我是靠谱客的博主 无语飞机,这篇文章主要介绍技校新闻爬虫食用方法抓取思路分析正文一、学校新闻抓取二、党群工作新闻抓取三、技能培训新闻抓取四、教学科研新闻抓取五、 拼接数据六、保存数据,现在分享给大家,希望可以做个参考。
食用方法
- 代码直接从正文部分开始,想看实现的可以直接跳到后面,前面是思路测试部分;
- 抓取网站主页http://www.gdnjsxy.com/;
- 本文章仅供学习和教学使用,请误滥用技术,滥用导致的其他法律问题本人概不负责;
- 文章使用了python的bs4、requests、re、pandas库,请自行安装和准备运行环境;
- 本文实现了新闻文章标题、日期、文章内容的批量抓取和新闻分类标签的获取,为后一步的新闻分析提供数据,网站的其他信息可以举一反三;
- 如有不足欢迎讨论和斧正。
抓取思路分析
找出需要抓取新闻的网页标签特征
import requests
from bs4 import BeautifulSoup
import re
url = '''http://www.gdnjsxy.com/Home/Article/lists/category/3.html'''
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
response = requests.get(url=url,headers=headers)
result_str = response.content.decode("utf-8")
soup = BeautifulSoup(result_str,'lxml')
return soup
soup = get_html(url)
print(soup.prettify())

观察发现列表页的文章都在class=f-fl的div中,接下来使用以下代码就可以获取文章地址了。
print(soup.find_all("div",attrs={
"class":re.compile("f-fl")}))

文章标题都在a标签中,使用以下代码:
print(soup.find_all("a",attrs={
"class":"atitle"}))

# 列表页中每篇文章标题
title_texts = [i.get_text() for i in soup.find_all("a",attrs={
"class":"atitle"})]
title_texts

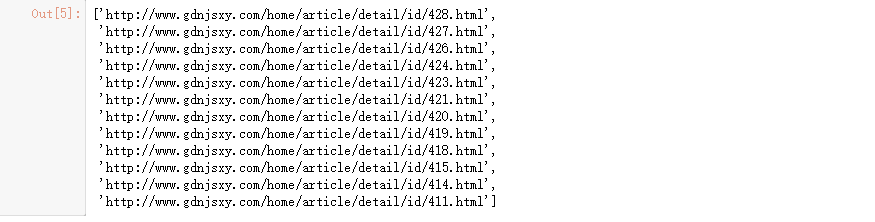
通过列表页就可以获取所有文章地址了,代码如下:
# 每篇文章地址
urls_texts = [i.get_text() for i in soup.find_all("a",attrs={
"class":"atitle"})]
links = ["http://www.gdnjsxy.com{}".format(i.attrs["href"] )
for i in soup.find_all("a",attrs={
"class":"atitle"})]
links
正文
步骤
- 获取所有学校新闻列表页地址
- 通过学校新闻列表页获得所有详情页地址
- 在详情页中通过h2标签获得标题
- 在详情页中通过span标签获得文章内容。
- 获取各分类文章地址
- 给各类别文章地址打上分类标签
- 通过标签配对学校新闻地址
- 合并所有分类数据。
列表页地址:
http://www.gdnjsxy.com/home/article/lists/category/3/p/1.html
http://www.gdnjsxy.com/home/article/lists/category/3/p/2.html
详情地址:
http://www.gdnjsxy.com/home/article/detail/id/427.html
http://www.gdnjsxy.com/home/article/detail/id/409.html
观察发现仅最后部分页码不同,构建相应地址就可以开始了。
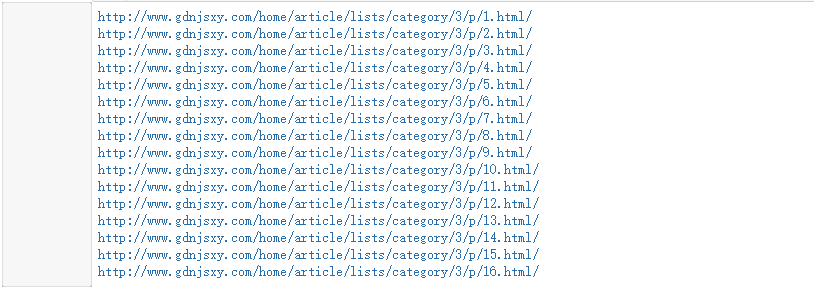
一、学校新闻抓取
#构建学校新闻列表页地址
pagesize = 16
urls = ['http://www.gdnjsxy.com/home/article/lists/category/3/p/{}.html/'.format(i) for i in range(1,pagesize+1)]
for i in range(0,16):
print(urls[i])
1. 抓取详情页地址
import requests
from bs4 import BeautifulSoup
import re
# 获取页面
def get_html(url):
headers = {
最后
以上就是无语飞机最近收集整理的关于技校新闻爬虫食用方法抓取思路分析正文一、学校新闻抓取二、党群工作新闻抓取三、技能培训新闻抓取四、教学科研新闻抓取五、 拼接数据六、保存数据的全部内容,更多相关技校新闻爬虫食用方法抓取思路分析正文一、学校新闻抓取二、党群工作新闻抓取三、技能培训新闻抓取四、教学科研新闻抓取五、内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。







![BeautifulSoupu’b’u’boldest’{u’class’: u’boldest’}u’Extremely bold’
No longer bold
u’[document]’u’Hey, buddy. Want to buy a used parser’
The Dormouse’s storyThe Dormouse’s storyThe Dormouse’s storyElsie[Elsie,Lacie,Tillie]The Dormouse’s storyThe](https://www.shuijiaxian.com/files_image/reation/bcimg13.png)
发表评论 取消回复