之前为了降低产生过拟合的可能性,我们从样本的所有属性中选取一部分属性集用以训练模型,这里介绍一种防止过拟合的不同的方法—正则化,它将会保留所有属性。
之前我们一直是通过求最大似然值确定参数(maximum likelihood (ML)):
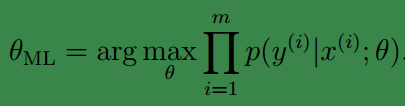
上式中的
θ
是基于频率学派(frequentist)的观点对待的,频率学派认为,
θ
是一个固定不变的常量,只是我们现在还不知道它的值,而我们的目的就是基于统计学原理获得
θ
的近似值。
然而,贝叶斯学派(Bayesian)对于
θ
的观点与频率学派的观点是不同的,它们认为,
θ
是一个未知的随机变量,因此可以给出关于
θ
分布情况的先验概率
p(θ)
,例如
θ
可能满足高斯分布等等(这是一种假设或者说是统计结果,此时并未考虑我们的训练样本).给定训练样本集
S={(x(i),y(i))}mi=1
, 我们可以求θ的后验概率:
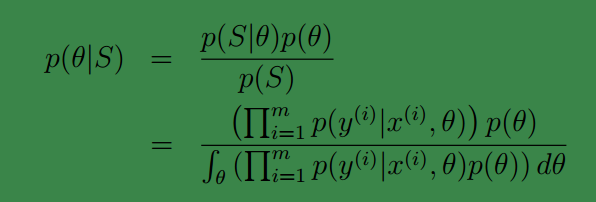
注:
1、显然
θ
是一个向量,包含了
θ1,θ2...,θm
.
2、
θ1,θ2...,θm
已经是从贝叶斯学派的角度对待,它已经不是一个固定的值,而是“有很多可能值”,例如
θ1
可以是服从正态分布的连续变量。
3、上式中,分母处的积分是对向量
θ
中的元素
θ1,θ2...,θm
积分的简写。是一个高维积分。
4、
p(y(i)|x(i),θ)
依赖于所选择的模型,如果是逻辑回归
p(y(i)|x(i),θ)=hθ(x(i))y(i)(1−hθ(x(i)))1−y(i)
.其中
hθ(x(i))=11+e−θTx(i)
如果新来一个样例特征为 x,那么为了预测 y。我们可以使用下面的公式:
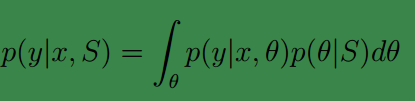
p(θ|S)
由前面的公式得到。假若我们要求期望值的话,那么套用求期望的公式即可:
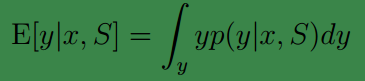
注:
大多数时候我们只需求使得
p(y|x,S)
中最大的
y
即可(在
在频率学派中最大似然估计没有将
θ
视作
而贝叶斯估计将
然而在上述贝叶斯估计方法中, 虽然公式合理优美,但后验概率
因此,为了近似的代替
θ
的后验概率分布,我们一般使用中单点估计代替,这种方法称为最大
后验概率估计(MAP (maximuma posteriori) estimate ):
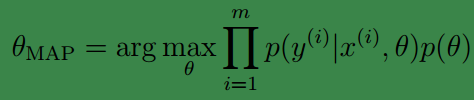
可以看出,这与我们之前的最大似然值公式很相似,只是后面多了一个关于
θ
的先验概率。
一般情况下我们认为
θ∼N(0,τ2I)
.
其实我觉得
p(θ)
可以理解为权重,对于一些噪音属性,
p(θ)
小,权重小。。。不知可否。
最后
以上就是大力大白最近收集整理的关于学习理论-贝叶斯统计和正则化的全部内容,更多相关学习理论-贝叶斯统计和正则化内容请搜索靠谱客的其他文章。








发表评论 取消回复