前提
通过id去重,而不是整条数据
id由SnowFlake算法生成,参考之前的文章SnowFlake算法在数据链路中的应用
需求
在实时平台的各个环节中,由于网络或其他问题,有时会出现数据重复的情况,本质上是由于at least once保障机制造成的。例如
flume agent之间的数据传输,如果网络不稳定,有可能出现src_agent发送数据超时而导致重发,但实际上dest_agent已经收到,造成了数据重复
kafka producer发送数据且设置acks=all,在replication完成之间就由于超时而返回失败,如果retries不为0,那么重发之后数据也会有重复
通常我们会在业务端通过幂等性来保证数据的唯一性,比如Mysql的primary key,或者是HBase的rowkey。但在流式计算或某些存储介质中,没有办法天然的实现数据去重,这时就需要在数据计算/存储之前将重复的数据移除或忽略
思路
我司的实时数据都是通过Flume采集,并且通过SnowFlake算法给每条数据分配一个全局唯一长整型的id,这个id会被带到整条数据链路中,所以考虑开发一个去重模块,对实时数据进行预处理。又由于id是数字类型,可以考虑用BitSet进行存储以提高查询效率和减小开销,但java.util.BitSet的最大长度是Integer.MAX_VALUE(2GB),再长的话内存开销就会非常巨大,所以需要对id进行分段存储
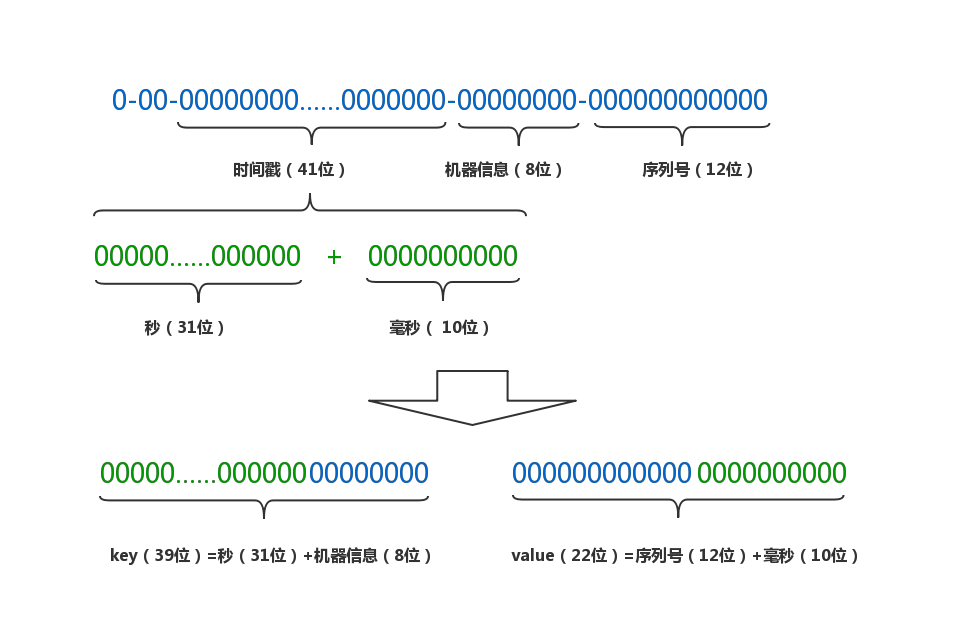
原始的id是由41位时间戳,8位机器信息和12位序列号组合而成
将时间戳拆分成秒和毫秒两部分
重新将各部分组合成新的key-value pair,秒数和机器信息拼接为一个long型的key,序列号和毫秒数拼接成一个int型的value。假设对n分钟内的数据进行过滤,则key的最大个数为n*60*256,value最大个数为4096*1000
将相同key的数据放到同一个BitSet中,并缓存到LoadingCache中
代码
注意:DuplicationEliminator中的常量必须与SnowFlake算法中一致,否则会解析错位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86import java.util.BitSet;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import org.apache.commons.lang3.tuple.Pair;
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;
public class DuplicationEliminator{
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; // 序列号占用的位数
private final static long MACHINE_BIT = 8; // 机器标识占用的位数
private final static long MILLI_BIT = 10; // 毫秒占用的位数
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long TIMESTMP_LEFT = MACHINE_LEFT + MACHINE_BIT;
/**
* 起始的时间戳2014/01/01,可以在30年之内保证id的位数维持在18位
*/
private final static long START_STMP = 1388505600000L;
private static final int RETENTION_MINUTES = 1;
private LoadingCache cache = CacheBuilder.newBuilder()//
.refreshAfterWrite(RETENTION_MINUTES, TimeUnit.MINUTES)// 给定时间内没有被读/写访问,则回收。
.build(new CacheLoader() {
private final static int MAX_MILLI = (int) (-1L ^ (-1L << MILLI_BIT));
@Override
public BitSet load(Long key) throws ExecutionException{
// BitSet的值由sequence和毫秒数组合而成,每秒并发不超过1000的topic一般sequence都是0,所以这里设置初始size是MAX_MILLI,避免过多的扩容开销
return new BitSet(MAX_MILLI);
}
});
public boolean putIfAbsent(long id) throws ExecutionException{
Pair pair = idToPair(id);
long key = pair.getKey();
int value = pair.getValue();
BitSet existingValues = cache.get(key);
if (existingValues.get(value)) {
return false;
} else {
existingValues.set(value);
return true;
}
}
/**
* 将id转成key-value pair,便于cache存储
*
* @param id
* @return
*/
private Pair idToPair(long id){
int seq = (int) ((id) & ~(-1L << SEQUENCE_BIT));
long machineId = (id >> MACHINE_LEFT) & ~(-1L << MACHINE_BIT);
long timestamp = (id >> TIMESTMP_LEFT) + START_STMP;
long sec = timestamp / 1000;
int milli = (int) (timestamp % 1000);
return Pair.of(sec << MACHINE_BIT | machineId, seq << MILLI_BIT | milli);
}
/**
* @param pair
* @return
*/
private long pairToId(Pair pair){
long key = pair.getKey();
int value = pair.getValue();
long sequence = (value) >> MILLI_BIT;
long machineId = (key) & ~(-1L << MACHINE_BIT);
long timestamp = (key >> MACHINE_BIT) * 1000 + (value & ~(-1L << MILLI_BIT));
return (timestamp - START_STMP) << TIMESTMP_LEFT // 时间戳部分
| machineId << MACHINE_LEFT // 机器标识部分
| sequence; // 序列号部分
}
}
测试
测试写入一亿个id,耗时48.4s,QPS=206.6万,内存占用68MB,性能和开销都还可以
1
2
3
4
5
6
7
8
9
10
11public static void main(String[] args) throws ExecutionException, InterruptedException{
DuplicationEliminator eliminator = new DuplicationEliminator();
Stopwatch watch = Stopwatch.createStarted();
for (int i = 0; i < 1_0000_0000; i++) {
long id = IdGenerator.generateId();
if (!eliminator.putIfAbsent(id)) {
System.out.println("duplicated: " + id);
}
}
System.out.println(watch.elapsed(TimeUnit.MILLISECONDS));
}
最后
以上就是笨笨项链最近收集整理的关于海量数据去重 oracle,海量数据去重的全部内容,更多相关海量数据去重内容请搜索靠谱客的其他文章。








发表评论 取消回复