环境
IDE:VS2019 msvc2017_64
OpenCV版本:3.4.15
一、OpenCV
1.编译OpenCV
尽量重头说起 因为搞不好我到时候也忘了-。-
先是编译OpenCV VS跟mingw的编译方式不同 所以要用QtCreator的编译方式尽量参考别的作者的
1.首先去下载OpenCV
OpenCV下载
ps:如果你要修改源码自己编译的话 跟 直接下载安装的是不同的
直接下载安装的话 直接配置即可


include x64/v14 || x64/v15 bin 载入到VS即可
如果是源码重新编译的话 你需要cmake

上面源码 下面是编译到哪里(自己建立一个路径)
然后Congigure
记得勾上WITH_QT与WITH_OPENGL


再次Congigure编译到没有红色
就开始Generate
Generate成功就OpenPreject

这一步需要Release就编译Release
需要Debug就编译Debug
然后生成ALL_BUILD
这一步需要的时间蛮久的-。-
生成成功就生成install
生成之后去你刚刚cmake指定的那个生成路径
下面有一个install文件
里面有要的include lib bin
2.使用opencv
然后可以尝试使用一下
右键项目属性->VC++目录
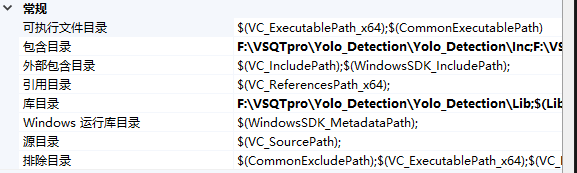
打开VS 包含目录包含include的路径

库目录包含lib的路径

右键项目属性->链接器->输入
包含lib文件

然后bin目录喜欢放环境变量跟项目下面都可以 随你
二、yolo4
yolo4需要的条件
CUDA 10.0 以上版本
Cudnn 根据你CUDA的版本就行(好像最低7.6吧)
OpenCV 3.4版本+ 好点
1.前置条件下载
首先CUDA
Cuda下载
因为我是他推荐的版本 11.4 然后cudnn也是他推荐的版本
Cudnn也可以在Cuda的链接下载(不过Cudnn很麻烦 好像要注册账号才可以下载之后) OpenCV也在上面
Cuda下载好

会有一个这样的文件夹 里面有bin include lib
然后下载的Cudnn的bin include lib 里面的文件也放在cuda的bin include lib 里面即可
记得把cuda/cudnn Opencv bin目录放在环境变量里面-.-
2.下载 编译darknet
下载地址
下载好了之后

进入到这里 然后你需要gpu版本跟不gpu版本都可以 gpu版本会比较快 那个没有no_gpu的就是有gpu的
然后有2样是需要编译的
一个是yolo_cpp_dll.sln 或者 yolo_cpp_dll_no_gpu.sln
一个是darknet.sln 或者 darknet_no_gpu.sln
当中2选1啦 我选的都是有GPU 所以拿yolo_cpp_dll跟darknet举例

首先打开这个文件 将当中的cuda版本改成你自己装的版本

自己搜索一下改一下就好了
全部改完了之后打开对应的sln文件

这里我之前看别人的文章的时候是需要2015 也就是不升级的 但是我这里是升级成vs2019 应该没差
右键属性 VC++目录->常规->包含目录
包含opencv 跟你的cuda的include路径 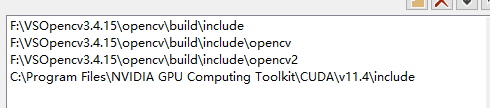
右键属性 VC++目录->常规->库目录
包含opencv 跟你的cuda的lib路径


还有算力 改成你显卡的算力 我记得可以查询到的
别照着别人的抄哦 每个显卡都不一样哦
右键项目->属性->连接器->输入
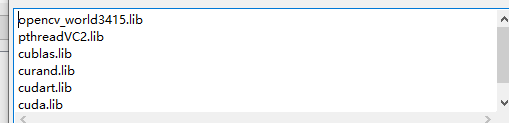
把Opencv的库包含进去哦
再唠叨一句: PS 记得把OpenCV的bin跟cuda的bin要么放在环境变量 要么丢在项目的下面 以防万一
然后编译yolo_cpp_dll.sln跟darknet
编译好了

yolo_cpp_dll.sln会生我们的dll跟lib库
darknet 则会生成exe的可执行文件
三.使用yolo4 与 OpenCV QT
那么我们就开始写我们的项目
首先我们要去下载一个训练好的模型
模型以及权重文件
这里直接拿前辈的链接 自己去里面下载
yolo4.weights 以及 yolov4.conv.137
yolo4.weights 是已经训练好的模型
yolo4.conv.137是等等我们要训练的权重文件
1.写代码
首先是界面

中间的是openGLWidget
然后2个按钮 一个是打开摄像头 一个是开启yolo4
突然累了 不想写了 我之前的openCV的文章里面的代码跟这个一模一样 自己去看看把 后续想写了再改好吧
这里就讲一下怎么使用yolo4
这里我们先用原来就给我们提供好的模型
首先我们从


编译好的地方拿到coco.names 以及yolo4.cfg这个文件以及刚刚下载好的yolo4.weights文件

然后定义这个文件

上面是使用模型

然后是画圈圈

效果很显著 也很卡-。-奶奶的
四.训练模型
太卡了 训练一个自己的模型吧
首先 我们要去windows哪里下载一个python
我当时好像再cmd 直接 ptyhon + 运行文件
他说我没安装就直接跳转安装了
首先先建立一个目录
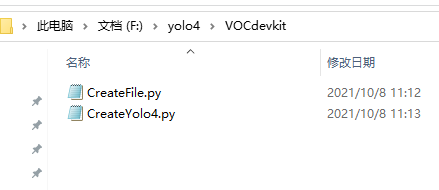
进入里面运行py文件

会帮我们创建文件

首先 Annotations文件夹
里面装的的图片中的xml文件
ImageSets文件夹
里面装的是Main文件夹 Main里面装的是图片的名称
JPEGImages文件夹
里面装的是原图
labels文件夹
里面装的是记录图片的标签类别,中心点的x,中心点的y,标签的宽,边框的高
TESTImages文件夹
里面装的是训练过后需要处理的图
然后我们用寻找你想要标记的原图
用这个软件去把图片标记
我这边放了划了700张

把标记过后的xml全部标记 放在Annotations文件
把原图 放在JPEGImages文件

然后继续运行第二个py文件生成ImageSets/Main里面的图片名称 txt

将生成的图片放在mian中



然后出来运行最后一个python文件
生成2021_train.txt 跟2021_val.txt
里面是图片路径

生成的路径放在vocdevkit里面 准备工作就完成了
最后再新创建一个文件夹

里面的内容是你刚刚用标记xml那个文件标记的种类 我只标注了一个face 所以就只写了一个 文件已经准备好了

进入存在exe的地方
把刚刚下载的权重文件yolov4.conv.137放在里面
然后我们需要修改配置文件

首先进入data文件把这个文件复制到存在exe的地方

修改成我们路径的地方
backup就是最终模型生成的地方
其余的都是我们上面生成的文件
接着进入cfg文件夹,复制yolov4-voc.cfg出来改成yolo4-obj.cfg 这个应该随便改都可以
然后打开修改里面的配置

首先是
batch=16
这个一开始是64我改32 发现32不行 就改成16 batch不宜过大,过大显存会爆,导致不能训练
其次是width 跟 height
图片的话改成416*416 我也不知道为什么 这个是看之前博主的 你们可以参考一下 也可以保持原大小不动试试
然后是max_batches = 2000
个人建议是训练的数量 比如我上面有face 只有一个 所以就2000 * 数量即可
还有steps = 1600,1800
这个改成max_batches的80%跟90%即可

然后就这个文件开始搜索yolo关键字
总共应该可以搜索到3次yolo 改3次
yolo上面 convolutional组 的filters 改成
filters=(classes + 5)*3 因为我只有一个filter 所以是18
yolo组内的classes 改成你分的种类 因为我只有一个face 所以改成1
配置好了之后 cmd 进入到 存有exe的文件夹
darknet.exe detector train voc.data yolov4-obj.cfg yolov4.conv.137 -map
记得修改成你们的名称 这里是我的名称


等待其训练 完成之后就有自己的模型了
完成之后把刚刚的配置文件yolov4-obj.cfg 跟 刚刚的名称文件 2021-objname.txt 以及 训练好的模型 拿去 替换程序当中的



自己的模型就训练好了
五.总结
因为我比较顺利 几乎几次就好了 当中如果有其他的问题你们可以评论区问 我如果明白我会回答你 我不会的就不好意思 麻烦你就自己找找 我当时也是这样的-。-哎-。-
最后
以上就是碧蓝金鱼最近收集整理的关于QT VS2019 OpenCV yolo4 摄像头识别人脸环境一、OpenCV二、yolo4三.使用yolo4 与 OpenCV QT四.训练模型五.总结的全部内容,更多相关QT内容请搜索靠谱客的其他文章。








发表评论 取消回复