目录
1 协同过滤算法
1.1 CF与 User/Item 推荐算法区别
1.2 UserCF
1.3 ItemCF
2 评价指标
3 基于userCF与itemCF电影推荐
3.1 MovieLens数据集
3.2 userCF代码实现
3.3 K值影响实验(userCF)
3.4 itemCF代码实现
3.5 K值影响实验(itemCF)
4 userCF与itemCF比较
4.1 区别
4.2 适用场景
4.3 模型融合
1 协同过滤算法
1.1 CF与 User/Item 推荐算法区别
基于用户内容的推荐:利用用户人口统计学特征(age/gender/..)计算相似度
基于物品内容的推荐:利用物品的本身属性内容计算相似度
CF:通过分析用户的行为数据,根据用户对物品的偏好发现用户和物品的相关性,基于这种关联推荐(userCF/item/CF)
1.2 UserCF
a 找到与目标用户兴趣相似的用户集合
相似度计算 (Jaccard公式、余弦相似度)
相似度改进,惩罚热门物品(对冷门物品的相同喜爱,更能表明两个人相似)
但是,如果计算目标用户与所有用户的相似度,复杂度太高O(u*u),实际上很多用户并没有与其有相同的感兴趣物品。
建立物品-用户倒排表(统计每一件物品对应的用户集合),遍历找到N(u)&N(v)不为零的,两两用户的相似度值C[u][v]+1,再除以分母。C[u][v]=N,表示用户u与v共有的爱好物品数量为N个。
b 找到该集合中所有用户喜欢的物品,然后排除目标用户已经看过的物品,推荐排在前n的物品
计算感兴趣度:
,其中wuv表示用户u和v的相似度,rvi表示用户v对物品i的兴趣度
1.3 ItemCF
原理同userCF,先计算物品的相似度(被喜欢的人越多越相似),然后生成推荐列表
相似度计算:
改进:惩罚热门物品,利于挖掘长尾物品
建立用户--物品倒排表(统计每一个用户对应的物品列表)
兴趣度:
2 评价指标
,
,
recall: 预测准确的占真实列表的比例
precision:预测正确的占预测集合的比例
coverage:预测的物品类别占总类别的比例
还有一些其他的评价指标:
用户满意度(无法离线测量:在线或用户调查)、多样性、新颖性、精细度、信任度、实时性、健壮性...
3 基于userCF与itemCF电影推荐
3.1 MovieLens数据集
MovieLens数据集(Small: 100,000 ratings and 3,600 tag applications applied to 9,000 movies by 600 users. )
userid/ movieid/ ratings/ timestrap,这里忽略时间戳,只利用前三个特征构造用户行为矩阵。
这里只预测目标用户的可能会进行评分的电影,不涉及评分高低,所以感兴趣度计算公式rank[movie] += wuv*rvi,rvi置为1,忽略评分高低的影响。
3.2 userCF代码实现
# coding = utf-8
# userCF推荐算法实现
import random
import math
from operator import itemgetter
class UserBasedCF():
# 初始化相关参数
def __init__(self,K,N):
# 找到与目标用户兴趣相似的K个用户,为其推荐10部电影
self.n_sim_user = K
self.n_rec_movie =N
# 将数据集划分为训练集和测试集
self.trainSet = {} #格式{user1:{movie1:ratings},{user2...},....}
self.testSet = {}
# 用户相似度矩阵
self.user_sim_matrix = {}
self.movie_count = 0
#print('Similar user number = %d' % self.n_sim_user)
#print('Recommneded movie number = %d' % self.n_rec_movie)
# 读文件得到“用户-电影”数据
def get_dataset(self, filename, pivot=0.75):
trainSet_len = 0
testSet_len = 0
for line in self.load_file(filename):
user, movie, rating, timestamp = line.split(',')
if random.random() < pivot: #按照3:1划分训练集和测试集
self.trainSet.setdefault(user, {}) #setdefault,自动创建key,若已存在,则不改变原value
self.trainSet[user][movie] = float(rating)
trainSet_len += 1
else:
self.testSet.setdefault(user, {})
self.testSet[user][movie] = float(rating)
testSet_len += 1
#print('Split trainingSet and testSet success!')
#print('TrainSet = %s' % trainSet_len)
#print('TestSet = %s' % testSet_len)
#return self.trainSet ,self.testSet
# 读文件,返回文件的每一行
def load_file(self, filename):
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i == 0: # 去掉文件第一行的title
continue
yield line.strip('rn')
#print('Load %s success!' % filename)
# 计算用户之间的相似度
def calc_user_sim(self):
# 构建“电影-用户”倒排表
# key = movieID, value = list of userIDs who have seen this movie
#print('Building movie-user table ...')
movie_user = {}
for user, movies in self.trainSet.items():
for movie in movies:
if movie not in movie_user:
movie_user[movie] = set()
movie_user[movie].add(user)
#print('Build movie-user table success!')
self.movie_count = len(movie_user)
#print('Total movie number = %d' % self.movie_count)
#print('Build user co-rated movies matrix ...')
for movie, users in movie_user.items():
for u in users:
for v in users:
if u == v:
continue
self.user_sim_matrix.setdefault(u, {})
self.user_sim_matrix[u].setdefault(v, 0)
self.user_sim_matrix[u][v] += 1
#print('Build user co-rated movies matrix success!')
# 计算相似性
#print('Calculating user similarity matrix ...')
for u, related_users in self.user_sim_matrix.items():
for v, count in related_users.items():
self.user_sim_matrix[u][v] = count / math.sqrt(len(self.trainSet[u]) * len(self.trainSet[v]))
#print('Calculate user similarity matrix success!')
# 针对目标用户U,找到其最相似的K个用户,产生N个推荐
def recommend(self, user):
K = self.n_sim_user
N = self.n_rec_movie
rank = {}
watched_movies = self.trainSet[user]
# v=similar user, wuv=similar factor
for v, wuv in sorted(self.user_sim_matrix[user].items(), key=itemgetter(1), reverse=True)[0:K]:
#用user中的第2个item即相似度值,作为key进行排序
#for movie,rvi in self.trainSet[v].items(): #查看相似用户v的所有感兴趣电影,若目标用户已经看过,则跳过
for movie in self.trainSet[v]:
if movie in watched_movies:
continue
rank.setdefault(movie, 0)#若没看过,将该电影添加到推荐电影列表,
#rank[movie] += wuv*rvi #目标用户对该电影的感兴趣值=相似度*感兴趣度,遍历所有相似用户求和
rank[movie] += wuv #这里只是预测用户是否会对电影打分,与分数高低无关,所以rvi设为1,只用相似度wuv计算
return sorted(rank.items(), key=itemgetter(1), reverse=True)[0:N] #返回感兴趣值的topN
# 产生推荐并通过准确率、召回率和覆盖率进行评估
def evaluate(self):
print("Evaluation start ...")
N = self.n_rec_movie
# 准确率和召回率
hit = 0
rec_count = 0
test_count = 0
# 覆盖率
all_rec_movies = set()
for i, user, in enumerate(self.trainSet):
test_movies = self.testSet.get(user, {})
rec_movies = self.recommend(user)
for movie, w in rec_movies:
if movie in test_movies:
hit += 1
all_rec_movies.add(movie)
rec_count += N
test_count += len(test_movies)
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
#print('precisioin=%.4ftrecall=%.4ftcoverage=%.4f' % (precision, recall, coverage))
return [precision, recall, coverage]tips:

3.3 K值影响实验(userCF)
评价指标:
以 precision、recall、coverage作为评价指标,查看K值对算法性能的影响
实验设计:
K的取值范围[5,10,20,40,80,160,320],每个K值下,进行五次数据划分并评估,最终取五次的平均值作为结果返回
%%time
#探索数值K的影响(推荐电影数量固定 10)
#评价指标:precision/recall/coverage的变化
#实验设计:每个K进行5次数据集的划分并试验,最后取平均值作为最终结果
rating_file = 'G:\DATAMINING\cv-spyder\recsys\ml-latest-small\ratings.csv'
Mat=[]
K_range=[5,10,20,40,80,160,320]
for K in K_range:
M=[]
for i in range(5):
userCF = UserBasedCF(K)
userCF.get_dataset(rating_file) #获取并划分数据集
userCF.calc_user_sim() #计算用户相似度矩阵
m=userCF.evaluate() #评估
M.append(m) #记录每个数据集上的指标向量
Mat.append([sum([h[2] for h in M])/5,sum([h[1] for h in M])/5,sum([h[0] for h in M])/5])#求均值
#性能曲线
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from IPython.display import display
p=pd.DataFrame(Mat,columns=lab)
display(p)
num = np.array(Mat)
num=num.T
#plt.rcParams['font.sans-serif'] = ['SimHei']#可以plt绘图过程中中文无法显示的问题
plt.figure(figsize=(10, 5), dpi=80)
lab=["precision","recall","coverage"]
x_label=K_range
for row in range(len(num)):
markes = ['-o', '-s', '-^']
plt.plot(x_label,num[row],markes[row],label =lab[row])
plt.legend()#显示图例,如果注释,即使设置了图例仍然不显示
#plt.show()#显示图片,如果注释,即使设置了图片仍然不显示试验结果:
| K | precision | recall | coverage |
|---|---|---|---|
| 1 | 0.137767 | 0.028525 | 0.118131 |
| 3 | 0.119704 | 0.050324 | 0.208131 |
| 5 | 0.096540 | 0.059061 | 0.243311 |
| 10 | 0.063466 | 0.067299 | 0.278230 |
| 20 | 0.042393 | 0.072281 | 0.299016 |
| 40 | 0.027079 | 0.074613 | 0.308852 |
| 80 | 0.018715 | 0.073908 | 0.306000 |
| 160 | 0.013107 | 0.071625 | 0.295180 |
| 320 | 0.010070 | 0.067540 | 0.278459 |
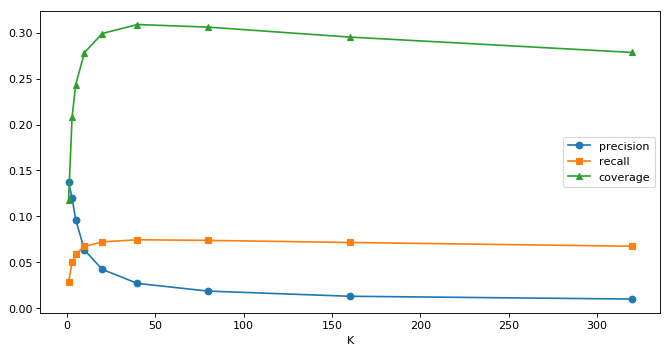
总结:
1 覆盖率:随着K值增大,考虑的相似用户越多,涉及到的物品种类增大覆盖率就越大,但是之后覆盖率会减小,因为K值超过一定大小,考虑的用户足够多,预测的物品就越来越接近主流大众的喜爱,偏向于热门物品,所以覆盖率会减小。
2 召回率:随着K值增大,其考虑的相似用户的数量增大,就越来越能挖掘出用户的喜好,召回率先上升,后趋于平稳保持不变。recall对K值的变化不是非常敏感。只要K值达到某阈值后影响不大
3 准确率:K值为5时准确度达到最大,随着K值增大,准确率逐渐下降。因为K值越大,预测的物品就偏向于热门物品,个性化推荐就越弱,最终准确率趋于平稳。
4改进:可以增加数据量;可以探究推荐的电影数量对算法的影响。
3.4 itemCF代码实现
# 基于项目的协同过滤推荐算法实现
import random
import math
from operator import itemgetter
class ItemBasedCF():
# 初始化参数
def __init__(self,K,N):
# 找到相似的20部电影,为目标用户推荐10部电影
self.n_sim_movie = K
self.n_rec_movie = N
# 将数据集划分为训练集和测试集
self.trainSet = {}
self.testSet = {}
# 用户相似度矩阵
self.movie_sim_matrix = {}
self.movie_popular = {}
self.movie_count = 0
#print('Similar movie number = %d' % self.n_sim_movie)
#print('Recommneded movie number = %d' % self.n_rec_movie)
# 读文件得到“用户-电影”数据
def get_dataset(self, filename, pivot=0.75):
trainSet_len = 0
testSet_len = 0
for line in self.load_file(filename):
user, movie, rating, timestamp = line.split(',')
if(random.random() < pivot):
self.trainSet.setdefault(user, {})
self.trainSet[user][movie] = rating
trainSet_len += 1
else:
self.testSet.setdefault(user, {})
self.testSet[user][movie] = rating
testSet_len += 1
#print('Split trainingSet and testSet success!')
#print('TrainSet = %s' % trainSet_len)
#print('TestSet = %s' % testSet_len)
# 读文件,返回文件的每一行
def load_file(self, filename):
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i == 0: # 去掉文件第一行的title
continue
yield line.strip('rn')
#print('Load %s success!' % filename)
# 计算电影之间的相似度
def calc_movie_sim(self):
for user, movies in self.trainSet.items():
for movie in movies:
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
self.movie_popular[movie] += 1 #计算电影的流行度(被评分的次数越多,越流行)
self.movie_count = len(self.movie_popular)
#print("Total movie number = %d" % self.movie_count)
#统计电影相似矩阵
#这里的用户-电影倒排表,就是trainset数据
for user, movies in self.trainSet.items():
for m1 in movies:
for m2 in movies:
if m1 == m2:
continue
self.movie_sim_matrix.setdefault(m1, {})
self.movie_sim_matrix[m1].setdefault(m2, 0)
self.movie_sim_matrix[m1][m2] += 1
#print("Build co-rated users matrix success!")
# 计算电影之间的相似性
#print("Calculating movie similarity matrix ...")
for m1, related_movies in self.movie_sim_matrix.items():
for m2, count in related_movies.items():
# 注意0向量的处理,即某电影的用户数为0
if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:
self.movie_sim_matrix[m1][m2] = 0
else:
self.movie_sim_matrix[m1][m2] = count / math.sqrt(self.movie_popular[m1] * self.movie_popular[m2])
#print('Calculate movie similarity matrix success!')
# 针对目标用户U,找到K部相似的电影,并推荐其N部电影
def recommend(self, user):
K = self.n_sim_movie
N = self.n_rec_movie
rank = {}
watched_movies = self.trainSet[user]
for movie, rating in watched_movies.items():
for related_movie, w in sorted(self.movie_sim_matrix[movie].items(), key=itemgetter(1), reverse=True)[:K]:
if related_movie in watched_movies:
continue
rank.setdefault(related_movie, 0)
rank[related_movie] += w * float(rating) #感兴趣度=电影相似度*评分
return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]
# 产生推荐并通过准确率、召回率和覆盖率进行评估
def evaluate(self):
#print('Evaluating start ...')
N = self.n_rec_movie
# 准确率和召回率
hit = 0
rec_count = 0
test_count = 0
# 覆盖率
all_rec_movies = set()
for i, user in enumerate(self.trainSet):
test_moives = self.testSet.get(user, {})
rec_movies = self.recommend(user)
for movie, w in rec_movies:
if movie in test_moives:
hit += 1
all_rec_movies.add(movie)
rec_count += N
test_count += len(test_moives)
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
return [precision, recall, coverage]
#print('precisioin=%.4ftrecall=%.4ftcoverage=%.4f' % (precision, recall, coverage))3.5 K值影响实验(itemCF)
同样做5次交叉实验,取平均值作为评价指标.
| K | precision | recall | coverage |
|---|---|---|---|
| 1 | 0.161944 | 0.041188 | 0.170656 |
| 3 | 0.131698 | 0.057918 | 0.239410 |
| 5 | 0.105631 | 0.061193 | 0.252295 |
| 10 | 0.082598 | 0.065140 | 0.269639 |
| 20 | 0.067028 | 0.065909 | 0.273213 |
| 40 | 0.057787 | 0.064942 | 0.268164 |
| 80 | 0.051798 | 0.063022 | 0.261148 |
| 160 | 0.050158 | 0.060166 | 0.249574 |
| 320 | 0.048807 | 0.057707 | 0.238525 |
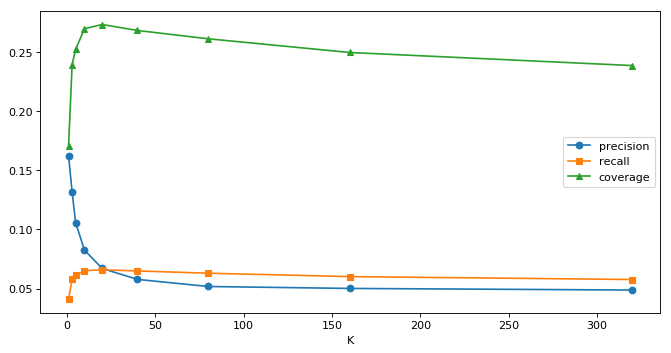
总结:
1 K值对itemCF三个指标的影响,同userCF的影响规律一致。
2 在本数据集中,itemCF相比于userCF,precision有一定的提升,但是recall以及coverage的最大值均不及userCF。但这并不是普适规律,不同的推荐任务和数据集,模型的表现也会有变化。
4 userCF与itemCF比较
4.1 区别
userCF:更着重于反映和用户兴趣相似的小群体的关注热点(社会化),存在用户冷启动问题
itemCF: 更着重于维护用户的历史兴趣(个性化),存在物品冷启动问题
4.2 适用场景
物品更新快,个性化需求不强烈(userCF适用):如新闻资讯,维护item相关性表需要快速更新,很难在技术上实现
长尾物品丰富,个性化需求强烈(itemCF适用):如电商/图书/电影,不需要流行度帮助用户判断,利用个人领域知识推荐效果更好
存储代价方面:用户较多适用itemCF,物品较多适用userCF
产品需求:需要提供推荐解释itemCF更适用
4.3 模型融合
在现实推荐系统中,为了缓解在线推荐系统的压力、增加计算速度,每个推荐系统都是由多个推荐引擎组成,每个推荐引擎使用一种推荐模型或完成一种推荐任务。最终的推荐结果可以根据场合使用其中一种推荐模型的结果,也可以线性加权对所有推荐模型进行融合,也可以分区对不同的人群使用不同的推荐策略。
最后
以上就是欢呼铃铛最近收集整理的关于【基于协同过滤算法的电影推荐】1 协同过滤算法2 评价指标3 基于userCF与itemCF电影推荐4 userCF与itemCF比较的全部内容,更多相关【基于协同过滤算法的电影推荐】1内容请搜索靠谱客的其他文章。








发表评论 取消回复