博主介绍: ????自媒体 JavaPub 独立维护人,全网粉丝15w+,csdn博客专家、java领域优质创作者,51ctoTOP10博主,知乎/掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和副业。????
公众号:JavaPub ⭐ ⭐简历模板、学习资料、面试题库等都给你????
???? 关注公众号【JavaPub】,回复:最少必要面试题 ,获取《10万字301道Java经典面试题总结(附答案)》pdf,背题更方便,一文在手,面试我有
以下都是Java的基础面试题,相信大家都会有种及眼熟又陌生的感觉、看过可能在短暂的面试后又马上忘记了。JavaPub在这里整理这些容易忘记的重点知识及解答,建议收藏,经常温习查阅。
评论区见
文章目录
- 1. instanceof 关键字的作用
- 2. Java自动装箱和拆箱
- 3. 重载和重写区别
- 4. equals与==区别
- 5. 谈谈NIO和BIO区别
- 6. String、StringBuffer、StringBuilder 的区别是什么?
- 7. 泛型是什么,有什么特点
- 8. final 有哪些用法
- 9. 说一下Java注解
- 10. Java创建对象有几种方式
- 推荐阅读:
1. instanceof 关键字的作用
instanceof 是 Java 的保留关键字。它的作用是测试它左边的对象是否是它右边的类的实例,返回 boolean 的数据类型。
boolean result = obj instanceof class
当 obj 为 Class 的对象,或者是其直接或间接子类,或者是其接口的实现类,结果result 都返回 true,否则返回false。
注意一点:编译器会检查 obj 是否能转换成右边的class类型,如果不能转换则直接报错,如果不能确定类型,则通过编译,具体看运行时定。
obj 必须为引用类型,只能作为对象的判断,不能是基本类型。
int i = 0;
System.out.println(i instanceof Integer);//编译不通过
System.out.println(i instanceof Object);//编译不通过
源码参考:JavaSE 8 instanceof 的实现算法:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-6.html#jvms-6.5.instanceof
2. Java自动装箱和拆箱
什么是装箱拆箱,这里不做源码层面解读,源码解读在JavaPub公众号发出。这里通过讲解 int 和 Interger 区别,解答Java自动装箱和拆箱。
自动装箱 ----- 基本类型的值 → 包装类的实例
自动拆箱 ----- 基本类型的值 ← 包装类的实例
- Integer变量必须实例化后才能使用,而int变量不需要
- Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值 。
- Integer的默认值是null,int的默认值是0
Java中8种基本数据类型。左边基本类型,右边包装类型。

在面试中:
下面这段代码的输出结果是什么?
public class Main {
public static void main(String[] args) {
Integer i1 = 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1==i2);
System.out.println(i3==i4);
}
}
//true
//false
输出结果表明i1和i2指向的是同一个对象,而i3和i4指向的是不同的对象。此时只需一看源码便知究竟,下面这段代码是Integer的valueOf方法的具体实现:
public static Integer valueOf(int i) {
if(i >= -128 && i <= IntegerCache.high)
return IntegerCache.cache[i + 128];
else
return new Integer(i);
}
private static class IntegerCache {
static final int high;
static final Integer cache[];
static {
final int low = -128;
// high value may be configured by property
int h = 127;
if (integerCacheHighPropValue != null) {
// Use Long.decode here to avoid invoking methods that
// require Integer's autoboxing cache to be initialized
int i = Long.decode(integerCacheHighPropValue).intValue();
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - -low);
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
}
private IntegerCache() {}
}
从这2段代码可以看出,在通过valueOf方法创建Integer对象的时候,如果数值在[-128,127]之间,便返回指向IntegerCache.cache中已经存在的对象的引用;否则创建一个新的Integer对象。
上面的代码中i1和i2的数值为100,因此会直接从cache中取已经存在的对象,所以i1和i2指向的是同一个对象,而i3和i4则是分别指向不同的对象。
注意,Integer、Short、Byte、Character、Long这几个类的valueOf方法的实现是类似的。 Double、Float的valueOf方法的实现是类似的(没有缓存数值,这里的数值想想都有很多,不适合缓存)。
3. 重载和重写区别
重载和重写是一个特别好理解的概念,这里说一个通俗的解答方式
重载(Overload):首先是位于一个类之中或者其子类中,具有相同的方法名,但是方法的参数不同,返回值类型可以相同也可以不同。
- 方法名必须相同
- 方法的参数列表一定不一样。
- 访问修饰符和返回值类型可以相同也可以不同。
其实简单而言:重载就是对于不同的情况写不同的方法。 比如,同一个类中,写不同的构造函数用于初始化不同的参数。
public class JavaPubTest {
public void out(){
System.out.println("参数"+null);
}
//参数数目不同
public void out(Integer n){
System.out.println("参数"+n.getClass().getName());
}
//参数类型不同
public void out(String string){
System.out.println("参数"+string.getClass().getName());
}
public void out(Integer n ,String string){
System.out.println("参数"+n.getClass().getName()+","+string.getClass().getName());
}
//参数顺序不同
public void out(String string,Integer n){
System.out.println("参数"+string.getClass().getName()+","+n.getClass().getName());
}
public static void main(String[] args) {
JavaPubTest javaPubTest = new JavaPubTest();
javaPubTest.out();
javaPubTest.out(1);
javaPubTest.out("string");
javaPubTest.out(1,"string");
javaPubTest.out("string",1);
}
}
**重写(Overriding)**发生在父类子类之间,比如所有类都是继承与Object类的,Object类中本身就有equals、hashcode、toString方法等。在任意子类中定义了重名和同样的参数列表就构成方法重写。
- 方法名必须相同,返回值类型必须相同。
- 参数列表必须相同。
- 访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为public,那么在子类中重写该方法就不能声明为protected。
- 子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为private和final的方法。
- 构造方法不能被重写。
4. equals与==区别
"=="是判断两个变量或实例是不是指向同一个内存空间。
"equals"是判断两个变量或实例所指向的内存空间的值是不是相同。
除了这俩点,这个问题大概率会引出以下问题:
为什么重写equals还要重写hashcode?
通过上面俩条我们知道 "equals"是判断两个变量或实例所指向的内存空间的值是不是相同。 但是一些特殊场景,我们需要对比俩个对象是否相等,例如:User user1 = new User(); User user2 = new User(); user1 和 user2 对比。这是我们就需要重写 equals 方法。
所以可以通过重写equals()方法来判断对象的值是否相等,但是有一个要求:equals()方法实现了等价关系,即:
- 自反性:对于任何非空引用x,x.equals(x)应该返回true;
- 对称性:对于任何引用x和y,如果x.equals(y)返回true,那么y.equals(x)也应该返回true;
- 传递性:对于任何引用x、y和z,如果x.equals(y)返回true,y.equals(z)返回true,那么x.equals(z)也应该返回true;
- 一致性:如果x和y引用的对象没有发生变化,那么反复调用x.equals(y)应该返回同样的结果;
- 非空性:对于任意非空引用x,x.equals(null)应该返回false;
到这里也是一个很正常的操作,但是当我们要用到 HashSet 等集合时。存储的对象我们需要用 hashcode 判断对象是否存在,如果使用 Object 默认的hashcode方法,那我们同样属性的俩个用户一定是不相等的(例如下面user3、user4),因为内存地址不同,这并不符合我们的业务,所以决定了重写 hashcode 的必要性。
User user3 = new User("JavaPub", "man", "1996-08-28")
User user4 = new User("JavaPub", "man", "1996-08-28")
5. 谈谈NIO和BIO区别
致力于大白话说清楚。NIO和BIO是一个相对有点抽象的概念,如果你对网络有点了解,理解起来可能会更顺畅。首先说一下基本
BIO:同步阻塞IO,每一个客户端连接,服务端都会对应一个处理线程,对于没有分配到处理线程的连接就会被阻塞或者拒绝。相当于是一个连接一个线程。
NIO:同步非阻塞IO,基于Reactor模型,客户端和channel进行通信,channel可以进行读写操作,通过多路复用器selector来轮询注册在其上的channel,而后再进行IO操作。这样的话,在进行IO操作的时候再用一个线程去处理就可以了,也就是一个请求一个线程。
Reactor模型是什么?
- 基于池化思想,避免为每个连接创建线程,连接完成后将业务处理交给线程池处理
- 基于IO复用模型,多个连接共用同一个阻塞对象,不用等待所有的连接。遍历到有新数据可以处理时,操作系统会通知程序,线程跳出阻塞状态,进行业务逻辑处理
.简单来说:Reactor线程模型的思想就是基于IO复用和线程池的结合。
AIO:(一般都会把AIO和NIO、BIO放一块比较,这里简单提一下。)异步非阻塞IO,相比NIO更进一步,完全由操作系统来完成请求的处理,然后通知服务端开启线程去进行处理,因此是一个有效请求一个线程。
那么怎么理解同步和阻塞?
首先,可以认为一个IO操作包含两个部分:
- 发起IO请求
- 实际的IO读写操作
同步和异步在于第二个,实际的IO读写操作,如果操作系统帮你完成了再通知你,那就是异步,否则都叫做同步。
阻塞和非阻塞在于第一个,发起IO请求,对于NIO来说通过channel发起IO操作请求后,其实就返回了,所以是非阻塞。
NIO和BIO是非常重要的计算机知识,学习后会对整个计算机的理解更近一步,一次学会终身受益。JavaPub会单独写一篇深入图解NIO和BIO。
网上看到一个例子(一定要看,会对你有所帮助):
一辆从 A 开往 B 的公共汽车上,路上有很多点可能会有人下车。司机不知道哪些点会有哪些人会下车,对于需要下车的人,如何处理更好?
1. 司机过程中定时询问每个乘客是否到达目的地,若有人说到了,那么司机停车,乘客下车。 ( 类似阻塞式 )
2. 每个人告诉售票员自己的目的地,然后睡觉,司机只和售票员交互,到了某个点由售票员通知乘客下车。 ( 类似非阻塞 )
很显然,每个人要到达某个目的地可以认为是一个线程,司机可以认为是 CPU 。在阻塞式里面,每个线程需要不断的轮询,上下文切换,以达到找到目的地的结果。而在非阻塞方式里,每个乘客 ( 线程 ) 都在睡觉 ( 休眠 ) ,只在真正外部环境准备好了才唤醒,这样的唤醒肯定不会阻塞。
建议阅读:
https://www.cnblogs.com/aspirant/p/6877350.html
https://www.cnblogs.com/shoshana-kong/p/11228555.html
6. String、StringBuffer、StringBuilder 的区别是什么?
String是Immutable类的典型实现,被声明为 final class,除了hash这个属性其它属性都声明为final。它的不可变性,所以例如拼接字符串时候会产生很多无用的中间对象,如果频繁的进行这样的操作对性能有所影响。
StringBuffer、StringBuilder就是解决String的这个性能问题。
StringBuffer 是线程安全的,本质是一个线程安全的可修改的字符序列,把所有修改数据的方法都加上synchronized。
StringBuilder 线程不安全,但是性能更好。
7. 泛型是什么,有什么特点
泛型在编码中有非常广泛的使用(jdk5引入),你一定经常能见到类似这种写法 <T> 。
泛型提供了编译时类型安全检测机制,允许在编译时检测到非法的类型。本质是参数化类型。
- 把类型当作是参数一样传递
- <数据类型>只能是引用类型
泛型:就是一种不确定的数据类型。
泛型的好处:
- 省略了强转的代码。
- 可以把运行时的问题提前到编译时期。
引入泛型主要想实现一个通用的、可以处理不同类型的方法
泛型擦除:
泛型时提供给javac编译器使用的,用于限定集合的输入类型,让编译器在源代码级别上,避免向集合中插入非法数据。但编译器编译完带有泛型的java程序后,生成的class文件中不再带有泛型信息,以此使程序运行效率不受影响,这个过程称为擦除。
JVM并不知道泛型的存在,因为泛型在编译阶段就已经被处理成普通的类和方法; 处理机制是通过类型擦除,擦除规则:
-
若泛型类型没有指定具体类型,用Object作为原始类型;
-
若有限定类型< T exnteds XClass >,使用XClass作为原始类型;
-
若有多个限定< T exnteds XClass1 & XClass2 >,使用第一个边界类型XClass1作为原始类型;
8. final 有哪些用法
final关键字有四个常见用法。
final修饰一个类
当 final 关键字用来修饰一个类的时候,表明这个类不能有任何的子类,也就是说这个类不能被继承。
final类中的所有成员方法都会被隐式地指定为final方法,也就是说一个类如果是final的,那么其中所有的成员方法都无法进行覆盖重写。
public final class 类名称 {
// ...
}
final修饰一个方法
当 final 关键字用来修饰一个方法的时候,这个方法就是最终方法,也就是不能被覆盖重写。
修饰符 final 返回值类型 方法名称(参数列表) {
// 方法体
}
注意:对于类、方法来说,abstract 关键字和 final 关键字不能同时使用,因为矛盾。
final修饰一个局部变量
一旦使用 final 用来修饰局部变量,那么这个变量就不能进行更改「一次赋值,终生不变」。
- 对于基本类型来说,不可变说的是变量当中的数据不可改变;
- 对于引用类型来说,不可变说的是变量当中的地址值不可改变。
final修饰一个成员变量
对于成员变量来说,如果使用 final 关键字修饰,那么这个变量也照样是不可变。
- 由于成员变量具有默认值,所以用了 final 之后必须手动赋值,不会再给默认值了;
- 对于 final 的成员变量,要么使用直接赋值,要么通过构造方法赋值,必须二者选其一;
- 必须保证类当中所有重载的构造方法都最终会对 final 的成员变量进行赋值。
9. 说一下Java注解
在Java编程中,注解非常常见,注解的本质是什么?
注解大致分为以下三种:
-
Java原生注解 如@Override,@Deprecated 等。大多用于 [标记] 和 [检查] 。
-
第三方注解,如 Spring、Mybatis等定义的注解(@Controller,@Data)。
-
自定义注解。
Java原生除了提供基本注解,还提供了 meta-annotation(元注解)。这些类型和它们所支持的类在java.lang.annotation包中可以找到。
- @Target
- @Retention
- @Documented
- @Inherited
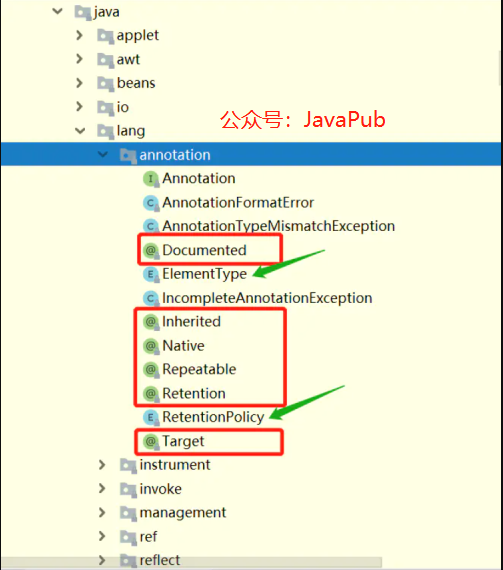
一般比较常用的有 @Target,@Retention。@Target表示这个注解可以修饰那些地方(比如类、方法、成员变量),@Retention 主要是设置注解的生命周期。
这是你一定会被问,
- 有使用过注解吗?
- 你是怎么使用的?
注解有一个非常常见的使用场景,大家可以用这个来理解学习。
场景一:自定义注解+拦截器 实现登录校验
实现功能:
接下来,我们使用springboot拦截器实现这样一个功能,如果方法上加了@LoginRequired,则提示用户该接口需要登录才能访问,否则不需要登录。
首先定义一个LoginRequired注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface LoginRequired {
}
然后写两个简单的接口,访问sourceA,sourceB资源
@RestController
public class IndexController {
@GetMapping("/sourceA")
public String sourceA(){
return "你正在访问sourceA资源";
}
@GetMapping("/sourceB")
public String sourceB(){
return "你正在访问sourceB资源";
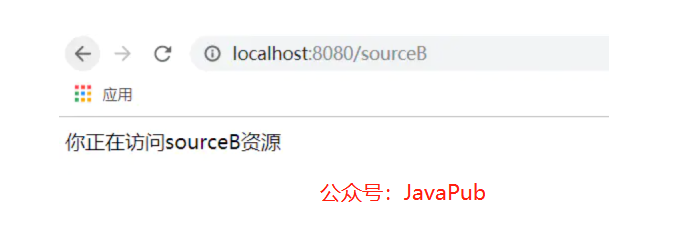
}
}
很简单的俩个接口,没添加拦截器之前成功访问
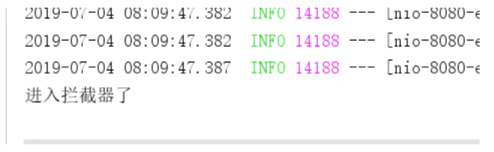
实现 spring 的 HandlerInterceptor 类先实现拦截器,但不拦截,只是简单打印日志,如下:
public class SourceAccessInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("进入拦截器了");
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
}
}
实现spring类 WebMvcConfigurer,创建配置类把拦截器添加到拦截器链中
@Configuration
public class InterceptorTrainConfigurer implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new SourceAccessInterceptor()).addPathPatterns("/**");
}
}
拦截成功如下
在 sourceB 方法上添加我们的登录注解 @LoginRequired
@RestController
public class IndexController {
@GetMapping("/sourceA")
public String sourceA(){
return "你正在访问sourceA资源";
}
@LoginRequired
@GetMapping("/sourceB")
public String sourceB(){
return "你正在访问sourceB资源";
}
}
简单实现登录拦截逻辑
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("进入拦截器了");
// 反射获取方法上的LoginRequred注解
HandlerMethod handlerMethod = (HandlerMethod)handler;
LoginRequired loginRequired = handlerMethod.getMethod().getAnnotation(LoginRequired.class);
if(loginRequired == null){
return true;
}
// 有LoginRequired注解说明需要登录,提示用户登录
response.setContentType("application/json; charset=utf-8");
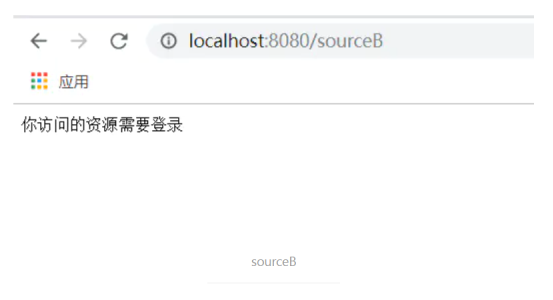
response.getWriter().print("你访问的资源需要登录");
return false;
}
运行成功,访问sourceB时需要登录了,访问sourceA则不用登录。

场景二:自定义注解+AOP 实现日志打印
先导入切面需要的依赖包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
定义一个注解@MyLog
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyLog {
}
定义一个切面类,见如下代码注释理解:
@Aspect // 1.表明这是一个切面类
@Component
public class MyLogAspect {
// 2. PointCut表示这是一个切点,@annotation表示这个切点切到一个注解上,后面带该注解的全类名
// 切面最主要的就是切点,所有的故事都围绕切点发生
// logPointCut()代表切点名称
@Pointcut("@annotation(com.javapub.blog.MyLog)")
public void logPointCut(){};
// 3. 环绕通知
@Around("logPointCut()")
public void logAround(ProceedingJoinPoint joinPoint){
// 获取方法名称
String methodName = joinPoint.getSignature().getName();
// 获取入参
Object[] param = joinPoint.getArgs();
StringBuilder sb = new StringBuilder();
for(Object o : param){
sb.append(o + "; ");
}
System.out.println("进入[" + methodName + "]方法,参数为:" + sb.toString());
// 继续执行方法
try {
joinPoint.proceed();
} catch (Throwable throwable) {
throwable.printStackTrace();
}
System.out.println(methodName + "方法执行结束");
}
}
在步骤二中的IndexController写一个sourceC进行测试,加上我们的自定义注解:
@MyLog
@GetMapping("/sourceC/{source_name}")
public String sourceC(@PathVariable("source_name") String sourceName){
return "你正在访问sourceC资源";
}
启动springboot web项目,输入访问地址
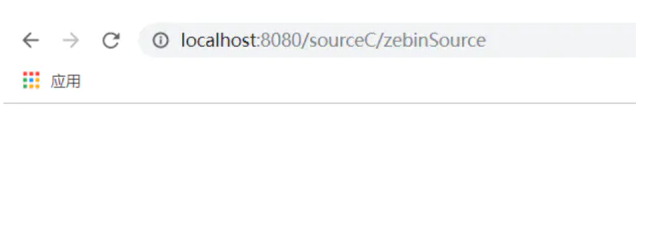

有些面试官喜欢问,注解三要素是哪些:
- 注解声明、
- 使用注解的元素、
- 操作注解使其起作用(注解处理器)
10. Java创建对象有几种方式
Java中有5种创建对象的方式,下面给出它们的例子

使用new关键字
User user = new User();
使用Class类的newInstance方法
我们也可以使用Class类的newInstance方法创建对象。这个newInstance方法调用无参的构造函数创建对象。
Employee emp = (Employee) Class.forName("org.javapub.blog.Employee").newInstance();
或者
Employee emp2 = Employee.class.newInstance();
使用Constructor类的newInstance方法
和Class类的newInstance方法很像, java.lang.reflect.Constructor类里也有一个newInstance方法可以创建对象。我们可以通过这个newInstance方法调用有参数的和私有的构造函数。
Constructor<Employee> constructor = Employee.class.getConstructor();
Employee emp3 = constructor.newInstance();
使用clone方法
无论何时我们调用一个对象的clone方法,jvm就会创建一个新的对象,将前面对象的内容全部拷贝进去。用clone方法创建对象并不会调用任何构造函数。
要使用clone方法,我们需要先实现Cloneable接口并实现其定义的clone方法。
Employee emp4 = (Employee) emp3.clone();
使用反序列化
当我们序列化和反序列化一个对象,jvm会给我们创建一个单独的对象。在反序列化时,jvm创建对象并不会调用任何构造函数。
为了反序列化一个对象,我们需要让我们的类实现Serializable接口
ObjectInputStream in = new ObjectInputStream(new FileInputStream("data.obj"));
Employee emp5 = (Employee) in.readObject();
联系JavaPub:
- 如果需要下载CSDN资料又没有积分可以JavaPub留言,JavaPub帮你下载
推荐阅读:
【Java基础】10道不得不会的Java基础面试题
【Java并发】10道不得不会的Java并发基础面试题
【MySQL】10道不得不会的MySQL基础面试题
【ElasticSearch】10道不得不会的ElasticSearch面试题
【JVM】10道不得不会的JVM面试题
【Spring】10道不得不会的Spring面试题
https://rodert.github.io/JavaPub-Interview/#
最后
以上就是正直爆米花最近收集整理的关于【Java基础面试】10道不得不会的Java基础面试题的全部内容,更多相关【Java基础面试】10道不得不会内容请搜索靠谱客的其他文章。








发表评论 取消回复