文章目录
- 一、写在前面
- 二、RNN原理介绍说明
- 1. RNN架构说明
- 2.RNN的数学模型及代码
- ①正向传播:输入层→隐藏层
- ②正向传播:隐藏层→输出层
- ③反向传播:输出层→隐藏层
- ④反向传播:隐藏层→输入层
- 三、RNN在实例中的应用
- 1.实例问题说明
- 2. 网络模型训练思路
- ①RNN训练数据
- ②RNN模型训练参数
- 3. 训练结果及参数调整
- ①学习速率lr调整
- ②epoch调整
- 3.数据预测
- 四、完整代码
一、写在前面
按照国际惯例,最先是免责声明:本文只是我自己学习循环神经网络RNN的理解,内容不乏不准确甚至错误的地方,希望批评指正,共同进步。
为什么写这个博客?
在一年前,写完这篇博客-基于Pytorch的机器学习Regression问题实例(附源码)最后留了一个尾巴:就是使用简单的全连接网络的时候,即使网络做的足够深,在“预测”上的表现仍然很差。
在相继学过CNN、GAN之后,看到RNN的介绍,发现这是最有希望解决“预测”问题的神经元网络模型。
二、RNN原理介绍说明
对于任何学习RNN的新手,与其上来就看一堆介绍文章,看着可能作者都似懂非懂的原理图,不如都先看看B站这个视频【循环神经网络】5分钟搞懂RNN,3D动画深入浅出
对RNN一个比较好的直观理解是:“CNN模型可以理解为人类的视觉中枢,对于单张图片来说,CNN可以很好地理解其内容。但是无论是人类的视觉神经还是听觉神经,所接受到的都是一个连续的序列(上下文),使用CNN相当于割裂了前后的联系(只注重单张图片,而忽略了上下文关联)。从而诞生了专门为处理序列的Recurrent Neural Network(RNN),每一个神经元除了当前信息的输入外,还有之前产生的记忆信息,保留序列依赖型。”
所以,上面说,RNN是最有希望解决“预测”问题的神经元网络模型,因为RNN可以关注到“上下文”之间的联系。
1. RNN架构说明
首先看一个平淡无奇的全连接网络:
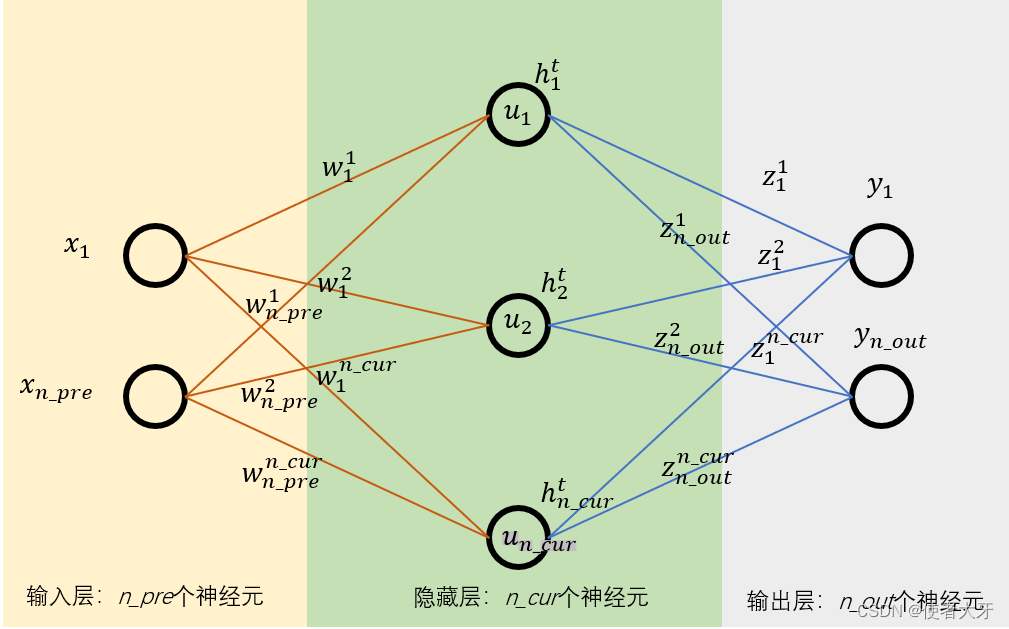
x为输入值,w为输入层权重;
隐层神经元输入u=w·x+b1,隐层输出h=f(u),f为激活函数;
最终输出y=z·h+b2,z为输出层权重。
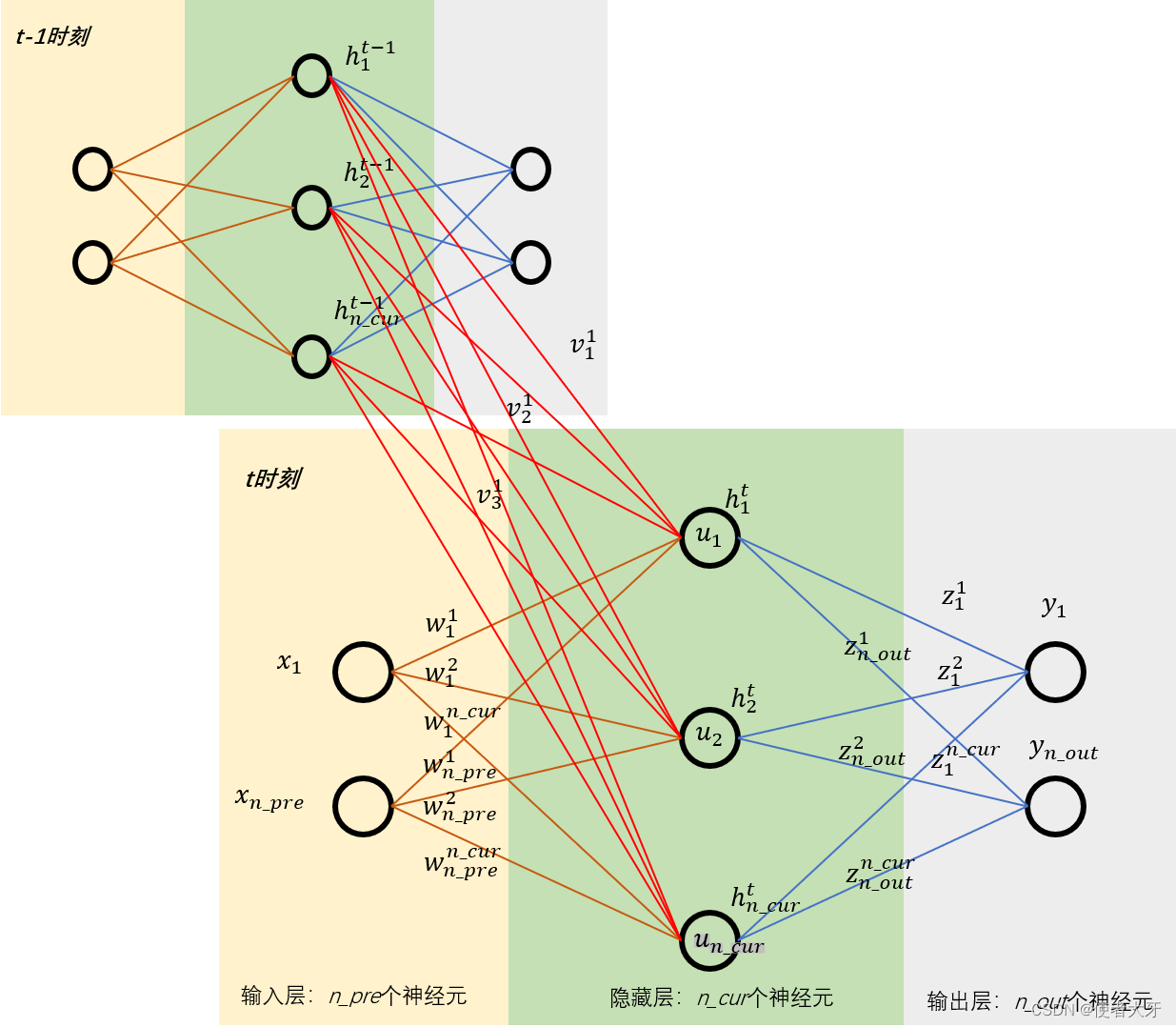
而RNN的精妙之处,就在于引进了一个新的维度:时间
RNN的设计思路就是:t-1时刻的隐层输出,接入到t时刻的隐层,这样做的目的就是让t时刻的输出y不仅取决于输入x,同时也参考了t-1时刻的隐层输出h(t-1)。同样地,t+1时刻的输出也会参考t时刻的隐层输出h(t)。
在引入时间维度后,平淡无奇的全连接网络就变成了RNN↓
2.RNN的数学模型及代码
①正向传播:输入层→隐藏层
数学模型
以下大写字母代表该变量的矩阵形式,小写字母代表该变量的单个数值。
引入上一时刻的隐层输出及权值v之后,隐层神经元输入u为:
u = w ⋅ x + v ⋅ h t − 1 + b u = w·x + v·h^{t-1} + b u=w⋅x+v⋅ht−1+b
写成矩阵形式:
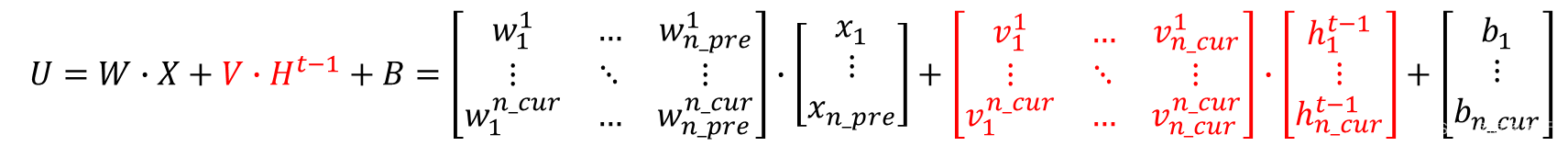
指定激活函数为tanh,t时刻隐层输出 H t H^t Ht为:
H t = t a n h ( U ) H^t=tanh(U) Ht=tanh(U)
代码
def forward(self, x, h_pre): #h_pre 上一个时刻的隐层的输出,即为h_t-1
u = np.dot(self.w, x) + np.dot(self.v, h_pre) + self.b
self.h_cur = np.tanh(u) #激活函数为tanh。h_cur即为h_t
return self.h_cur
②正向传播:隐藏层→输出层
数学模型
输出Y为:
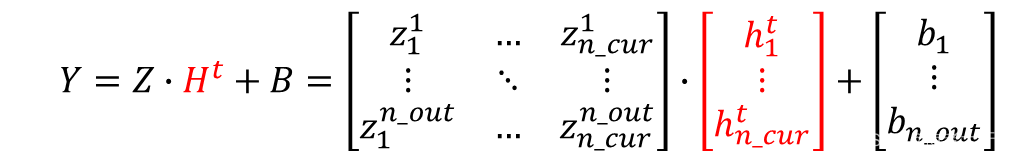
这没什么好说的,就和平淡无奇的全连接网络一样。
代码
def forward(self, h):
self.h = h #这里的h即为隐层输出h_t
self.y = np.dot(self.z, h) + self.b #输出层不加激活函数
return self.y
③反向传播:输出层→隐藏层
数学模型
选择损失函数为MSE(均方差),即loss值e=
Σ
(
y
o
u
t
p
u
t
−
y
t
r
a
i
n
)
2
Σ(y_{output}-y_{train})^2
Σ(youtput−ytrain)2
e对权值z的偏导为:
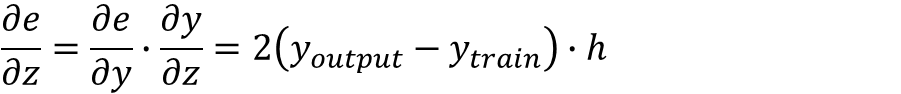
写成矩阵形式为:
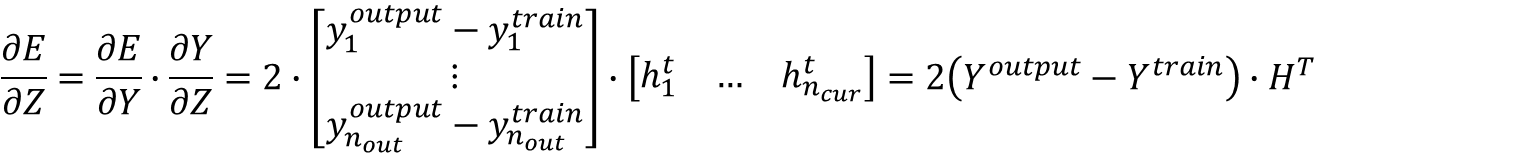
e对其他权值的偏导计算思路一致,不再赘述。
代码
def backward(self, y_real):
delta = (self.y - y_real) * 2
self.grad_z = np.dot(delta, self.h.T)
self.grad_h = np.dot(self.z.T, delta)
self.grad_b = delta
def step(self, lr):
self.z = self.z - lr * self.grad_z
self.b = self.b - lr * self.grad_b
有个细节需要说明下, 上面的代码出现了一个和Pytorch思路不同的地方:
在Pytorch中,权重梯度的计算是累加的,即上面的偏导数计算应该是self.grad_z += np.dot(delta, self.h.T)
所以用Pytorch的时候需要调用zero_grad(),每个batch手动把梯度清零。这里为了避免手动梯度清零,直接使用每次求得的梯度,不进行累加
那么为什么Pytorch要“多此一举”,默认梯度累加,还要手动梯度清零呢?这是因为在实际应用中,为了提升训练效率,在每个batch中梯度都进行累加,不同batch间进行梯度清零,这个操作算是实际工程应用的技巧。
④反向传播:隐藏层→输入层
数学模型
e对权值w的偏导为:
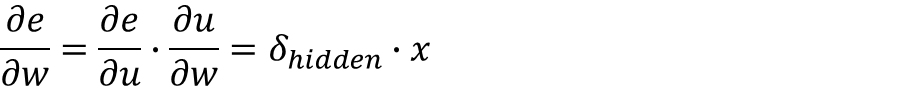
这里引入一个中间变量 δ h i d d e n δ_{hidden} δhidden:

因为隐藏层激活函数为 t a n h ( ) tanh() tanh(),即 h = t a n h ( u ) h=tanh(u) h=tanh(u)所以:

求 y = e x − e − x e x + e − x y={{e^x-e^{-x}}over{e^x+e^{-x}}} y=ex+e−xex−e−x的导数为高中数学知识,不再赘述推导。
进而 δ h i d d e n δ_{hidden} δhidden为:

最终,E对权值W的偏导写成矩阵的形式为:
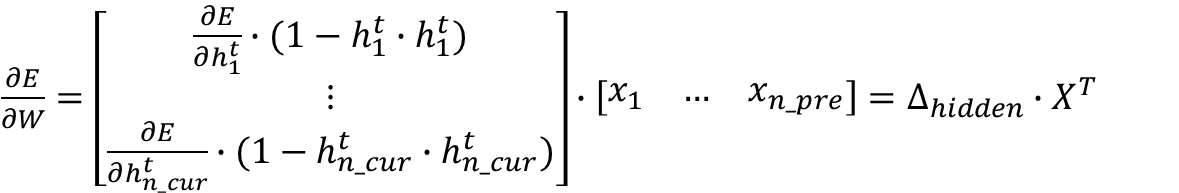
e对其他权值的偏导计算思路一致,不再赘述。
代码
def backward(self, x, h_cur, h_pre, grad_h): #grad_h为loss对h的偏导
delta = grad_h * (1-h_cur*h_cur) #delta为loss对u的偏导,tanh(u)'=1-tanh(u)*tanh(u),这是一个中间参数,便于计算后面的梯度
self.grad_w = np.dot(delta, x.T)
self.grad_v = np.dot(delta, h_pre.T)
self.grad_b = delta
self.grad_x = np.dot(self.w.T, delta)
self.grad_h_pre = np.dot(self.v.T, delta)
def step(self, lr):
self.w = self.w - lr * self.grad_w
self.v = self.v - lr * self.grad_v
self.b = self.b - lr * self.grad_b
华丽的分割线,以上RNN的理论基础的学习及基于Numpy的代码构建已经完成。下面来用搭建好的RNN模块训练数据解决实例问题。
三、RNN在实例中的应用
1.实例问题说明
仍然是这篇博客–基于Pytorch的机器学习Regression问题实例(附源码)里面的问题。
对 y = x ⋅ s i n ( x ) y = x·sin(x) y=x⋅sin(x)函数,在 0 ≤ x ≤ 6 0≤x≤6 0≤x≤6范围等间距取600个点(并加上随机数噪声)来训练神经元网络,验证神经元网络对该函数的拟合情况,并对 x > 6 x>6 x>6的范围进行预测。
2. 网络模型训练思路
①RNN训练数据
需要构建下面这样的一个csv文件,作为训练数据,共600个训练数据点:
x=[0.01,0.02,0.03…6.00]
y
=
x
⋅
s
i
n
(
x
)
+
n
o
i
s
e
y=x·sin(x)+noise
y=x⋅sin(x)+noise,noise为-0.01~0.01的随机数噪声

实在不会弄就留下邮箱吧。
再把600个点,以每6个点为一组,规划为100组数据,即:
x = [[0.01,0.02,0.03…0.06]
T
^T
T,[0.07,0.08,0.09…0.12]
T
^T
T,…[5.95,5.96,5.97…6.00]
T
^T
T]
与上面的数学模型保持一致,这里输入值x是竖向的。隐层输出h,最终输出y,也都是竖向的。
②RNN模型训练参数
batch size设定为5,即在每个batch中,时间维度需要从t=0,训练到t=4;
这里需要对batch的选取规则特殊说明下:第1个batch取第1组到第5组数据,第2个batch取第2组到第7组数据(而不是第6组到第10组),依此类推。这样iteration就是96(而不是100/5=20);
学习速率lr预设为0.0005,epoch预设为300;
输入层神经元数n_pre=6,隐藏层神经元数n_cur=20,输出层神经元数n_out=6。
3. 训练结果及参数调整
①学习速率lr调整
预设lr=0.0005,输出结果为↓(绿色为训练数据,红色为RNN模型输出数据)
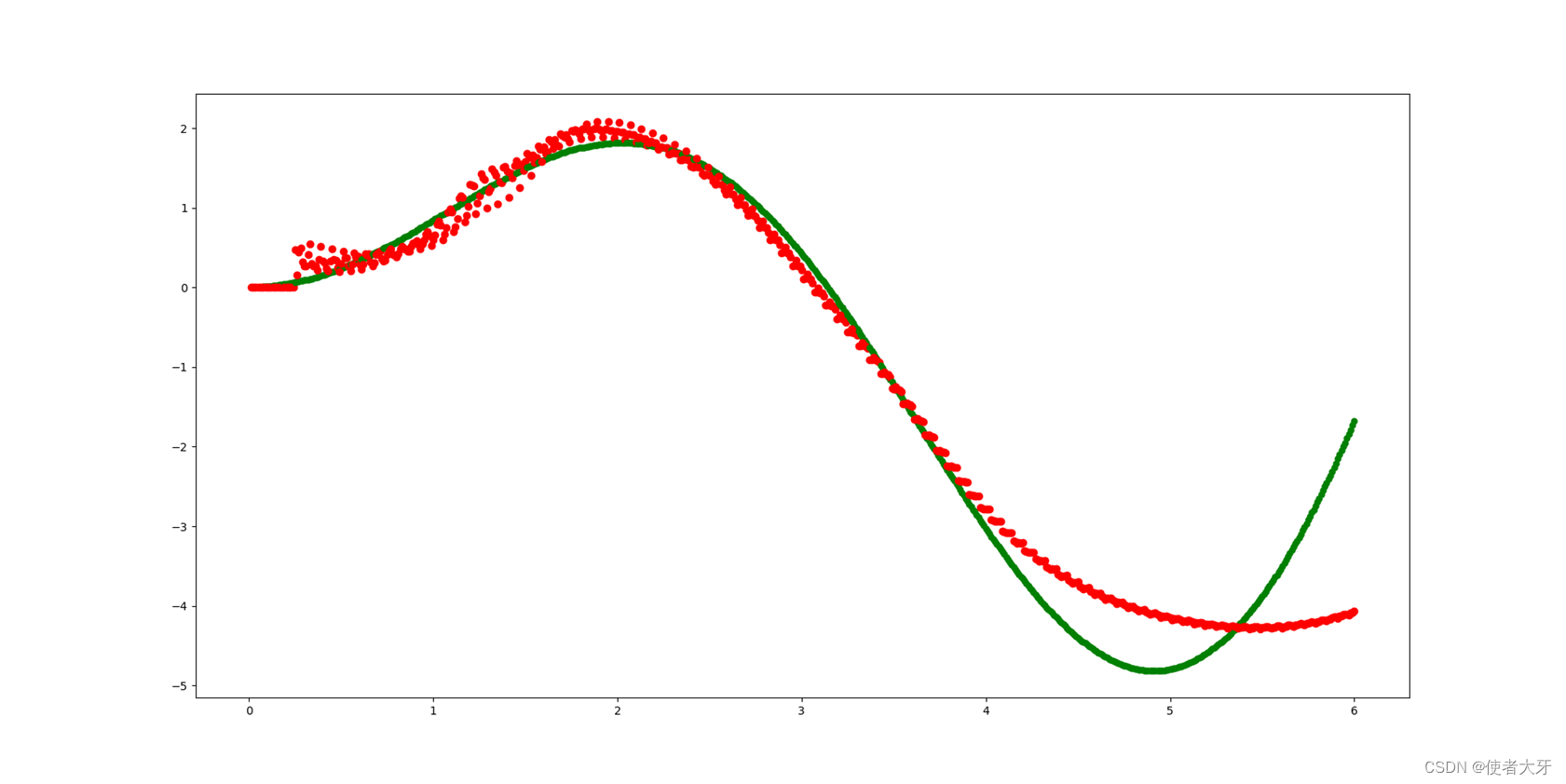
经过多次调整,基本确定lr=0.023为比较合适的值。
lr的选择就是一点点尝试,没有什么特殊技巧,所以尝试过程略过。
输出结果为↓
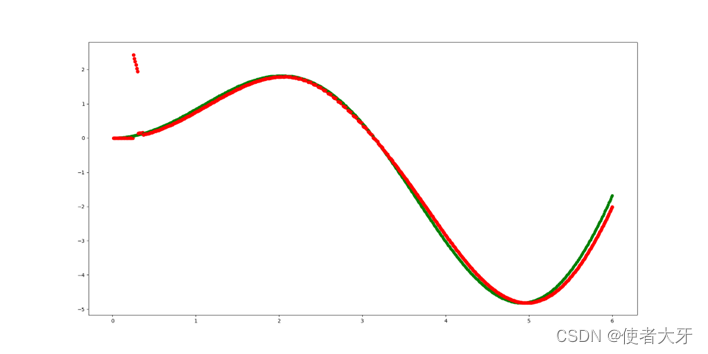
数据会有1组飘离训练数据较大,其他都贴合的很好。
②epoch调整
这个其实很简单,只要看一下每个epoch输出的演变过程就可以了,从本实例来看epoch取到50就够了。
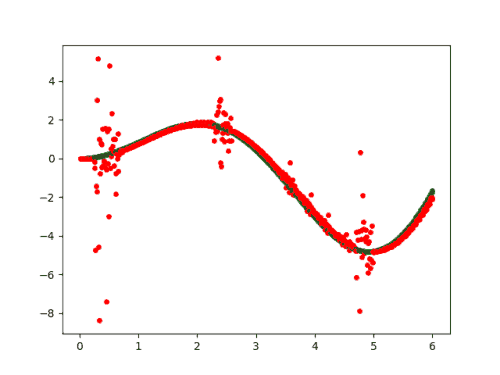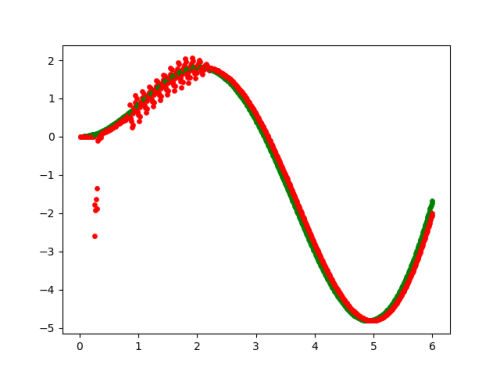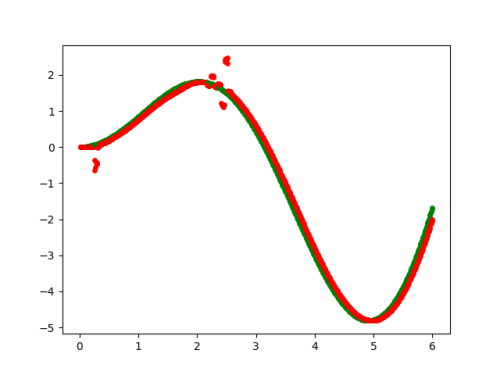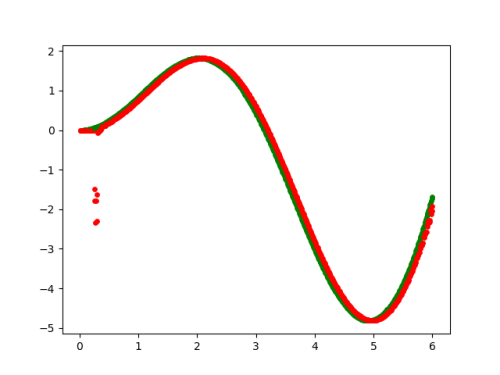
3.数据预测
按上面优化后的训练参数,取x>6.00(完全在训练数据范围外),对输出y进行预测。
x = [[6.01,6.02,6.03…6.06]
T
^T
T,[6.07,6.08,6.09…6.12]
T
^T
T,…[7.15,7.16,7.17…7.20]
T
^T
T]
输出结果为↓(蓝色为
y
=
x
⋅
s
i
n
(
x
)
y=x·sin(x)
y=x⋅sin(x)在6.01≤x≤7.20的函数曲线,即为预测目标。黄色为RNN模型输出值,即为预测值)
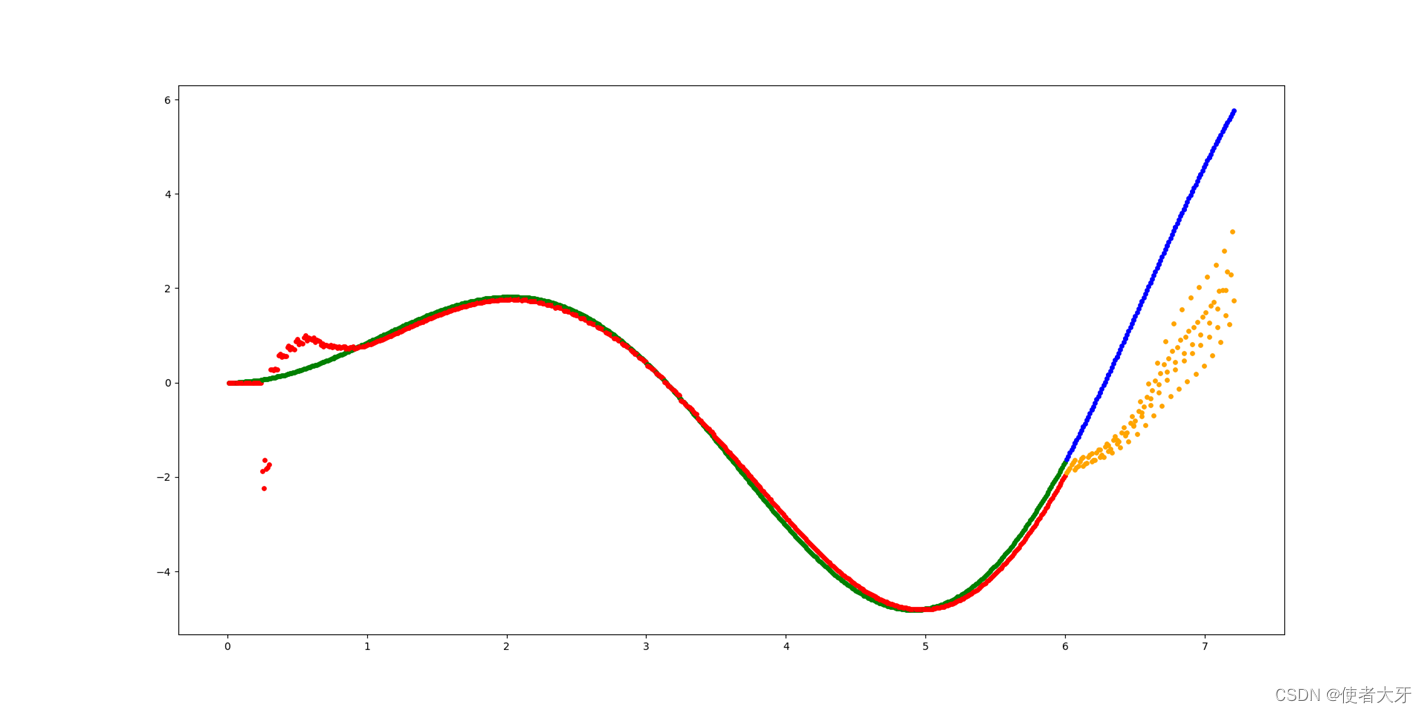
对预测数据局部放大可以看出,预测的第1组数据还是很准确的,后续数据偏差越来越大。
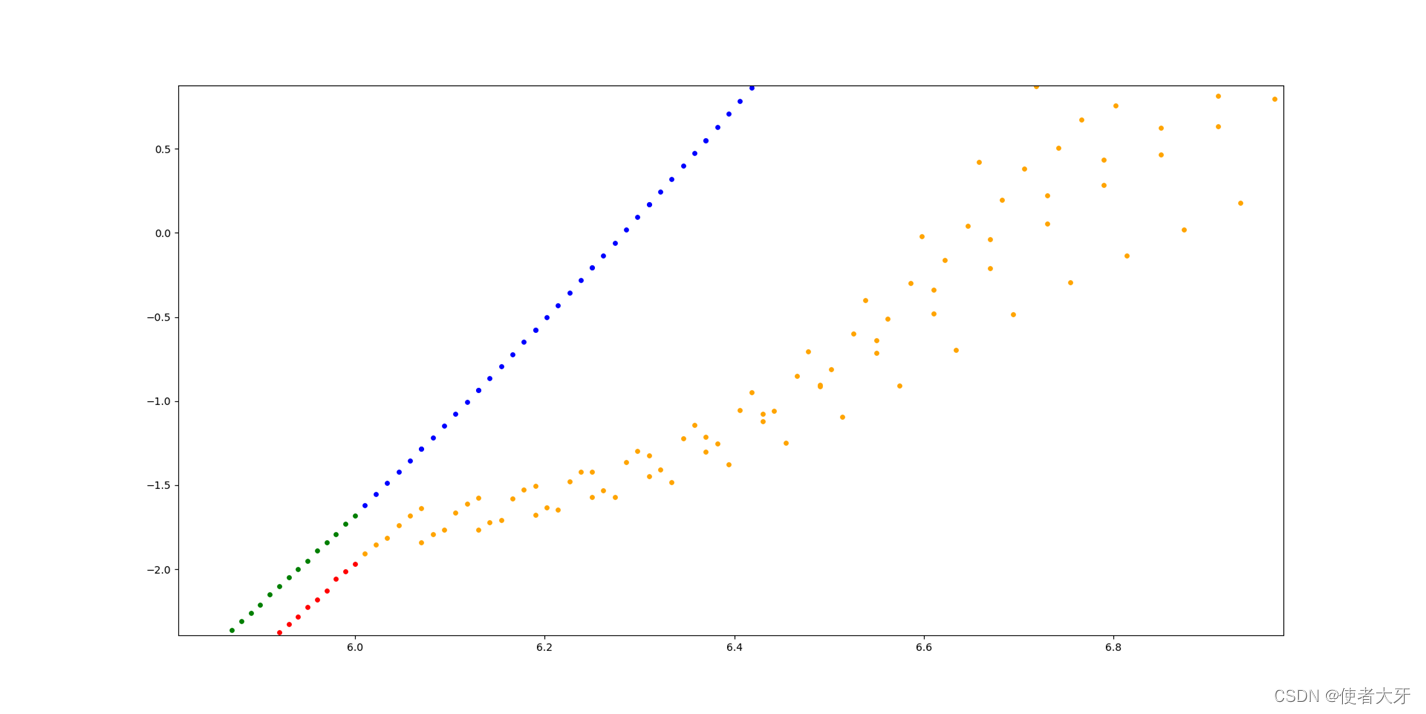
这个结果倒也符合客观逻辑:用过去的经验来预测未来的走势,对越是遥远的未来,判断的准确性就越低。
四、完整代码
import numpy as np
from pandas import read_csv
import matplotlib.pyplot as plt
filename = 'train_data_copy.csv'
data = read_csv(filename)
data = np.array(data)
train_data_x = data[0]
train_data_y = data[1]
x_train = train_data_x.reshape(100, 6, 1)
y_train = train_data_y.reshape(100, 6, 1)
#-------构建神经元模型↓--------
# np.random.seed(2)
class Hidden_layer():
def __init__(self, n_pre, n_cur): # n_pre:上一层神经元个数,n_cur:本层神经元个数
self.w = np.random.randn(n_cur, n_pre)
self.v = np.random.randn(n_cur, n_cur)
self.b = np.zeros([n_cur, 1]) #初始化神经元参数
def forward(self, x, h_pre): #h_pre 上一个时刻的隐层的输出,即为h_t-1
u = np.dot(self.w, x) + np.dot(self.v, h_pre) + self.b
self.h_cur = np.tanh(u) #激活函数为tanh。h_cur即为h_t
return self.h_cur
def backward(self, x, h_cur, h_pre, grad_h): #grad_h为loss对h的偏导
delta = grad_h * (1-h_cur*h_cur) #delta为loss对u的偏导,tanh(u)'=1-tanh(u)*tanh(u),这是一个中间参数,便于计算后面的梯度
self.grad_w = np.dot(delta, x.T)
self.grad_v = np.dot(delta, h_pre.T)
self.grad_b = delta
self.grad_x = np.dot(self.w.T, delta)
self.grad_h_pre = np.dot(self.v.T, delta)
def step(self, lr):
self.w = self.w - lr * self.grad_w
self.v = self.v - lr * self.grad_v
self.b = self.b - lr * self.grad_b
class Output_layer():
def __init__(self, n_cur, n_out):
self.z = np.random.randn(n_out, n_cur)
self.b = np.zeros([n_out, 1]) # 初始化神经元参数
def forward(self, h):
self.h = h #这里的h即为隐层输出h_t
self.y = np.dot(self.z, h) + self.b #输出层不加激活函数
return self.y
def backward(self, y_real):
delta = (self.y - y_real) * 2
self.grad_z = np.dot(delta, self.h.T)
self.grad_h = np.dot(self.z.T, delta)
self.grad_b = delta
def step(self, lr):
self.z = self.z - lr * self.grad_z
self.b = self.b - lr * self.grad_b
#-------构建神经元模型↑--------
#-------训练模型↓---------
#指定模型参数
n_pre = 6 #以6个数据为一组输入
n_cur = 20
n_out = 6 #输出数据也为6个一组
batch_size = 5 #指定batch size
epoch = 300
iteration = 96
hidden_layer = Hidden_layer(n_pre, n_cur)
output_layer = Output_layer(n_cur, n_out)
y_rnn_out = np.zeros([len(y_train), n_out, 1])
h_t = np.zeros([len(y_train) + 1, n_cur, 1]) # 用于储存所有时刻隐层的输出h_t
h_pre = h_t[0, :] # 初始化h_pre即h_0,因为第一个时刻的前一个时刻没有输出,这里全都初始化为0(也可以是随机数)
for e in range(epoch):
for k in range(iteration):
#正向传播,从t=0传播到t=4
for j in range(batch_size):
h_cur = hidden_layer.forward(x_train[k + j, :], h_pre)
h_t[k + j + 1, :] = h_cur
h_pre = h_cur
y_rnn_out[k + batch_size - 1, :] = output_layer.forward(h_cur)
#反向传播,从t=4传播到t=0
output_layer.backward(y_train[k + batch_size - 1, :])
grad_h = output_layer.grad_h #输出层的输入x即为隐层输出h
for j in reversed(range(batch_size)):
hidden_layer.backward(x_train[k + j], h_t[k + j + 1], h_t[k + j], grad_h)
grad_h = hidden_layer.grad_h_pre
#更新权值
hidden_layer.step(lr= 0.023)
output_layer.step(lr= 0.023)
#-------训练模型↑---------
for k in range(100):
plt.scatter(x_train[k, :], y_train[k, :], c="green", s=15) # 绿色线为真实值(训练数据)
plt.scatter(x_train[k, :], y_rnn_out[k, :], c="red", s=15) # 红色线为学习值
plt.show()
# #-------用训练好的模型预测数据↓-------
#创建预测数据的横坐标x_predict值
x_predict = np.zeros([20, 6, 1])
for i in range(20): #预测20个数据
x_predict[i] = np.linspace(6.01+i*0.06, 6.01+(i+1)*0.06, 6).reshape(-1,1)
#创建真实y值
y_real = x_predict * np.sin(x_predict)
#创建隐藏层输出h_predict,隐层输出h要多一个h_0
h_predict = np.zeros([21, 20, 1])
h_predict[0, :] = h_t[100, :]
#创建预测结果数据
y_predict = np.zeros([20, 6, 1])
h_predict_pre = h_predict[0]
#前向传播
for i in range(20):
h_predict_cur = hidden_layer.forward(x_predict[i, :], h_predict_pre)
h_predict[i+1, :] = h_predict_cur
h_predict_pre = h_predict_cur
y_predict[i, :] = output_layer.forward(h_predict_cur)
#-------用训练好的模型预测数据↑-------
for i in range(20):
plt.scatter(x_predict[i, :], y_real[i, :], c="blue", s = 15) #蓝色线为真实值
plt.scatter(x_predict[i, :], y_predict[i, :], c="orange", s = 15) #黄色线为预测值
print(y_predict)
plt.show()
最后
以上就是高大镜子最近收集整理的关于基于Numpy构建RNN模块并进行实例应用(附代码)的全部内容,更多相关基于Numpy构建RNN模块并进行实例应用(附代码)内容请搜索靠谱客的其他文章。








发表评论 取消回复