传统的统计语言模型有一些缺点:
1.由于维度灾难(特别是离散变量),在高维下,数据的稀缺性导致统计语言模型存在很多为0的条件概率,传统的统计语言模型也花费大量的精力来处理这个,包括平滑,插值,回退等方法
2.语言模型的参数个数随着阶数呈指数增长,所以一般这个模型的阶数不会很高,这样n-gram无法建立长远的关系
3.n-gram无法建模出多个相似词的关系,比如在训练集中有: the cat is walking in the bedroom,但是用n-gram预测时,遇到:the dog was running in a room这个句子,并不会因为两个句子相似就让该句子的概率变高
这篇NNLM使训练得到的模型比传统的统计语言模型使用n-gram能建模更远的关系,并且考虑到了词与词之间的相似性,一些相似的词获得了自然的平滑。前者是因为神经网络的结果使得,后者是因为使用了词向量。
词向量
下面先介绍词向量(distributed representation for words),本文中单词的特征向量是吧单词映射为具有一定维度的实数向量(比如50,100维,这里记为m),每个词都和一个特征向量相关联,词向量初始化可以为随机的数,文中介绍也可以使用一些先验知识来初始化它。随着训练结束,词向量便获得了。词向量的引入使得n-gram的离散空间变成了连续空间,并且两个相似的词之间他们的词向量也相似,所以当训练完毕后,一个句子和其他相似的句子都获得了概率。而把词映射到词向量是作为整个网络的第一层,后面会看到。
本质上,N-gram对词的表示是one-hot的离散表示,存在问题:
1.参数空间随着N成指数增长,当词典数量较大时存在维度灾难问题;
2.无法理解词与词之间的内在联系,无法建模出多个相似词的关系。
通过引入词向量,从离散表示到连续表示,可以解决上面的问题:
1. one-hot向量维度大小与词典成正比,稠密向量大小是固定值(50~300);
2. 稠密向量各维度值是实数,不限于0和1,可以表示连续空间,可以通过计算距离度量词与词之间的相似度。类似的思想还有IR中的向量空间模型(VSM)。
作者:EternalX
链接:https://www.jianshu.com/p/22d35745cfd7
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Bengio 用了一个三层的神经网络来构建语言模型,同样也是n-gram模型,如下图:
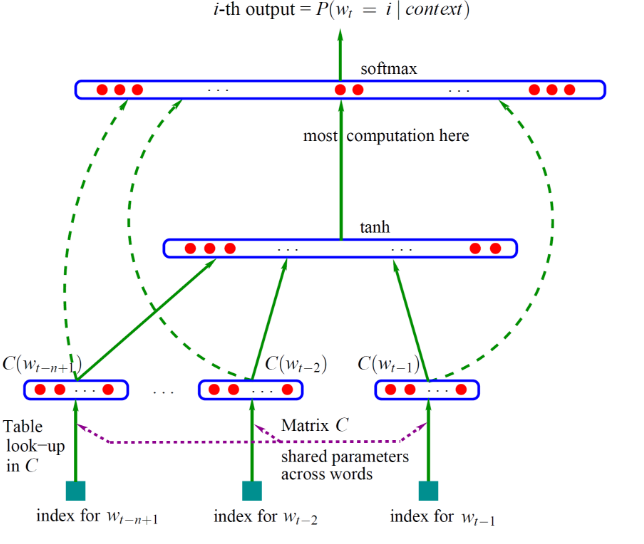
图中最下方的Wt-1 ---Wt-n+1就是前n-1个词。现在需要根据这已知的n-1个词来预测下一个词Wt。
为了直观理解这个模型,举个例子:假如现在我们要根据文档中出现的前3个词,来预测下一个词,则初始化部分:
- 对所有的文档提取单词制作一个词汇表,每个单词有一个唯一的索引,即词汇表每行代表一个单词的embedding
- 模型参数的初始化,除了神经网络的连接权重初始化之外,还需要初始化一张词汇表
前向传播部分:
- 从文档中提取模型的输入,输入为3个单词的索引
- 模型根据输入的3个单词的索引从词汇表中拿出对应的embedding表示得到每个单词的词向量。假如我们打算将每个单词转换为1个50维的向量,此时3个单词就转换为3个向量,每个都是50维
- 将3个50维向量串在一起,变为一个150维的向量作为网络的输入层,传送给隐层
- 对于隐层的每个神经元,150维输入乘以与每个神经元链接的权重,求和后输入给tanh激活函数
- 激活函数的输出作为输出层(softmax)的输入,假设隐层的神经元数量为300个,则输出层的输入就是一个300维向量
- softmax层的单元数量为词汇表的单词数量|V|,对每个单元,输入的300维乘以与输出层连接的权重后求和,并计算各个单元输出的概率作为下一个单词是第i个单词的概率。在这里例子中为300维向量,则对第i个softmax单元,权重为1个300维向量,转置后与输入相乘
- 每一个softmax‘单元的输出为一个概率值,指示在词汇表中第i个单词为第四个单词的概率
- 整个softmax的输出为一个长度为词汇表长度的概率分布,其和为1
反向部分:
- 计算softmax的代价函数,用softmax的输出向量与真实的第四个单词的1-hot向量做点乘再取-log
- 使用BP,一层一层求出网络连接权重的偏导数,并使用梯度下降更新
- 对词向量层也需要求偏导数使用梯度下降来更新词向量表,整个过程反复迭代,词汇表就得到了不断的更新
注:实际使用中隐层和softmax的输入还要加上一个bias
下面用稍微数学化的语言进行描述:
设y为未经过softmax归一后的输出,则:
最后
以上就是正直大侠最近收集整理的关于A Neural Probabilistic Language Model ------阅读笔记公式推导的全部内容,更多相关A内容请搜索靠谱客的其他文章。








发表评论 取消回复