从本文开始,进入下一个单元,在此后的几篇博文,将深度解析C语言的一些难点与重点,也是为以后的C++学习打基础的过程
作者:小 琛
欢迎转载,请标明出处。
整形的存储
我们知道,整形有如下内容:
char //字符数据类型
short //短整型
int //整形
long //长整型
long long //更长得整形
在此基础上,还有相对应得指针内容。
而一个变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的。
例如有:
int i=20;
int j=-10;
这两个变量在内存中是如何存储得呢?
源码、反码、补码
这里就要引入三个概念:源码、反码、补码
这三个概念有相同处:都有符号位和数值位两部分,其中0代表正1代表负,而也有不同之处如下
原码
直接将二进制按照正负数的形式翻译成二进制就可以。
反码
将原码的符号位不变,其他位依次按位取反就可以得到了。
补码
反码+1就得到补码。
计算机对于数据的存储是以补码的形式,其中正数的源码反码补码都是其本身
而对于上面的例子 j=-10;我们可以来实际转换一下
源码:1000 0000 0000 0000 0000 0000 0000 1010
反码:1111 1111 1111 1111 1111 1111 1111 0101
补码:1111 1111 1111 1111 1111 1111 1111 0110
结合i=20;其补码源码反码相同为:
0000 0000 0000 0000 0000 0000 0001 0100
倘若运算i+j;则是补码进行运算结果为:
0000 0000 0000 0000 0000 0000 0000 1010
而要得到该数据本身的值,则逆推整个过程
判断符号位是0,代表正数,则源码就是补码,转换为10进制为10,运算完成。
大端、小端
在该大标题下我们还需要了解一个内容:大端和小端
什么是大端和小端:
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
方便记忆:
大端:低地址存放高数据
小端:低地址存放低数据
一道面试问题:如何判断大小端
代码:
#include <stdio.h>
int check_sys()
{
int i = 1;
return (*(char *)&i);
}
int check_sys1()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;
}
int main()
{
int ret = check_sys();
if (ret == 1)
{
printf("小端n");
}
else
{
printf("大端n");
}
return 0;
}
难点:浮点型数据的存储
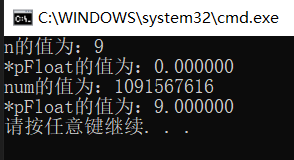
这里先看一个例子,分析输出结果:
#include <stdio.h>
int main()
{
int n = 9;
float *pFloat = (float*)&n;
printf("n的值为:%dn", n);
printf("*pFloat的值为:%fn", *pFloat);
*pFloat = 9.0;
printf("num的值为:%dn", n);
printf("*pFloat的值为:%fn", *pFloat);
return 0;
}
其结果如下:
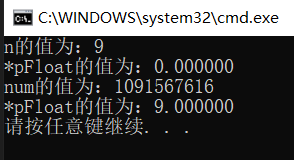
num和*pFloat在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别这么大?
要搞明白这个问题,必须要把浮点数的储存搞清楚。
根据国际标准IEEE(电气和电子工程协会)754,任意一个二进制浮点数V可以表示成下面的形式:
-1)S*M*2E
·(-1)^s表示符号位,当s=0,V为正数;当s=1,V为负数。
·M表示有效数字,大于等于1,小于2。
·2^E表示指数位。
例如十进制的5.0,按照如上公式去写:
5.0的二进制位0101.0,为正数,则s=0;而M为1.01;指数是2^2,则E为2
综合:-1^0 * 1.01 * 2 ^2
但注意这并不是最终版本
接下来我们深入内存,用图讲述储存的真实情况:


通过上图我们可以清晰的明白其储存,但这里有几点非常重要:
1、上面我们提到,对于有效数字,范围是>=1且<2,也就是说,有效数字永远是1.xxxx,因此,IEEE754组织规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分,这样可以提高内存利用率
2、对于指数E,比较复杂一些,E为一个无符号整数,这意味着,如果E为8位,它的取值范围为0-255;如果E为11位,它的取值范围为0~2047。但我们都知道,指数的E是有负值存在的! 因此IEEE754组织规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。
3、当E全为0时,这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字;当E全为1时,这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s)。
有了这些基础,我们重新看开头的代码
1、首先解释,当把整形的数据强行转为浮点型,为什么会是0.00000.
由上述的分析,对于9,二进制:
0000 0000 0000 0000 0000 0000 0000 1001
倘若把它转为浮点型,结合浮点型的存储规律得:符号位是0,指数位是:
0000 0000,有效数字位(加1后):1.00000000000000000001001
也就是说最后运算为:-1^0 * 1.00000000000000000001001* 2-127
很明显是一个无限接近于0的小数,结合上述第三条,得到0.000000
2、其次就是为什么将其修改为9.0再以%d输出会出现1091567616
我们再次进入分析,对于9.0的二进制:
1001.0,有效位1.001*2^3,而因为是正数,符号位为0,指数位为:3+127
二进制是:1000 0010
因此内存中应当为:0 10000010 00100000000000000000000
而现在以整数输出,我们使用计算器来将该值转换为10进制

很明显,符合推理。
到这里,C语言深入的第一节就讲述完成,感谢浏览
最后
以上就是傲娇大叔最近收集整理的关于C语言的深入——数据存储篇的全部内容,更多相关C语言内容请搜索靠谱客的其他文章。
![[C语言数据存储深度解析]-内存数据搞不懂?三千字长文带你走进数据类型及其存储C语言的基本数据类型内置类型的基本归类整型数据在内存中的存储浮点型数据在内存中的存储写在最后](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)







发表评论 取消回复