今日语:实在是不明白xpath的语法,边参考边记录吧~
一.Xpath的概念:
- 它使用路径表达式在XML文档中进行导航
- 包含一个标准数据库
- 是XSLT中的 主要元素
- 是W3C的标准
二.Xpath的节点
共有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及根节点
- 而XML文档是被当做节点树看待,所以之前还是要认真了解XML的相关知识;而树的根是根节点。下面是一个XML文档:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore> -------------------------------------------->文档节点
<book>
<title lang="en">Harry Potter</title> -----<lang="en">---属性节点
<author>J K. Rowling</author> ------------------------>元素节点
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>- 节点关系:其实就像我们在生活中的亲戚关系,一层层滴~(简图)
- Xpath的语法:是通过路径表达式来选取XML文档中的节点或者节点集。
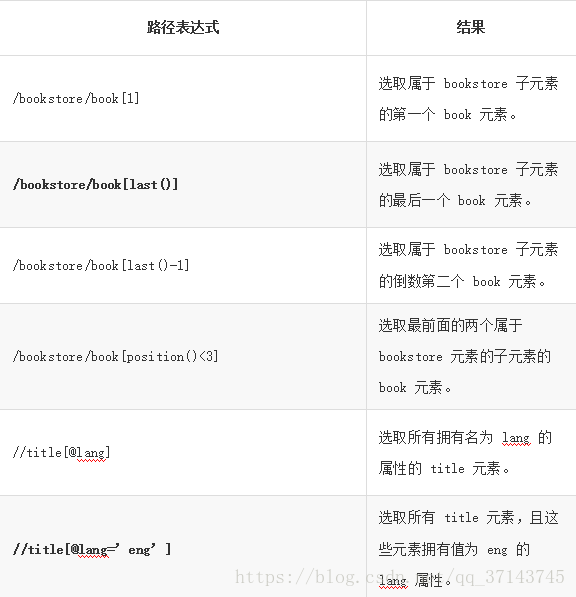
用表格表达一下:


带有谓语的表达式列表:
三、来个实例看看吧~这个是另外放在.html(我这里是hi.html)文件中的
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>四、用代码实现一下:
from lxml import etree
#读取外部文件
html = etree.parse('./hi.html')
#转换类型
result = etree.tostring(html)
#转换成html代码
html = etree.HTML(result)
#最后转换成string类型
result = etree.tostring(html)
print(result.decode("utf-8"))
#1.显示etree.parse()返回类型
print("---1",type(html))
#2.打印<li>标签的元素集合
result = html.xpath('//li')
print("---2",result)
#3.继续获取<li> 标签的所有 class属性
result = html.xpath('//li/@class')
print("---3",result)
#4.继续获取<li>标签下hre f为 link1.html 的 <a>标签
result = html.xpath('//li/a[@href="link1.html"]')
print("---4",result)
#5.获取<li> 标签下的所有 <span> 标签
result = html.xpath('//li//span')
print("---5",result)
#6.获取最后一个 <li> 的 <a> 的 href
result = html.xpath('//li[last()]/a/@href')
print("---6",result)
#7.获取倒数第二个元素li的内容,也就是fourth item
result = html.xpath('//li[last()-1]/a/text()')
print("---7",result)
#8.获取 class 值为 bold 的标签名
result = html.xpath('//*[@class="bold"]')
print("---8",result)
效果图依次:
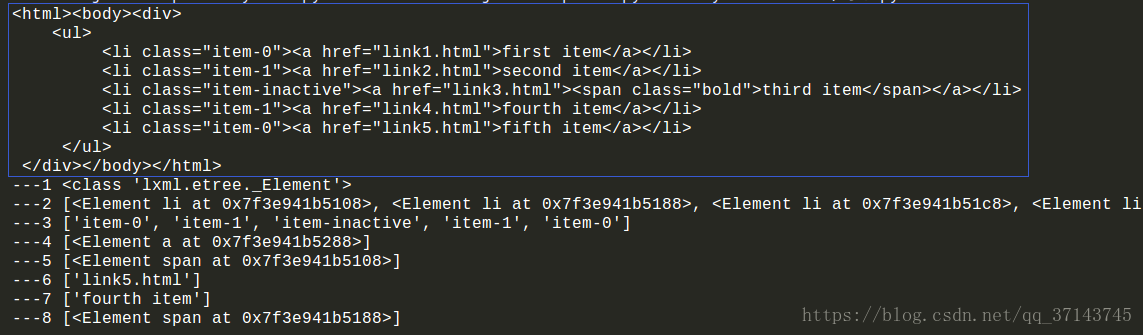
总结一下:在hi.html文件中是没有头标签的,当写入此代码:(html = etree.HTML(result))的时候,会自动加入html标签,有截图可看到
详细请看:
W3School官方文档:http://www.w3school.com.cn/xml/index.asp
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
最后
以上就是高大猫咪最近收集整理的关于Xpath的介绍的全部内容,更多相关Xpath内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复