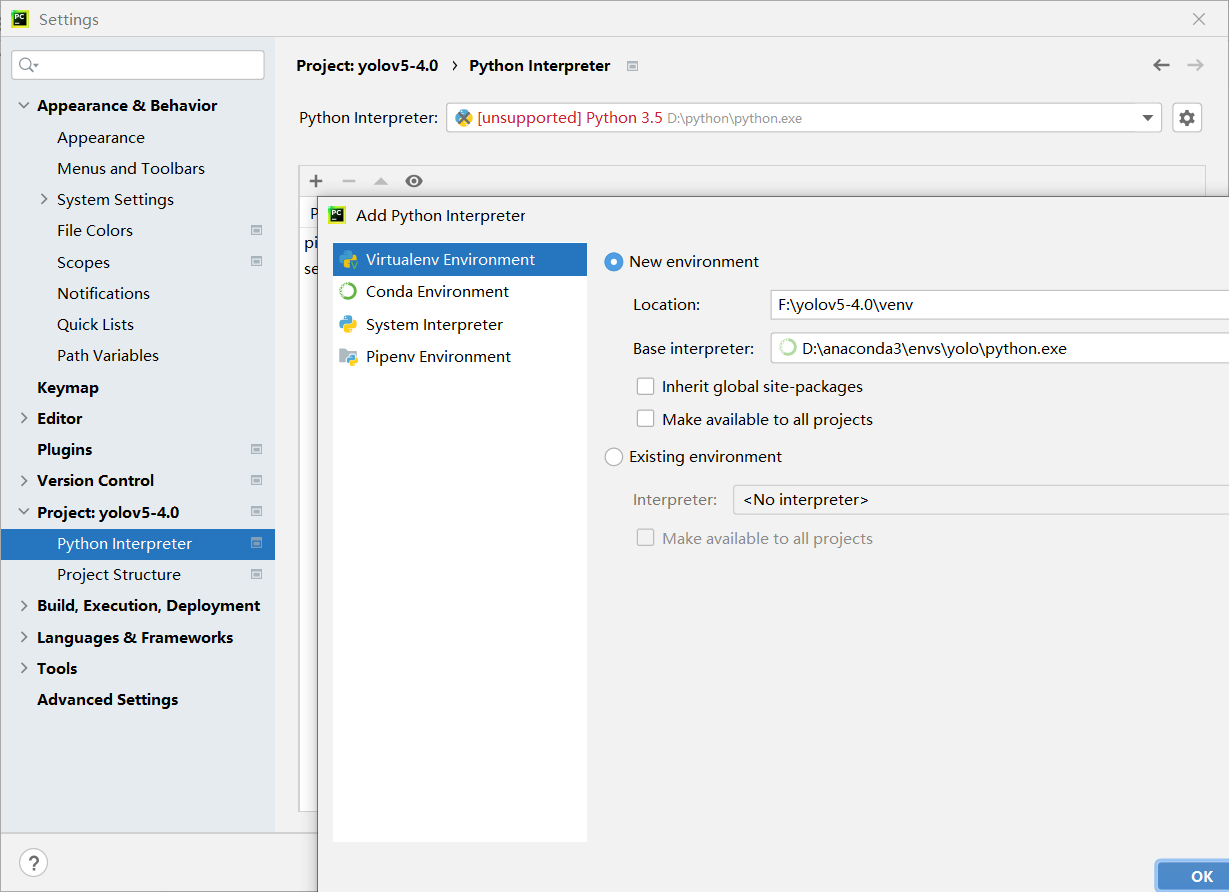
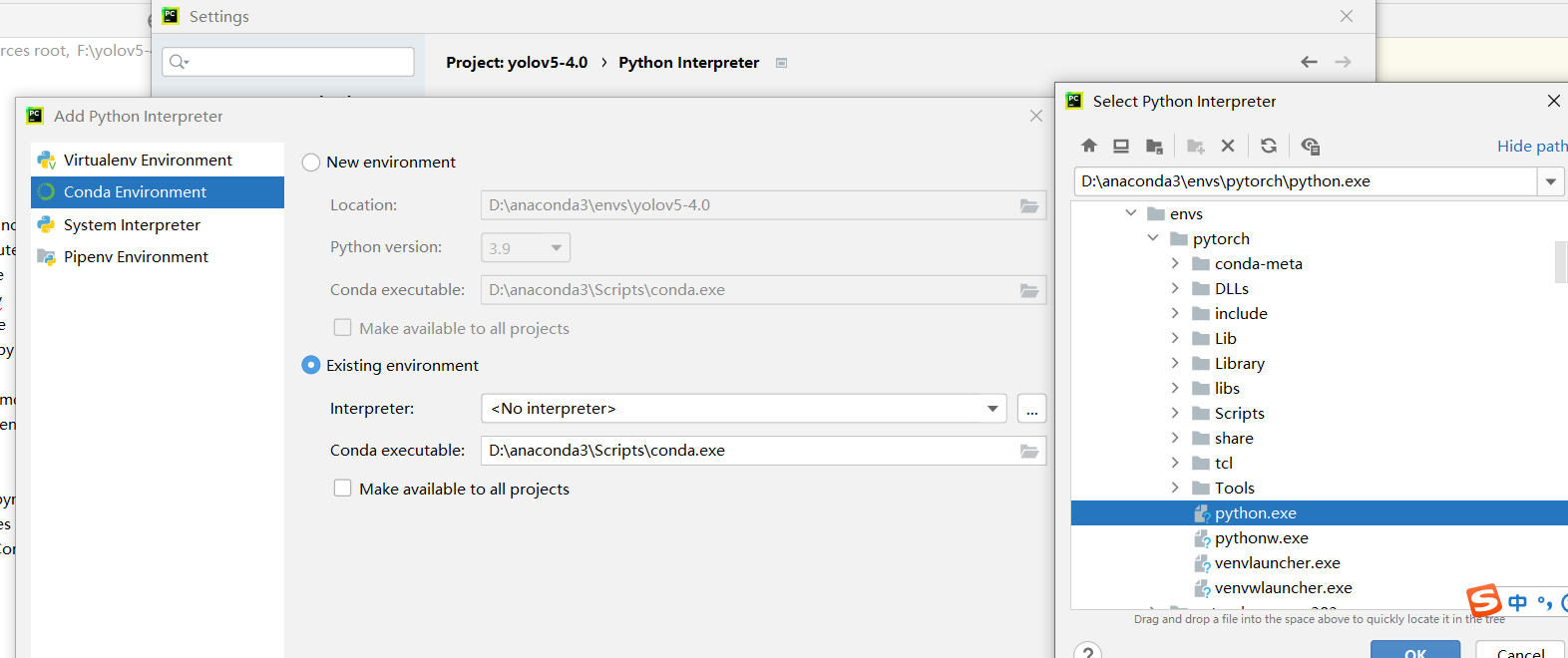
等待几分钟让他配置环境。完成之后就可以进行测试了,运行detect.py,设置device=0
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')好的在意料之中:报错了,没有YOLOV5S.pt权重文件,大家可以在网上下载V4.0的。

下载好你的权重文件放在根目录,如果没有问题的话就像下面这样:
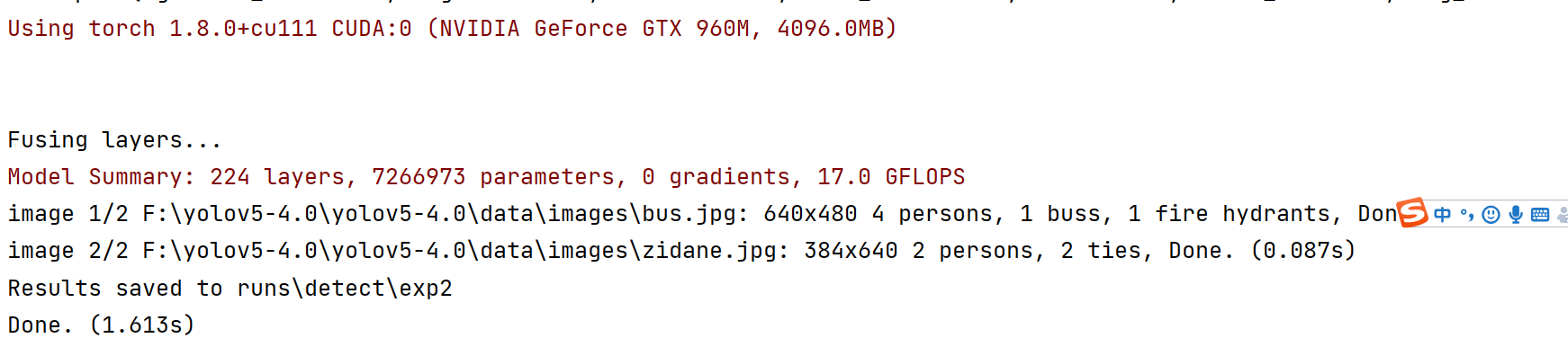
恭喜你你已经入门了!(关于如何训练自己的权重文件网上有很多教程直接进入下一个板块)
二.如何为YOLOv5设计界面
首先你要学习一下Pyqt5,算了反正看我的文章应该都不想看,先安装三方库吧:
pip install Pyqt5我给大家说一下最基本的可以用到的控件(如果你是真的想要学习必须自己进行设计,千万不要搞别人的源代码跑一下就完事了),
首先要搞清楚界面设计我们需要yolov5源码的哪一部分结合界面进行检测;
我们需要两部分一部分是模型参数加载:
def model_init(self):
# 模型相关参数配置
parser = argparse.ArgumentParser()#best1.pt效果最好
parser.add_argument('--weights', nargs='+', type=str, default='weights/best1.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
self.opt = parser.parse_args()
print(self.opt)
# 默认使用opt中的设置(权重等)来对模型进行初始化
source, weights, view_img, save_txt, imgsz = self.opt.source, self.opt.weights, self.opt.view_img, self.opt.save_txt, self.opt.img_size
# 若openfile_name_model不为空,则使用此权重进行初始化
if self.openfile_name_model:
weights = self.openfile_name_model
print("Using button choose model")
# self.device = select_device(self.opt.device)
self.device = torch.device('cuda:0')
self.half = self.device.type != 'cpu' # half precision only supported on CUDA
cudnn.benchmark = True
# Load model
self.model = attempt_load(weights, map_location=self.device) # load FP32 model
stride = int(self.model.stride.max()) # model stride
self.imgsz = check_img_size(imgsz, s=stride) # check img_size
if self.half:
self.model.half() # to FP16
# Get names and colors
self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.names
self.colors = [[random.randint(0, 255) for _ in range(3)] for _ in self.names]
print("model initial done")这里大家可以看到我没有使用self.opt.device,而是直接使用torch.device进行选择GPU,因为大佬说使用上面的进行打包会不成功;
另一部分是检测(包括图片归一化、模型加载、绘制):
def detect(self):
t0 = time.time()
img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img
_ = model(img.half() if half else img) if device.type != 'cpu' else None # run once
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f'{n} {names[int(c)]}s, ' # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + 'n')
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
有了这两个部分就可以进行检测了,但是要找到检测的结果图片,对检测后的图片进行显示;
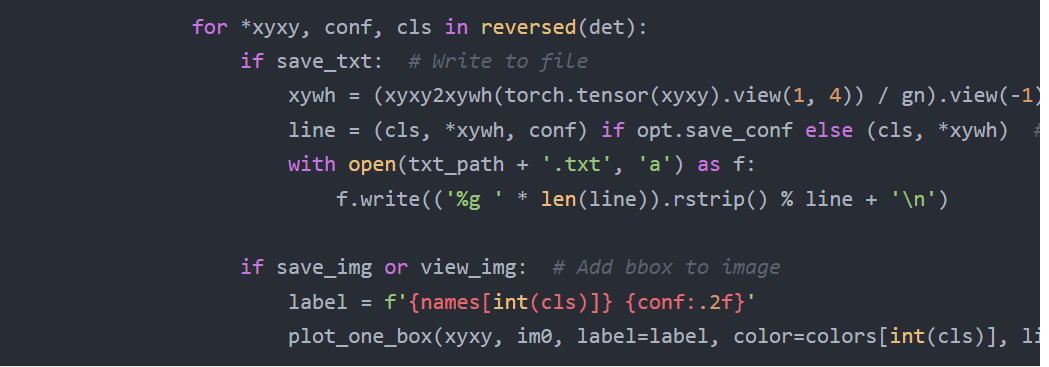
这里是对检测到的物体进行绘制,所以你需要想办法将图片传入此函数进行检测,检测完之后再进行传出来显示,比如:
def detect(self,image)
pass
def show_video(self)
这里的image可以是摄像头,图片,视频,网络摄像头
比如使用opencv
num = 0
self.cap = cv2.VideoCapture(camera_num)
image = self.cap.read()
a = self.detect(image)
对这里的image进行处理显示检测完之后可以通过pyqt界面进行显示,
重点来了!
很多小伙伴想要使用网络摄像头进行项目的开发,需要考虑实时的问题,很多作者都没有考虑这个问题,所以我想告诉大家的是要想做项目开发,很多大佬都说python多线程是假的(伪线程),但是亲测多线程可以解决这个网络摄像头延迟问题,如果不使用多线程界面会卡死,因为网络摄像头下载到缓冲区的速度大于你的读取速度或者处理速度,他就会非常卡;打个比方:
使用opencv的videocapture进行抓取摄像头是没20ms读取一帧到缓冲区,在通过cap.read()从缓冲区读取图片进行处理需要10ms,但是你读取到图片后你还需要进行检测和显示耗时假如在100ms,所以你从读取到一张图片到显示在你的界面上需要110ms,但是此时你的缓冲区已经存储了5,6张图片了,所以你要解决这个问题。(跳帧和多线程可以解决延迟问题)
另一个困惑大家的问题就是如何检测到目标进行报警的功能,在网上我是没有搜到相关的代码,所以这一部分是自己写一个吧
def play_music(self)
winsound.PlaySound('选择你要播放的WAV音频',winsound.SND_ASYNC)
time.sleep(休眠时间以s计数,我设置的是0.5)有了报警函数,当检测到物体调用此函数进行报警,但是这样会有延迟出现,所以这里又要用到多线程(cpu已经开始爆炸了)
此时网络摄像头延迟问题、报警问题有一定的解决,但是你会发现你的显存不够用,因为你启动多线程进行检测,假如隔5帧进行图片的抓取进行处理并启动检测的多线程,多线程里面会有一个调用GPU的操作,在GPU上进行操作它会使用显存如下:
pred = model(img, augment=opt.augment)[0]
大家可以看到6G的显存已经占了5G,所以看到这里很多大佬已经开始嘲讽我的编程技术了哈哈!
三.界面打包
大家可以去关注一下迷途小书童点击关注,网上有很多使用pyinstaller进行打包的教程,但是并没有针对深度学习的一些打包过程,这个过程真的会出现很多问题!大家可以直接进入原博主官网https://xugaoxiang.com/2021/10/13/yolov5-to-exe/
Python 项目打包是很多新手经常会问的问题,之前也有文章介绍过如何使用 pyinstaller 来打包生成可执行文件,只不过打包过程是基于命令行的。本文介绍的这个工具,auto-py-to-exe,它是 pyinstaller 的 GUI 版本,对新手更加友好,点点鼠标就可以轻松搞定,那么,快开始吧。
进入根目录找到exe文件:
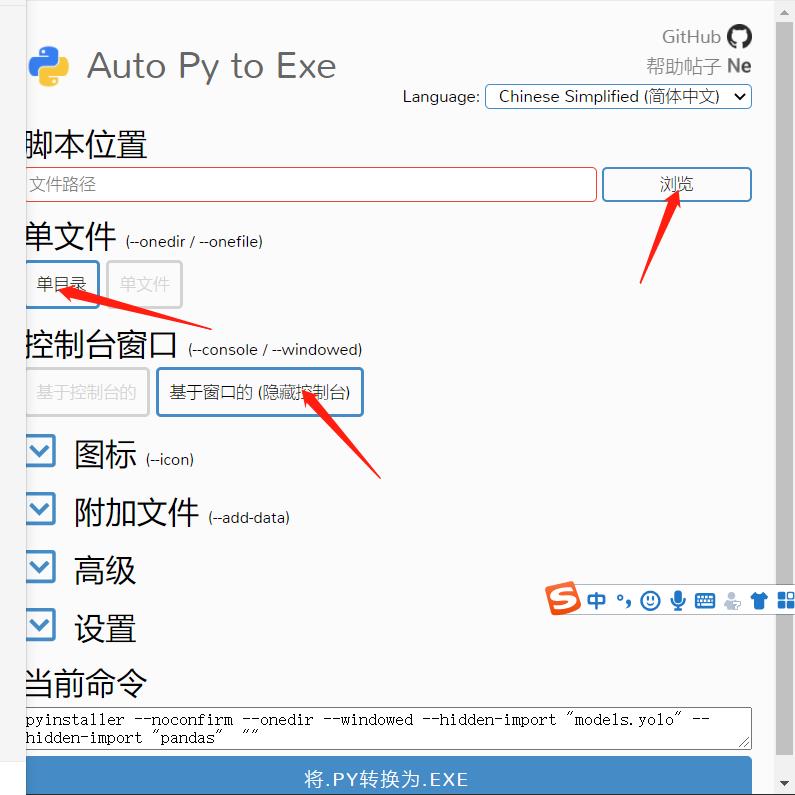
打开之后脚本位置就是你要打包的主程序,他会打包你所包括的其他文件
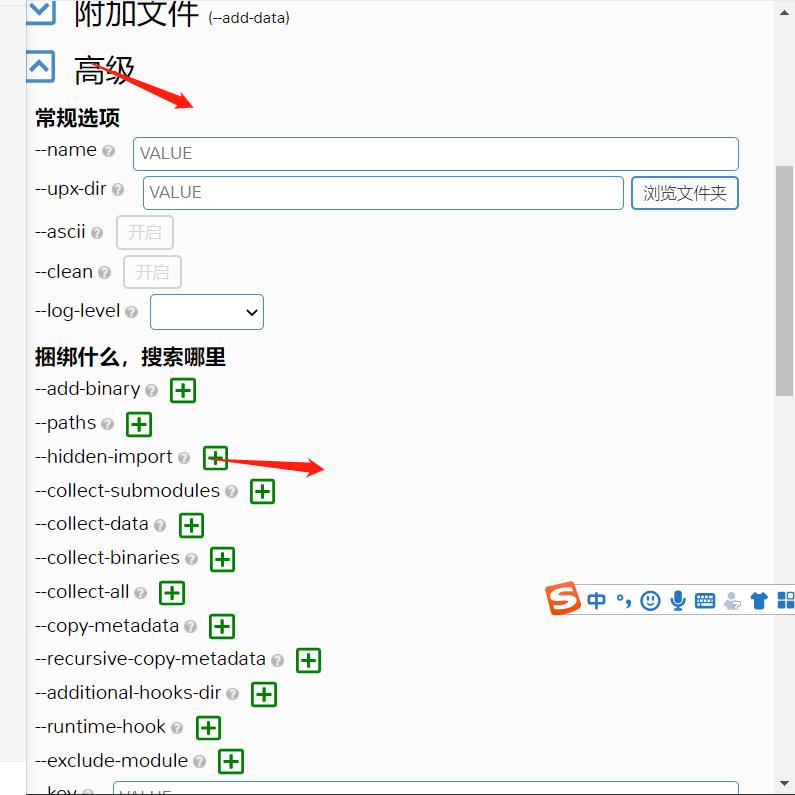
这里的pandas一般都会出错,所以我们在之前直接添加。
选择你的输出路径
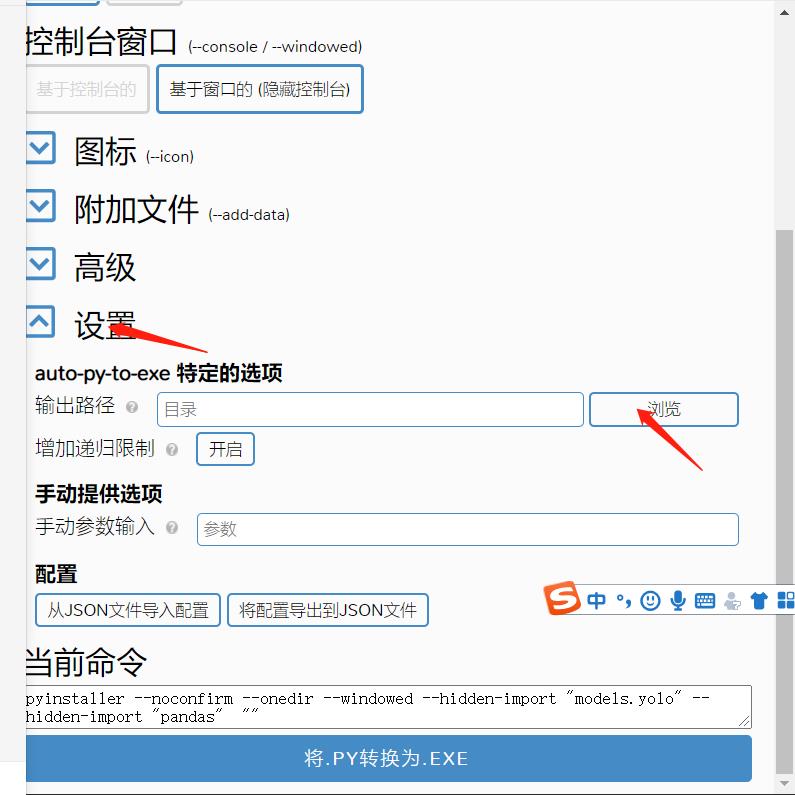
耐心等待几分钟,错误就出现了!
SystemExit: Unable to find "d:anaconda3envspytorchLibrarybinlibiomp5md.dll" when adding binary类似这种问题什么找不到啊,你就直接去这个路径下面搜索一下,如果不存在就去你的回收站是不是把他删了,要不然就去下载。
assert mpl_data_dir, "Failed to determine matplotlib's data directory!"
AssertionError: Failed to determine matplotlib's data directory!这个问题大家可能也会遇到,有的大佬说先把matplotlib卸载了再打包,这样确实不会影响自己的打包,但是你打包出来的EXE无法运行,所以最好的解决办法就是,先卸载掉这个,更新自己的PIP,再重新下载:
#首先进入自己的环境
pip uninstall matplotlib
python -m pip install --upgrade pip
#更新完之后
pip install matplotlib像这样HOOK的问题:
PyInstaller.exceptions.ImportErrorWhenRunningHook: Failed to import module __PyInstaller_hooks_18_pandas_io_formats_style required by hook for module d:anaconda3envspytorchlibsite-packagesPyInstallerhookshook-pandas.io.formats.style.py.1.卸载和重新安装pyinstaller
pip uninstall pyinstaller
pip install pyinstaller
2.报错肯能是由于环境中安装了过时的 IPython 引起的。我们可以尝试将其更新到更新的版本。
#进入你的环境
pip install --upgrade IPython
这两个应该就可以解决打包的问题了!
打包这种大型的EXE我建议还是单目录进行打包,方便解决问题。
然后你就会得到一个像这样的一个目录:
你已经迫不及待的点击它了,反应非常的慢,你会发现你还是运行不起来还是会报错:
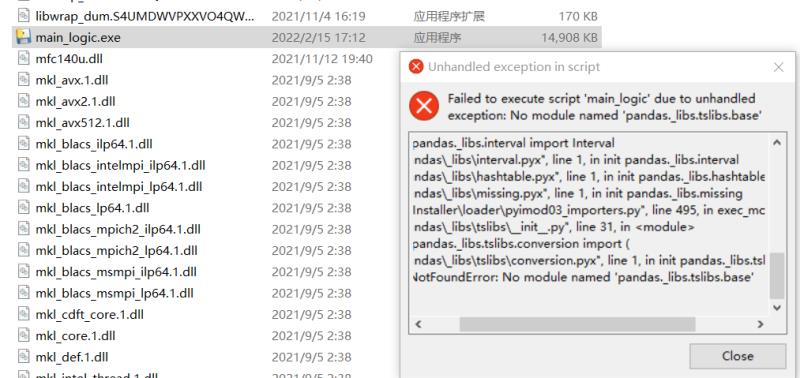
很痛苦在网上疯狂的百度搜索,后来发现:你的打包pandas目录里面和你的本机pandas少了一个文件如下:
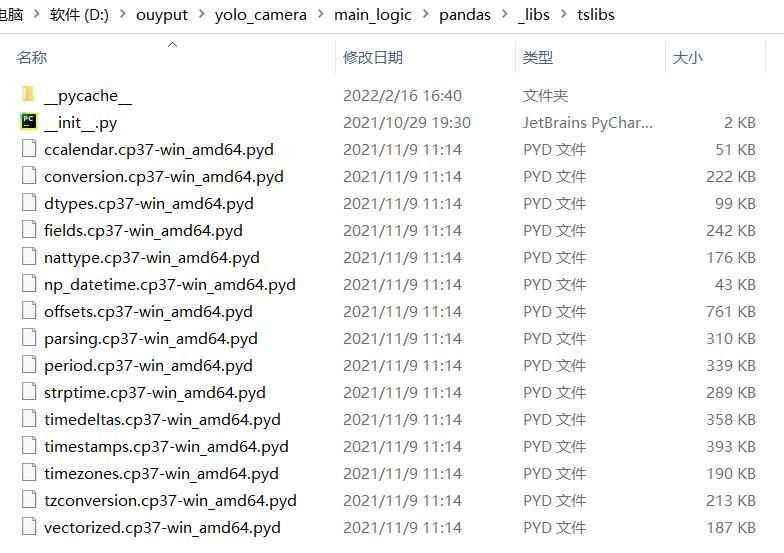
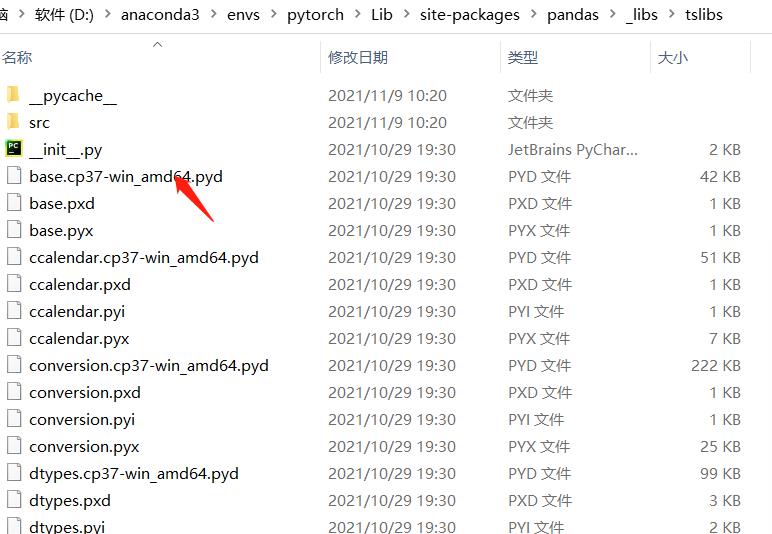
大家可以看到少了一个这个文件,所以把他复制到你的打包文件里面就可以了;让我们运行一下试试,果然可以运行了,

到这里你以为就结束了?还是太年轻了,你会发现你点击登录卡死在登录界面,这又是为什么呢?因为你要导入你的账号和密码登录表,这个原因我找了很久不知道为什么,如下的一个文件:
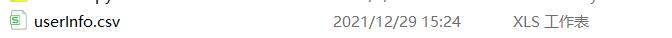
OK,导入到你的根目录他就可以跳转到你的主界面了,你可以拿着你的摄像机出去检测了。
四.总结
这个项目大约做了两三个月吧,对于菜鸟级别的我慢慢成长才是关键,如果大家有什么好的意见或者咨询一些问题的话可以加入QQ群:471550878,
最后
以上就是干净蜡烛最近收集整理的关于YOLOv5桌面应用开发(从零开始)的全部内容,更多相关YOLOv5桌面应用开发(从零开始)内容请搜索靠谱客的其他文章。








发表评论 取消回复