Java版的Spark大数据中文分词统计程序完成之后,又经过一周的努力,把Scala版的Spark
大数据中文分词统计程序也搞出来了,在此分享给各位想学习Spark的朋友。
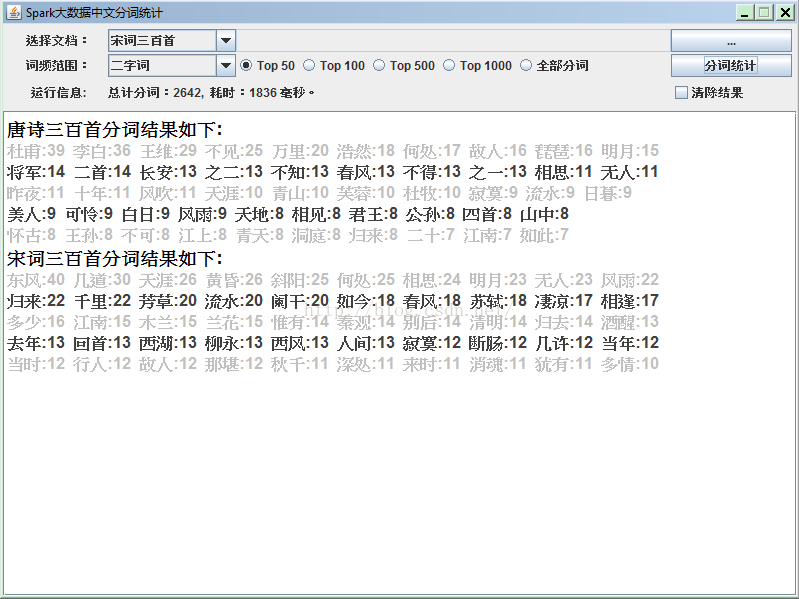
如下是程序最终运行的界面截图,和Java版差别不大:
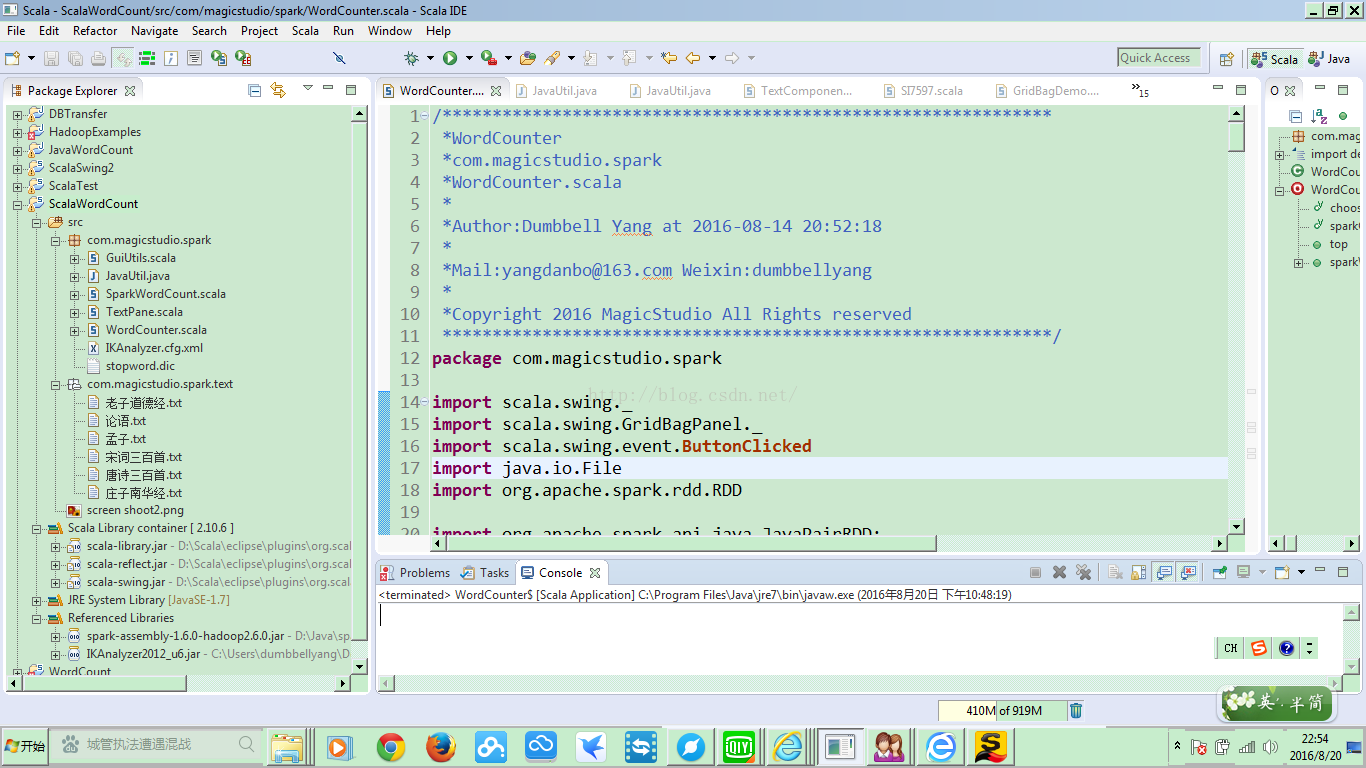
如下是Scala工程结构:
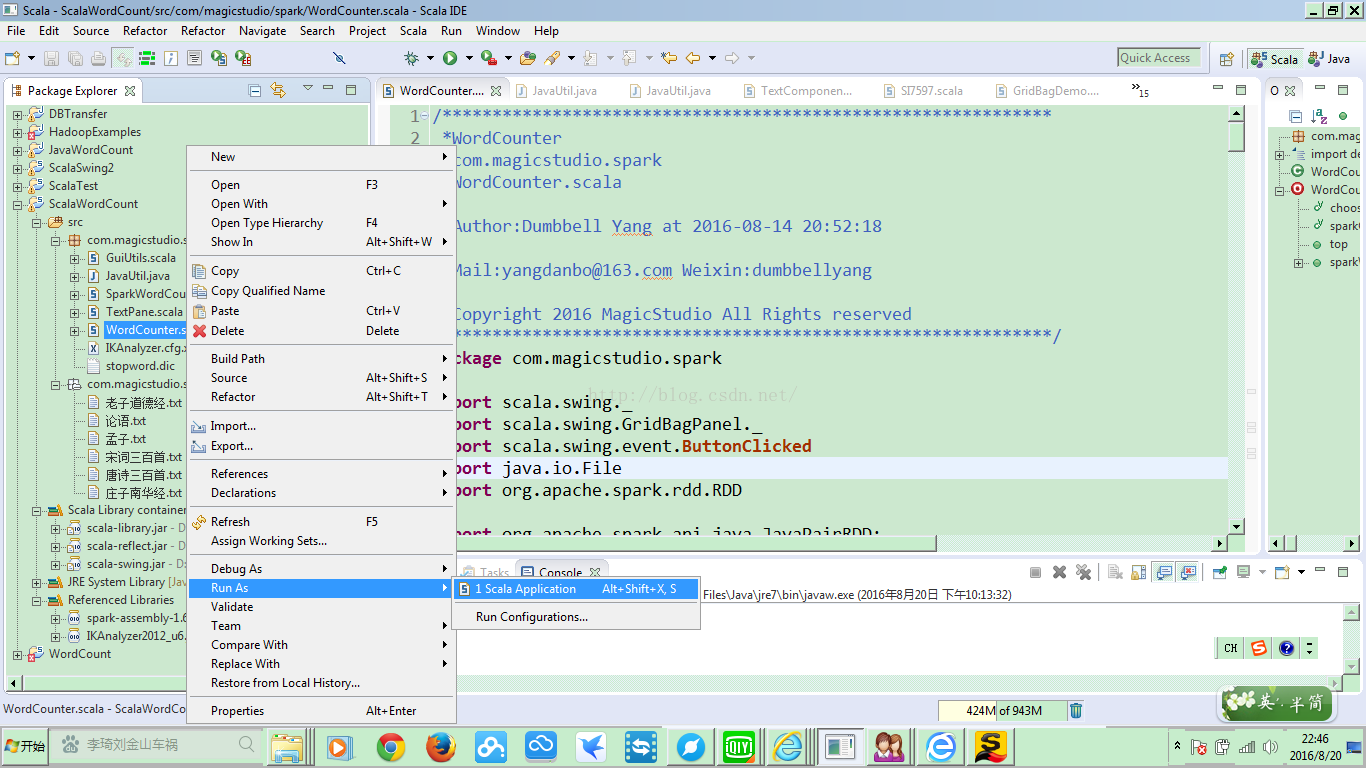
当你在工程主类文件WordCounter.scala上单击右键,选择Run As Scala Application:
然后选择唐诗宋词进行分词统计,就会出现前面显示的分词结果。
工程代码已经上传CSDN:http://download.csdn.net/detail/yangdanbo1975/9608632。
整个工程结构很简单,Text包中和Java工程中一样,包含了内置的文本文件。整个工程引用的类库和Java工程类似,只是多了Scala的内容。
需要注意的是,由于Scala版本的不同, Scala缺省引用的类库也有所不同,例如当选择Eclipse自带的Scala 2.10.6版本时,swing类库是自动引
入的,如下图所示:

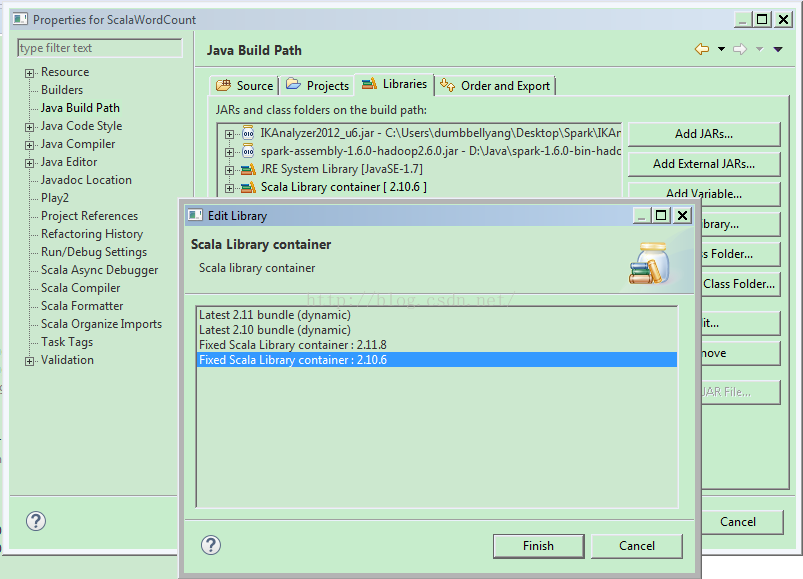
可是,如果你选择不同的Scala版本,比如最新下载安装的2.1.18版,swing类库就得自己手动加载了:

你可以在工程属性的Java Build Path -> Scala Library Container 中Edit Library,来切换Scala Library的版本:
整个工程总共包括GuiUtils.scala,SparkWordCount.scala,TextPane.scala和WordCounter.scala四个Scala类和JavaUtil.java一个Java类。
GuiUtils.scala完全复制自网上代码,实现了类似 于Java Swing中OptionPanel的message 提示框的功能。
TextPane.scala则复制自GitHub上的ScalaSwing2项目,把JTextPanel移植到了Scala中。标准的Scala Library直到2.1.18版本都没有实现
TextPanel,只有TextArea,我们的工程中显示分词结果沿用了Java版的JTextPane,所以我们复制了这个Scala版的。
SparkWordCount.scala类实现了Spark中文分词统计的核心功能,是在DT 大数据梦工厂王家林老师的SparkWordCount的代码基础上改写的。
首先,把主要功能步骤从伴生对象的main方法中移到了SparkWordCount类中,并拆分为多个方法,使得伴生对象的main方法和后面的GUI界面
都能调用:
class SparkWordCount {
var sc:SparkContext = null;
def initSpark(appName:String){
/**
* 第1步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要链接的Spark集群的Master的URL,如果设置
* 为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差(例如
* 只有1G的内存)的初学者 *
*/
val conf = new SparkConf() //创建SparkConf对象
conf.setAppName(appName) //设置应用程序的名称,在程序运行的监控界面可以看到名称
conf.setMaster("local") //此时,程序在本地运行,不需要安装Spark集群
/**
* 第2步:创建SparkContext对象
* SparkContext是Spark程序所有功能的唯一入口,无论是采用Scala、Java、Python、R等都必须有一个SparkContext
* SparkContext核心作用:初始化Spark应用程序运行所需要的核心组件,包括DAGScheduler、TaskScheduler、SchedulerBackend
* 同时还会负责Spark程序往Master注册程序等
* SparkContext是整个Spark应用程序中最为至关重要的一个对象
*/
sc = new SparkContext(conf) //创建SparkContext对象,通过传入SparkConf实例来定制Spark运行的具体参数和配置信息
}
def wordCount(doc:String, wordLength:Int):RDD[(String,Int)]={
/**
* 第3步:根据具体的数据来源(HDFS、HBase、Local FS、DB、S3等)通过SparkContext来创建RDD
* RDD的创建基本有三种方式:根据外部的数据来源(例如HDFS)、根据Scala集合、由其它的RDD操作
* 数据会被RDD划分成为一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴
*/
//val lines = sc.textFile("E://text//唐诗三百首.txt", 1) //读取本地文件并设置为一个Partion
//val lines = sc.textFile("src/com/magicstudio/spark/text/唐诗三百首.txt", 1)
val lines = sc.textFile(doc, 1)
/**
* 第4步:对初始的RDD进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算
* 第4.1步:讲每一行的字符串拆分成单个的单词
*/
//val words = lines.flatMap { line => line.split(" ")} //对每一行的字符串进行单词拆分并把所有行的拆分结果通过flat合并成为一个大的单词集合
val words = lines.flatMap { line => JavaUtil.getSplitWords(line, wordLength).asScala }
/**
* 第4步:对初始的RDD进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算
* 第4.2步:在单词拆分的基础上对每个单词实例计数为1,也就是word => (word, 1)
*/
val pairs = words.map { word => (word, 1) }
/**
* 第4步:对初始的RDD进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算
* 第4.3步:在每个单词实例计数为1基础之上统计每个单词在文件中出现的总次数
*/
val wordCounts = pairs.reduceByKey(_+_) //对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce)
//added by Dumbbell Yang at 2016-07-24
wordCounts.sortBy(x => x._2 , false, wordCounts.partitions.size)
}
def outputResult(wordCounts:RDD[(String,Int)]){
wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + " : " + wordNumberPair._2))
}
def closeSpark(){
sc.stop()
}
}
其次,在wordCount方法中,把原来第3步读取固定文件的方式改为参数方式,可以是src目录下的相对文件路径(在GUI界面上通过下拉
框选择),也可以是本地磁盘上的绝对文件路径(通过文件浏览框选择):
//val lines = sc.textFile("E://text//唐诗三百首.txt", 1) //读取本地文件并设置为一个Partion
//val lines = sc.textFile("src/com/magicstudio/spark/text/唐诗三百首.txt", 1)
val lines = sc.textFile(doc, 1)
然后就是第4.1步中,通过调用JavaUtil类中的java方法,实现了中文分词功能,替换掉原来简单的split,对每一行文本进行中文分词:
//val words = lines.flatMap { line => line.split(" ")} //对每一行的字符串进行单词拆分并把所有行的拆分结果通过flat合并成为一个大的单词集合
val words = lines.flatMap { line => JavaUtil.getSplitWords(line, wordLength).asScala }
需要注意的是,由于需要调用Java功能,在Scala和Java之间进行数据传递,所以必须引用数据类型转换的library:
import collection.JavaConverters._
然后,才可以对JavaUtil中的getSplitWords方法返回的结果进行asScala的转换,使之能够满足Scala方法调用的要求。
最后的一个改动,就是加上了一个对分词统计结果按照词频进行排序的功能:
//added by Dumbbell Yang at 2016-07-24
wordCounts.sortBy(x => x._2 , false, wordCounts.partitions.size)
可以对比Java方法实现排序时,交换key和value,排序,然后在交换回去的繁琐,scala语言确实方便很多。
经过以上改动之后,Spark中文分词统计功能,既可以从main方法中调用,如伴生对象中原来的调用:
/**
* 使用Scala开发本地测试的Spark WordCount程序
* @author DT大数据梦工厂
* 新浪微博:http://weibo.com/ilovepains/
*/
object SparkWordCount{
def main(args: Array[String]){
val counter = new SparkWordCount
counter.initSpark("Spark中文分词统计")
val words = counter.wordCount("src/com/magicstudio/spark/text/唐诗三百首.txt", 2)
counter.outputResult(words)
counter.closeSpark()
}
}
也可以从WordCounter.scala这个GUI界面程序中调用。
WordCounter.scala类主要实现了Spark中文分词统计程序的GUI界面,代码也并不复杂,需要注意的有以下几点:
首先伴生对象声明,最新的Scala Library中,是基于SimpleSwingApplication的:
object WordCounter extends SimpleSwingApplication {
但是在早期Scala Library中,这个类名字是SimpleGUIApplication,所以网上很多没有及时更新的代码,在新的Scala
Library下都需要修改类名才能编译运行。
其次,是关于Scala函数返回值,文档上只是说函数最后一个语句的返回值就是函数的返回值,但其实并不具体,经过
程序测试,其实应该说是最后一个执行语句的返回值更确切些,而且应该指出在不同的条件下,会执行不同的逻辑,因而
最后一个执行语句并不是像很多例子中那样,一定就是语句的最后一行,例如:
def getDocPath():String={
if (docField.text.isEmpty()){
"src/com/magicstudio/spark/text/" + cboDoc.selection.item + ".txt"
}
else{
docField.text
}
}
再例如:
def getTopN():Int={
if (top50.selected){
50
}
else if (top100.selected){
100
}
else if (top500.selected){
500
}
else if (top1000.selected){
1000
}
else if (topAll.selected){
0
}
else{
0
}
}
而且,返回值不用写return,直接表达式即可,充分体现了Scala语言孜孜以求的精简。
最后值得一提的是Scala和Java的相互调用功能,对于复用已有的Java开发的大量应用功能,意义深远。
在Scala工程中,你可以添加Java类,引用已有的Java类,用java方法实现很多功能,然后在Scala类中来调用,
例如,在本工程中,中文分词功能就是通过java方法,引用IKAnalyzer组件在JavaUtil方法中实现的,在Scala类中
调用。再例如,JavaUtil中的其他方法,如:
public static void showRDDWordCount(JavaRDD<Tuple2<String, Int>> wordCount,
int countLimit, String curDoc, JTextPane resultPane, JCheckBox chkClear)
也是改写自原来的Java工程中的源码,在Scala类中引用,完成在GUI界面显示分词结果的功能。
当然,为了在Scala中引用,对参数做了一些改动,如原来没有传递界面控件,现在改成传递Scala界面组件的
peer(对应的Java Swing组件),原来的分词元组是Tuple2<String,Integer>,现在改成Tuple2<String,Int>,用Scala的
Int类型替换掉Java的Integer类型,因为Scala的RDD.toJavaRDD()方法生成的RDD是<String,Int>。而Java完全可以引
用Scala的Int类型(本来的Tuple2就是Scala的类型)。总而言之,Scala和Java相互调用的功能还是很强大,很方便的。
以上便是对Scala语言实现Spark中文分词统计的一个小小总结。以后有时间的话,我会继续尝试SparkStreaming,
Spark SQL等Spark其它相关技术,争取全面掌握Spark。
最后
以上就是孤独钢铁侠最近收集整理的关于Spark 大数据中文分词统计(三) Scala语言实现分词统计的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。








发表评论 取消回复