这里写自定义目录标题
- 常见的网站反爬手段
- 1.请求头加token
- 2.页面跳转
- 3.动态function
- 4.令人哭笑不得的html标签
常见的网站反爬手段
1.请求头加token
像移动,猎云网这类网站,就是用的这种反爬手段。
他们会在你打开首页时,在返回的response中藏一个token,
在你访问下一页时会使用这个token来作为请求头的内容,如果没有则请求失败
如猎云网的token藏在head中

ajIudUF2V0gsfGIvJg4PCyhCGBsRLhA7LQtqPAwGMjlYWXs5DR49Hw==
就是我这次请求的token
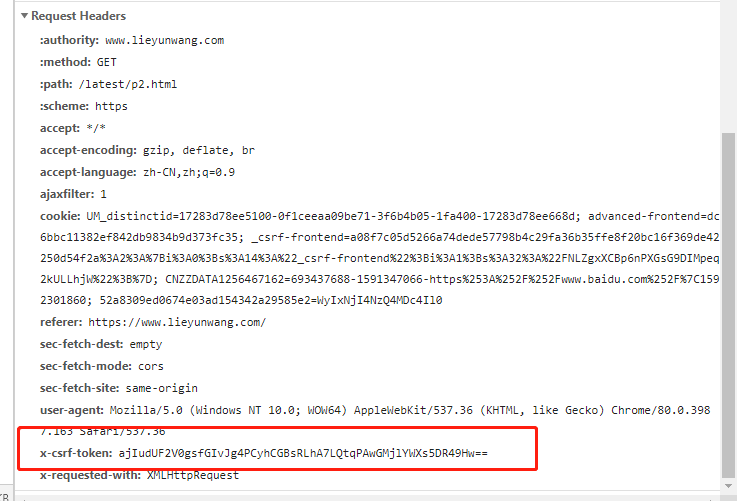
在我点击下一页时,这个token会被带入header中
2.页面跳转
比如百度资讯,我从列表页面获取到的详情页url是https开头的,
但是点开页面他会自动跳转到http开头,后面不变的页面,但是在使用代码请求时,是不会自动跳转的
,所以我们需要在获取详情页之前手动将https替换为http再请求

3.动态function
比如36kr,他在每次获取下一页时都需要一个call——back——page参数,这个参数每一页都不一样,所以每次获取下一页时,都需要从本业找到这个参数,我猜测他是把页数给加密了,变成一个密码串。
4.令人哭笑不得的html标签
最近爬取政府新闻,发现有个标签死活拿不到,我回想起来以前有个网站的html标签只有开始标签没有结束标签会导致这样,结果一阵检查之后发现并不是,在浏览器上他显示的标签属性是这样的
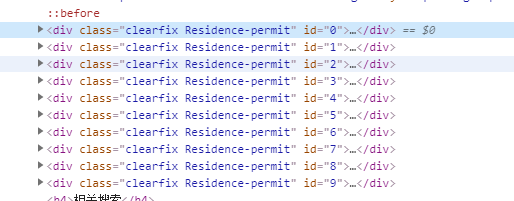
很自然地,我用class获取他的一系列标签,结果就是拿不到,一气之下我下载了他的网页代码,结果

class后面藏了一个空格,厉害厉害,这个空格在加载的时候被浏览器自动删除了,这个反爬手段属实厉害
最后
以上就是美好鸡最近收集整理的关于常见的网站反爬手段常见的网站反爬手段的全部内容,更多相关常见内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复