这一讲主要是针对单变量的线性回归来讲两个基本概念:损失函数(cost function)、梯度下降(Gradient Descent)
1 Cost Function
定义例如以下: 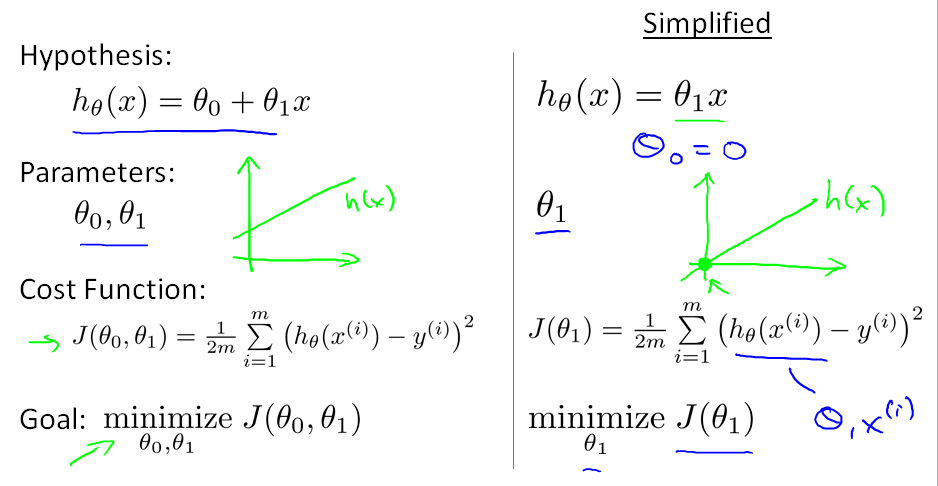
左图为cost function的定义。右边为仅仅有一个參数的h(x)的情况。
cost function的作用的评价一个回归函数好坏用的,详细来说就是评价回归函数h(x)的參数选对没。
这里J(theta)也能够称作squared error function。这里把J(theta)定义为平方误差的形式主要是为了后面求偏导数方便与分母约分。
上面的样例中h()函数有两个參数。为了方便理解,我们把theta0=0,此时仅仅有一个能够的參数theta1。下图坐标的两条直线就是theta1取0和1时的情况。 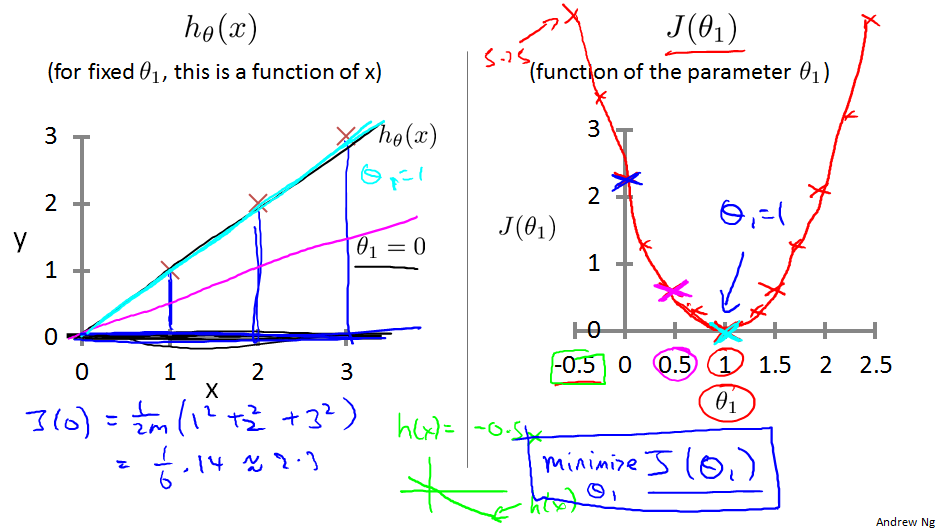
上面图右边部分是theta0=0时损失函数J(theta1)随theta1变化而得到的不同的值。
能够看到这个J(theta1)的形状为U型,当theta1时,J()取得最小值。
当theta0不为零的时候。cost function有两个变量控制它的值。此时的三维图结构例如以下图,下图也叫bowl-shape function(看去来像碗)。 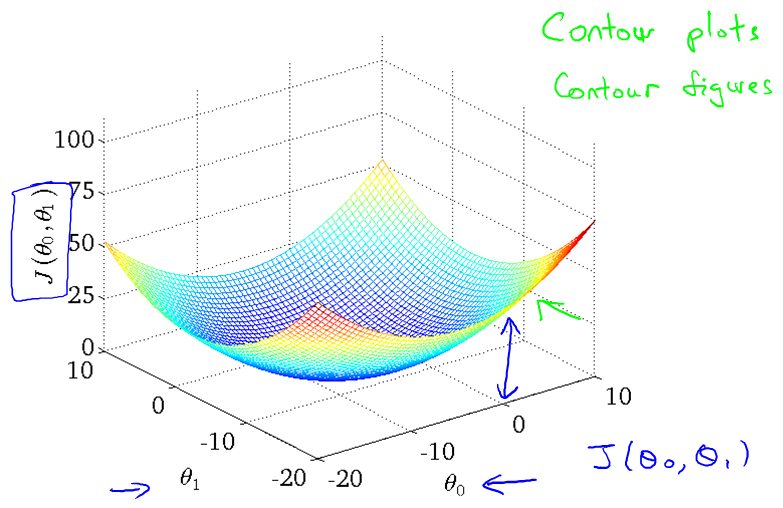
当把bowl shape function中J()值相等时相应的theta0 theta1画出来,就得到下图的,下图右边中一条线上的J()值是相等的。相似于等高线。 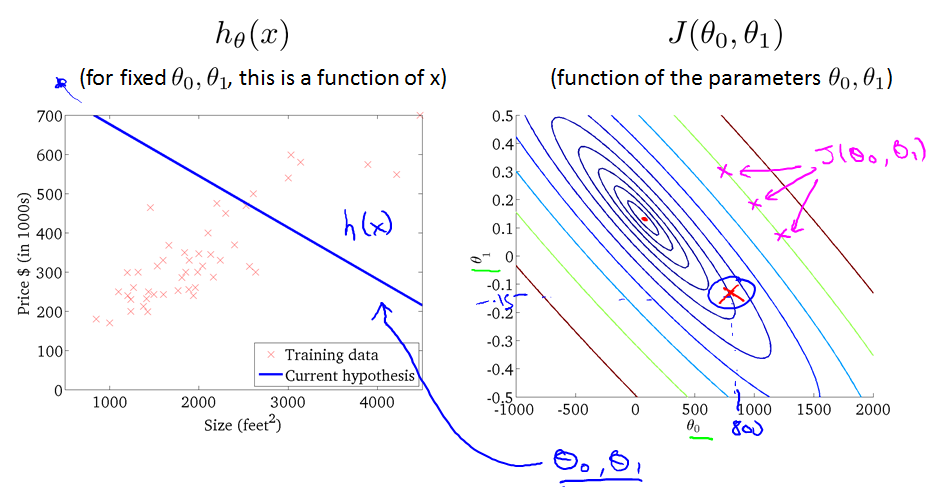
2 梯度下降Gradient Descent
回想一下之前的Cost function,我们的目标是式cost function的值最小化。
所以能够通过不断地改变theta0、theta1来实现。
例如以下图的描写叙述所看到的。

梯度下降更直观的理解就是随便在一个山上找个点,然后从这个点開始一直往低的地方走,这样总能到达一个局部的最低点。形象的描写叙述例如以下 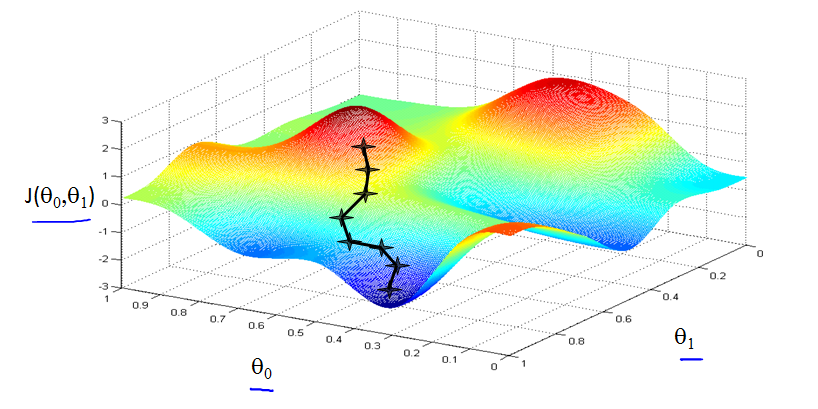
以下的梯度下降的详细算法,核心思想就是不断地迭代theta0和theta1的值以使cost function的值最小。
注意里面的alpha,这里alpha越大表示每次迭代的幅度大。能够理解为跨的步子大。

详细应用时,关于梯度下降须要特别基本的是:alpha在应用的过程中不须要改变大小,可是每次下降的幅度会越来越小,原因是求得的偏导数(梯度)会逐渐变下。
从下图右边的部分能够非常清楚的看到。 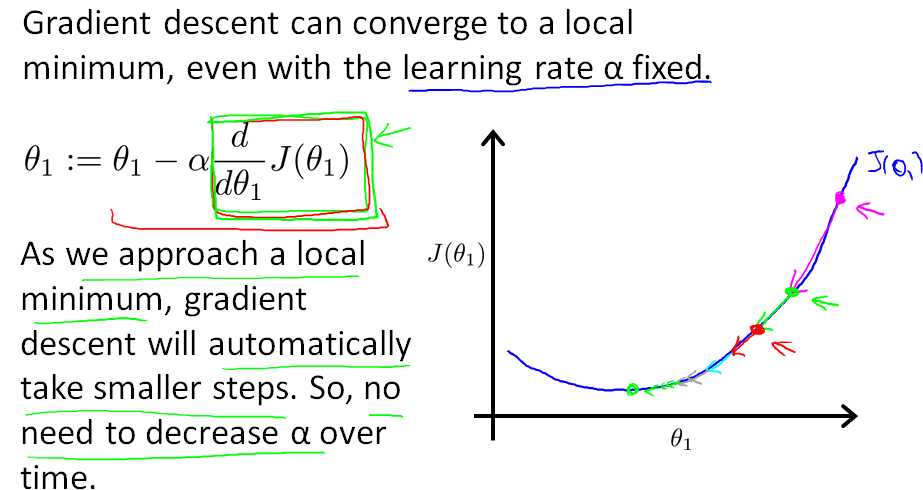
转载于:https://www.cnblogs.com/jzdwajue/p/7099504.html
最后
以上就是玩命彩虹最近收集整理的关于Andrew Ng机器学习-Linear Regression with one variable的全部内容,更多相关Andrew内容请搜索靠谱客的其他文章。








发表评论 取消回复