一:单个特征
1.数据标准化:
数据归一化处理是数据挖掘的一项基础工作,不同评价指标往往有不同的量纲和量纲单位,这种情况会影响到数据分析的结果,
为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性.原始数据经过数据标准化后,
各指标处于同一数量级下,适合进行综合对比评价。
(1)线性归一化:线性函数将原始数据线性化的方法转换到【0,1】的范围。公式如下:
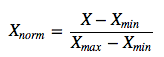
其中Xnorm为归一化后的数据,X为原始数据,Xmax、Xmin分别为原始数据集的最大值和最小值。
x_train=sklearn.preprocessing.Min_MaxScaler.fit_transform(x_train) 检验:print x_train
附.x_train=sklearn.preprocessing.MaxAbsScaler.transform(x_train) 该方法是将数据归一化到【-1,1】之间
(2)0均值标准化:0均值标准化方法将原始数据集标准化位均值为0,方差为1的数据集。公式如下:
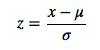
其中,μ、σ分别为原始数据集的均值和方法,这种标准化的要求是原始数据尽量服从正太分布,不然,效果很糟糕。
x_train=sklearn.preprocessing.scale(x_train) 检验:x_train.mean(axis=0),x_train.std(axis=0)
3.离散化
一些数据挖掘算法,特别是某些分类算法(如:ID3,Apripri算法等),要求数据是分类属性形式,这样,
常常需要将连续属性变换成分类属性,即连续属性离散化。
离散化目标:
1.确定分类数。
2.如何将连续属性值映射到这些分类值
离散化方法分类:
根据数据是否包含类别信息可以把他们分成有监督的数据和无监督的数据。
有监督的离散化要考虑类别信息而无监督的离散化不需要。
无监督离散化:假设属性的取值空间为X={x1,x2,x3...},离散化之后的类标号是Y={y1,y2,y3.......},则无监督离散化的情况就是X已知而Y未知;
(1)等宽算法:根据用户指定的区间数目k,将属性的值域[MIN(X)-MAX(X)]划分为k个区间,并使每个区间的宽度相等,
即都等于MAX(X)-MIN(X)/K.缺点是容易受离群点的影响而使性能不佳。
(2)等频算法:也是根据用户自定义的区间数目,将属性的值域分为k个小区间,他要求落在每个区间的对象数目相等。
譬如,属性的取值区间内共有M个点
则等频区间所划分的K个小区域内,每个区域含有MK个点。
(3)K-means聚类算法:首先由用户指定离散化产生的区间数目K,K-均值算法首先从数据集中随机找出K个数据作为K
个初始区间的重心;然后,根据这些重心的欧式距离,对所有的对象聚类:如果数据x距重心
Gi最近,则将x划归所代表的那个区间;然后重新计算各区间的重心Gi,并利用新的重心重新聚类所有样本。
逐步循环,直到所有区间的重心不再随算法循环而改变为止。
4.Dummy Coding(虚拟变量):这个暂时没有找到较好的资料,以后补充。
5.缺失值
造成缺失值的原因:机械原因和人为原因,机械原因是由于机械原因导致的数据收集或保存的失败造成的数据缺失,比如数据存储的失败,存储器损坏,机械故障导致某段时间数据未能收集(对于定时数据采集而言)。人为原因是由于人的主观失误、历史局限或有意隐瞒造成的数据缺失,比如,在市场调查中被访人拒绝透露相关问题的答案,或者回答的问题是无效的,数据录入人员失误漏录了数据。
造成缺失值的原因是多方面的,主要可能有一下几种:
(1)有些信息暂时无法获取
(2)有些信息是倍遗漏的
(3)有些对象的某个或某些属性是不可用的
(4)有些信息被认为是不重要的,获取这些信息的代价太大
(5)系统实时行性能要求较高
缺失值的处理方法:
(一)删除元组
简单来说就是,将存在遗漏信息属性值的对象删除,从而得到一个完备的信息表,但是这种方式有很大的弊端,就是他是以减少历史数据来换取信息的完备,会造成资源的大量浪费,丢弃了大量隐藏在这些对象中的信息。
(二)数据补齐
这类方法是用一定的值去填补控制,从而使得信息表完备,通常基于统计学原理,根据决策表中其余对象取值的分布情况来对一个控制进行填补,譬如用其余属性的平均值来进行补充,一般的补充方法:
(1)人工填写:由于最了解数据的还是用户自己,因此这个方法产生数据偏离最小,可能是填补效果最好的一种,然而一般来说,该方法很费时,当数规模很大时候,
空值很多的时候,这个方法时不可行的,
(2)特殊值填补 :将空值作为一种特殊的属性值来处理,他不同于其他的任何属性值,如所有的空值都用unknown填补,但是这样会导致严重的数据偏离,一般不推荐使用。
(3)平均值填补:将信息表中的属性分为数值属性和非数值属性来分别进行处理,如果空值时数值型的,就根据该属性在其他所有对象的取值的平均值来填补该缺失的属性值,如果空值时非数值型的,就根据统计学中的众数原理,用该属性在其他所有对象的取值次数最多的值来填补该缺失的属性值。
(4)热卡填补: 对于一种包含空值的对象,热卡填充法在完整数据中找到一个和他最相似的对象,然后用这个相似对象的值进行填补。不同的问题可能会选用不同的标准来找相似进行判定。该方法概念上很简单,且利用了数据见的关系来进行空值估计,这个方法的缺点在于难以定义相似标准,主观因素较多。
(5)k最近距离邻法: 先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的k个样本,将这k个值加权平均来估计该样本的缺失数据。
(6)回归: 基于完整的数据集,建立回归方程,对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充,当变量不是线性相关或预测变量高度相关时会导致有偏差的估计。
(三)不处理: 直接在包含空值的数据上进行数据挖掘,这类方法包括贝叶斯网络和人工神经网络
6.数据变换
(1)log
(2)指数
(3)Box-Cox
最后
以上就是健忘太阳最近收集整理的关于特征工程总结(二):预处理的全部内容,更多相关特征工程总结(二)内容请搜索靠谱客的其他文章。








发表评论 取消回复