本文主要介绍SQL Server的恒定时间恢复算法(Constant TIme Recovery)以及传统的ARIES算法。
ARIES算法作为最传统,应用广泛的数据库恢复算法, 在MSSQL中也有应用。但随着数据库的发展,和云数据库的兴起,传统的ARIES算法逐渐没有办法满足云数据库高可用性的特点。面对云端用户,数据库的恢复慢慢呈现出一些弱点:
- 数据库的容量逐渐提高,导致更多长事务的出现
- 商用云服务器的数量增加,出现故障在所难免
- 云数据库的维护和升级由服务供应商提供,用户很难根据停机时间调整自己的业务
- 长事务在撤销时带来的不可用性(在撤销长事务时,长事务更改的表需要长时间持有写锁来撤销,导致该表不可用),部分长事务可能需要数十个小时才能撤销完成。
面对这些问题,微软在2019年的VLDB论文Constant Time Recovery in Azure SQL Database[1]提出了恒定时间恢复算法(Constant Time Recovery, 简称CTR)。在介绍这个算法之前,先简单介绍一下MSSQL应用的传统的ARIES算法。
ARIES
Algorithms for Recovery and Isolation Exploiting Semantics[2] (简称 ARIES)是经典的数据库恢复算法,采取no-force[3](在事务提交时,脏页可以不刷到磁盘)和steal(未完成提交的事务可以修改最近提交的值)的策略,以及Write Ahead Log(简称WAL),在脏页刷到磁盘之前,有关它的log要全部刷回磁盘。为此,MSSQL在每一页中维护一个pageLSN(LSN即Log Sequence Number,递增),表示最近修改该页的log条目。而每个log条目,则维护它的更新操作,事务号,以及这个事务中它的前一个操作的log条目(previousLSN,用于撤销修改)。
同时,为了减少每次恢复的时间,数据库每隔一段时间就会自动进行checkpoint(默认的automatic checkpoint,可以修改)。在checkpoint开始的时候写入Checkpoint Begin条目到log中,并且将所有脏页刷入磁盘(这里要注意的是,被正在进行的事务pin中的脏页无法刷回磁盘)。同时,记录正在进行的事务的事务号,以及最早被修改、还未被刷入磁盘的脏页对应的pageLSN。
在数据库停机之后,ARIES就可以开始利用这些信息开始恢复了。恢复一共分成3个阶段。
分析(Analysis)
这个阶段会根据log,找到所有的在停机前还在执行的事务(active transaction),以及还未刷入磁盘的脏页的pageLSN(如果在checkpoint开始时,所有脏页都已经刷入磁盘,则这里返回checkpoint的LSN)。
重做(Redo)
从上个阶段中得到的LSN开始对所有的log重做。在对某个页进行重做时,如果该页的pageLSN比当前log的LSN要大(或等于),则说明该页已经执行过这个操作,并且成功刷新到磁盘,则不需要重新执行这个操作。同时,根据正在执行事务表以及log,为这些还在执行的事务获取其更改的表的锁。
撤销(Undo)
在重做完成之后,数据库实际上已经恢复到了停机前的状态。但是还在进行中的事务理论上是不应该继续进行了的,这些事务应该视为中止事务(aborted transaction),因此需要对它们修改的表进行撤销。在这个过程中,MSSQL对外部宣称已经可用,但由于这些正在执行的事务持有表的写锁,因此会阻塞访问这些表的事务。
根据分析阶段得到的正在进行的事务表,对每个事务操作进行撤销。同时,在撤销的时候也要写CLR log(Compensation Log Record),即撤销的log,防止在撤销的过程中再次停机。
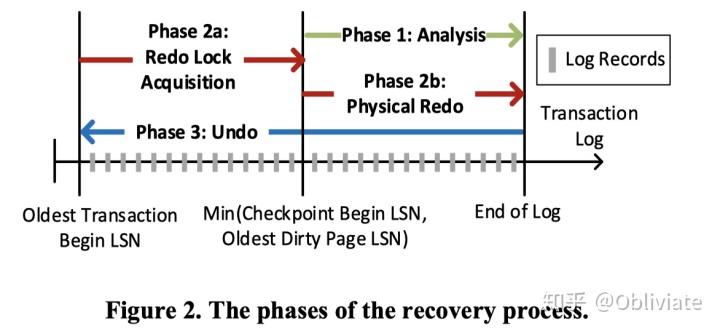
完成这三个阶段之后,数据库的恢复就算完成了。另外,值得一提的是,MSSQL支持MVCC[4][1](Multi Version Concurrency Control),在snapshot isolation下的旧版本会存在一个内存中的表里,而新事务写入的新版本则会在主表里。临时表中,每个版本的元组都有指针指向前一个版本的元组,而主表中的元组也有指针指向临时表中的旧版本元组。在停机之后,这个临时表会消失。
恒定时间恢复,实际上就是利用了这个临时表。
Constant Time Recovery
恒定时间恢复算法主要解决的问题是:在长事务存在的前提下,如何让数据库的所有表都尽快变得可用。
正如上文所提到的,对长事务的撤销需要对表持有写锁,这个写锁会阻塞新读取该元组的事务。尽管这个持有写锁的元组来自一个需要被中止的事务。但是,在支持多版本控制的系统中,尽管某个新元组被abort,但并不会妨碍其他事务访问其之前的、已提交的元组——也就是说,只要数据库恢复到多版本存在的状态,这个问题就能迎刃而解。
Persistent Version Store
在之前的恢复算法中,多版本的临时表在恢复时并不能被恢复,为了获得多版本控制的优点,恒定时间恢复算法将临时表也当作是一个内部表,写入磁盘,而在恢复时,也能通过ARIES算法恢复。同时,为了减少这个临时表的大小,文章引入in-row versioning,即在主表的条目中直接保存该条目的多版本delta信息,在恢复的时候,可以通过这些信息来找到之前的版本。当然,对于一些复杂的表、属性信息太多的表,它们的多版本信息仍然存在临时表中。在数据库停机,并且再度恢复时,只要恢复了这个临时表,新的事务就能正常的读取所有表中的元组,而不需要等待漫长的撤销过程。
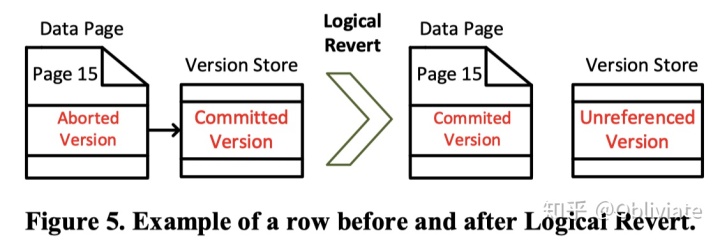
Logical Revert
对于临时表中的,已经aborted的元组,系统需要自动将其回收掉。Logical Revert会通过比较两个版本的区别,并计算出它们之间的delta值,并重新apply到主表的aborted的元组上。如下图:
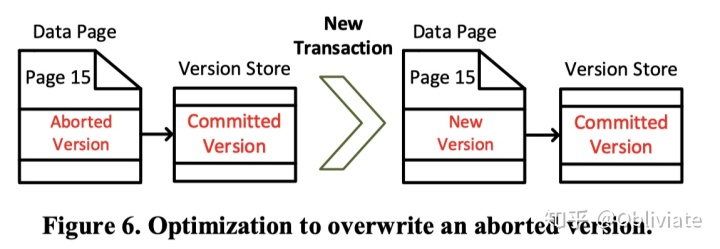
如果在Logical Revert之前,有新事务要修改这个aborted的值,则直接替换掉该aborted的值。如下图。
Background Cleanup
介绍完撤销的具体操作,还需要介绍系统清理多版本信息的机制。这个机制主要负责撤销已经中止的事务及其相关操作和Logical Revert临时表中不再需要的多版本信息。
对于in-row的多版本信息而言,系统有一个Page Free Space(简称PFS)来记录所有记有多版本信息的页。清理进程会每隔一段时间运行一次(根据设置)。在运行前,它会对中止的事务做一个快照(即它开始之后再中止的事务,不会被它清理),扫描PFS,找到需要清理的页,用Logical Revert进行版本清理。如果某个中止事务的所有操作都已经被撤销,则把它移出中止事务表中。
对于off-row的多版本信息(即存在临时表里的多版本信息),系统中维护了一个哈希表追踪这个表中的所有页对应的pageid以及这个page中存的最大的事务号(事务号是递增的,最大即最新的事务)。当某个页被写满,而且它对应的事务号比正在执行和中止事务表中所有的事务号都要小,即没有事务能再读到这些版本信息,则这一页可以被回收。当数据库停机之后,这个哈希表会消失,但是我们不会根据这些页来重新计算这个表,而是构建一个新的哈希表,并且每个页对应的事务号为分析阶段得到的最新的事务号,尽管这样做会让回收变慢,但是在系统工作一段时间之后还是能回复正常。
总结
本文大概介绍了恒定时间恢复算法的大体思路,论文中还提到了很多方面的优化,比如对短事务不适合应用这个算法,以及对与一些无法版本化的log如系统设置修改、空间分配回收、更新表的schema等的优化。
参考
- ^abConstant Time Recovery in Azure SQL Database https://15721.courses.cs.cmu.edu/spring2020/papers/10-recovery/p2143-antonopoulos.pdf
- ^Algorithms for Recovery and Isolation Exploiting Semantics https://en.wikipedia.org/wiki/Algorithms_for_Recovery_and_Isolation_Exploiting_Semantics
- ^No force https://en.wikipedia.org/wiki/No-force
- ^MSSQL https://dbdb.io/db/microsoft-sql-server
最后
以上就是包容乌冬面最近收集整理的关于mssql 线程数量500多_MSSQL:恒定时间数据库恢复算法的全部内容,更多相关mssql内容请搜索靠谱客的其他文章。








发表评论 取消回复