文章目录
- 一、实验环境
- 二、实验内容
- 安装Spark环境
- Spark编程练习:
- 使用scala语言编写独立应用程序:
- 出现的问题
一、实验环境
- 操作系统:Linux(与实验1保持一致);
- Hadoop版本:3.3.1;
- Spark版本:3.1.2
二、实验内容
安装Spark环境
- 完成Spark安装,根据实验1所安装的Hadoop模式,选择Spark的配置模式;
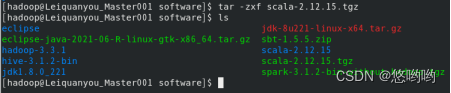


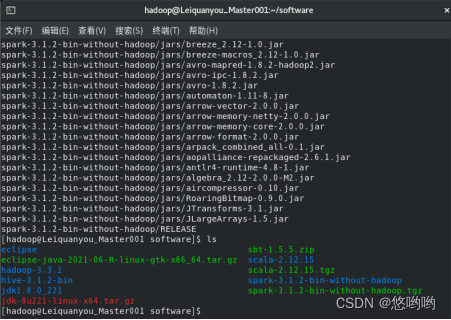

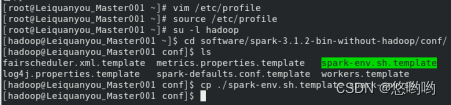
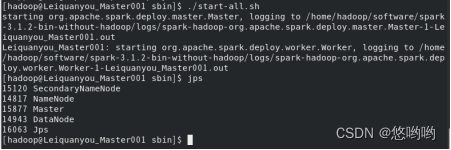
2.将Spark的配置文件详细清单列出;给出进程运行截图和网页总览页面截图

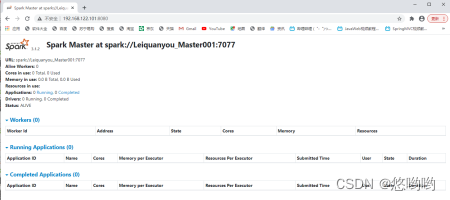


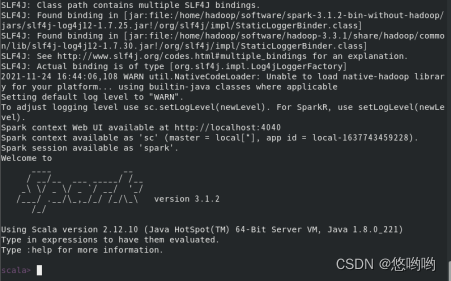
Spark编程练习:
(1)在Spark-shell中读取本地文件“/home/hadoop/test.txt”,统计文件行数

(2)在Spark-shell中读取HDFS系统文件“/user/hadoop/test.txt”(该文件不存在,请先创建),统计文件行数

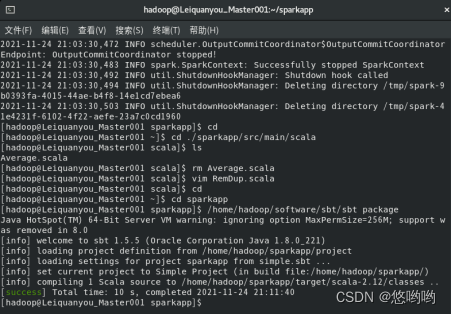
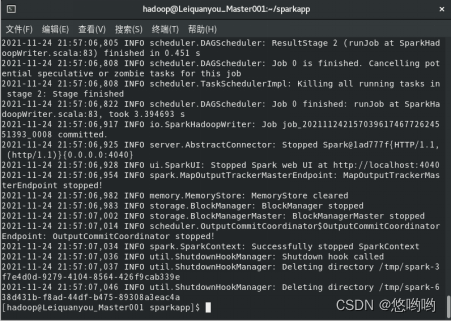
(3)使用scala语言编写独立应用程序,读取HDFS系统文件“/user/hadoop/test.txt”,统计文件行数;通过使用sbt工具将整个应用程序打包成jar包,并将jar包通过spark-submit提交到spark中运行。
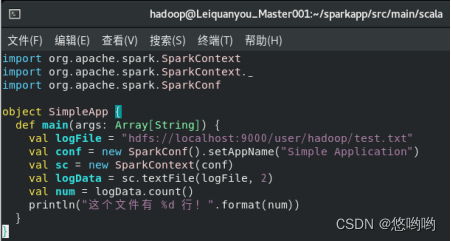
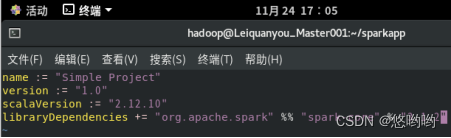
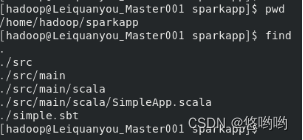
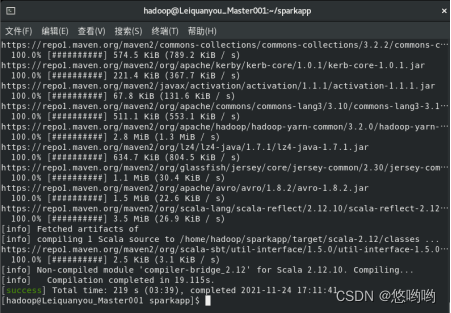
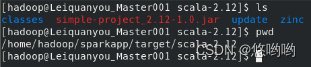

使用scala语言编写独立应用程序:
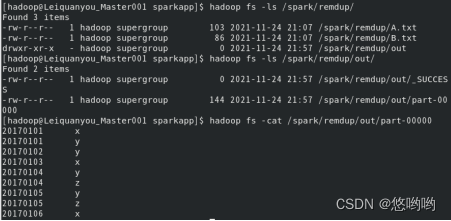
(1)对于两个输入文件A和B,编写Spark独立程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的样例:
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
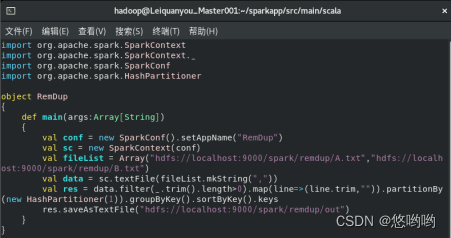
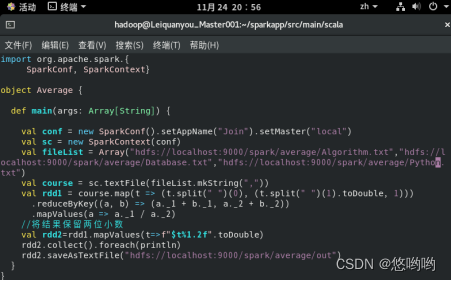
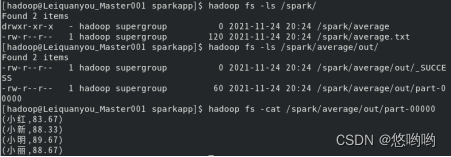
(2)每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例:
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
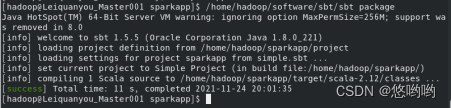
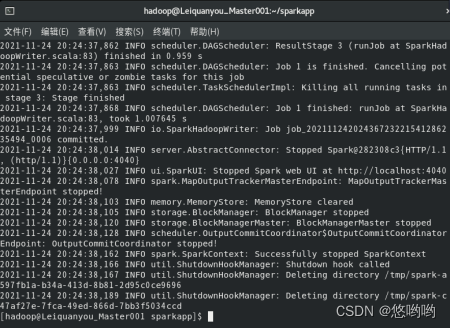

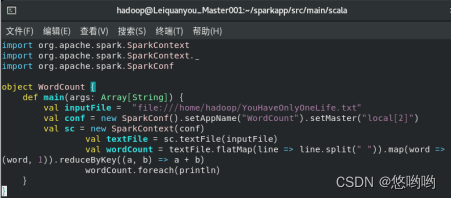
(3)重新使用实验2下载的英文短文,编写spark独立应用程序,完成词频统计。要求给出代码及具体注释,程序运行结果截图。
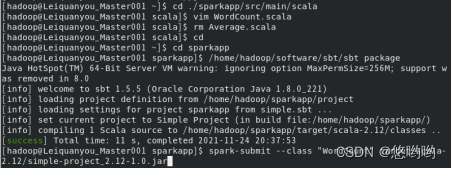
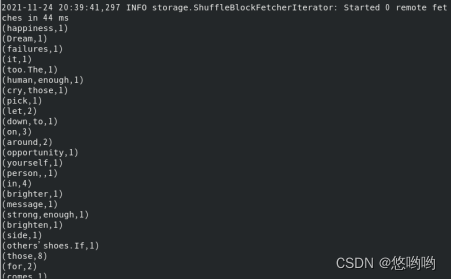
出现的问题
1.failed to launch: nice -n 0 /home/hadoop/software/spark-3.1.2-bin-without-hadoop/bin/spark-class org.apache.spark.deploy.master.Master --host Leiquanyou_Master001 --port 7077
2.网页无法浏览。
Spark shell运行报错Invalid Spark URL: spark://HeartbeatReceiver…
解决方案:
1.spark-env.sh中需要添加export SPARK_DIST_CLASSPATH=
(
(
(HADOOP_HOME/bin/hadoop classpath)
2.需要关闭防火墙:systemctl stop firewalld.service。
在spark-env.shell中设置export SPARK_LOCAL_HOSTNAME=localhost。
最后
以上就是受伤草莓最近收集整理的关于【大数据技术】实验4:熟悉Spark基础编程一、实验环境二、实验内容出现的问题的全部内容,更多相关【大数据技术】实验4:熟悉Spark基础编程一、实验环境二、实验内容出现内容请搜索靠谱客的其他文章。








发表评论 取消回复