Classx-word2vec(词嵌入基础)
1. 基本理论-Word2Vec
词语的表示:
1)one-hot模型,每个单词一个序号,表示简单,但忽略了词语的语义信息,比如两个意义相近的词语其表示的相似度应该也高。
为了在表示上保留词语的语义信息,引入’Word2Vec 词嵌入工具‘。
2)Word2Vec:每个词表示成一个定长向量,通过在语料库上的预训练,使得定长向量能表达不同词之间的相似和类比关系,以引入一定的语义信息。这种表示操作–embedding。
基于两种概率模型的假设,我们可以定义两种 Word2Vec 模型:
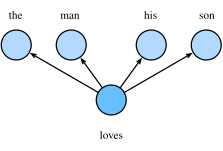
a) Skip-Gram 跳字模型
背景词由中心词生成,即建模
P
(
w
o
∣
w
c
)
P(w_{o}|w_{c})
P(wo∣wc),其中
w
c
w_{c}
wc为中心词,
w
o
w_{o}
wo为任一背景词;
b)CBOW (continuous bag-of-words) 连续词袋模型
假设中心词
w
c
w_{c}
wc由背景词
w
o
w_{o}
wo生成,即建模
P
(
w
c
∣
w
o
)
P(w_{c}|w_{o})
P(wc∣wo)
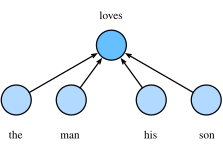
注意上两图中的箭头方向代表两类词语之间的因果关系。
本节中我们以第一种’Skip-Gram 跳字模型‘为基础,介绍后续内容。
2. Word2Vec 词嵌入实例
过程综述:
1.下载 PTB 数据集
2. 使用 Skip-Gram 跳字模型
3. 负采样近似
4. 训练模型得到词嵌入模型
具体操作
Word2Vec 能从语料中学到如何将离散的词映射为连续空间中的向量,并保留其语义上的相似关系。
因此,使用PTB (Penn Tree Bank) 语料库(采样自《华尔街日报》的文章,包括训练集、验证集和测试集),使用其作为数据集,训练得到能够很好表达语义信息的词嵌入模型
a) 载入数据集
打开txt文件,按行读取内容,以空格符作为标识得到txt的词语组成,保存在raw_dataset中,raw_dataset为vector<vector< token >>,外层为行,内层为该行所有token。
b)建立词语索引
使用dict构建读入数据的字典(统计txt中词频,构建idx2token和token2idx的正负向索引,删除词频过低的token。
c) 二次采样
文本中并非词频越高该词语越重要,许多无意义的虚词往往有很高的词频(the,be,in,…)。
通常来说,在一个背景窗口中,一个词(“chip”)和较低频词(“microprocessor”)同时出现,比和较高频词(“the”)同时出现对训练词嵌入模型更有益。
因此,训练词嵌入模型时可以对词进行二次采样。 具体来说,数据集中每个被索引词
w
i
w_{i}
wi将有一定概率被丢弃,该丢弃概率为
P
(
w
i
)
=
m
a
x
(
1
−
t
f
(
w
i
)
,
0
)
P(w_{i})=max(1-sqrt{frac{t}{f(w_{i})}},0)
P(wi)=max(1−f(wi)t,0)
其中,常数
t
t
t为超参数(i.e.,
1
0
−
4
10^{-4}
10−4)。
f
(
w
i
)
f(w_{i})
f(wi)为单词
w
i
w_{i}
wi在数据集中出现次数与数据集总词语个数之比,即
w
i
w_{i}
wi的词频。
当词频
f
(
w
i
)
f(w_{i})
f(wi)大于预设
t
t
t时候,单词
w
i
w_{i}
wi有一定概率被丢弃,且
f
(
w
i
)
f(w_{i})
f(wi)越大,丢弃概率
P
(
w
i
)
P(w_{i})
P(wi)越大。
d) 提取中心词和背景词
以每个单词为中心词
w
c
w_{c}
wc,在
[
1
,
M
a
x
W
i
n
d
o
w
S
i
z
e
]
[1,MaxWindowSize]
[1,MaxWindowSize]中随机产生窗口大小,取周围前后WindowSize个词语组成该
w
c
w_{c}
wc的
w
o
w_{o}
wo
e) Skip-Gram 跳字模型
在跳字模型中,每个词被表示成两个
d
d
d维向量,用来计算条件概率。
假设这个词在词典中索引为
i
i
i,当它为中心词时向量表示为
v
i
∈
R
d
v_{i}in R^d
vi∈Rd,而为背景词时向量表示为
u
i
∈
R
d
u_{i}in R^d
ui∈Rd。设中心词
w
c
w_{c}
wc在词典中索引为
c
c
c,背景词
w
o
w_{o}
wo在词典中索引为
o
o
o,我们假设给定中心词生成背景词的条件概率满足下式:
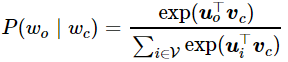
PyTorch中预置了Embedding层,预置了批量乘法。则我们可以得到Skip-Gram 模型的前向计算代码表示
f) 负采样近似
由于 softmax 运算考虑了背景词可能是词典 V 中的任一词,对于含几十万或上百万词的较大词典,就可能导致计算的开销过大。我们将以 skip-gram 模型为例,介绍负采样 (negative sampling) 的实现来尝试解决这个问题。
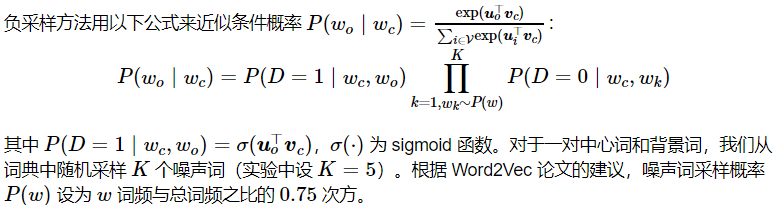
其中,根据原始公式我们可知:
P
(
w
o
∣
w
c
)
P(w_{o}|w_{c})
P(wo∣wc)中,对于每一个
w
o
w_{o}
wo来说,
∑
P
(
w
o
∣
w
c
)
=
1
sum P(w_{o}|w_{c})=1
∑P(wo∣wc)=1,各变量不是互相独立的,但由于字典数据集很大,我们可近似认为各变量之间相互独立,则有了上面的近似表达式。
在近似表达式中,
D
=
1
D=1
D=1,
D
=
0
D=0
D=0分别代表正样本(中心词和背景词在同一个词窗中),负样本(中心词和背景词不在一个词窗中)。因此根据近似表达式,我们使用
P
p
o
s
=
σ
(
u
o
T
v
c
)
P_{pos}=sigma(u_{o}^Tv_{c})
Ppos=σ(uoTvc)计算其正样本概率(
u
o
u_{o}
uo
v
c
v_{c}
vc分别为背景词和中心词的embedding表达),负样本概率计算,通过在词典中随机采样
K
(
K
=
5
)
K(K=5)
K(K=5)个噪声词,累加计算得到
P
n
e
g
P_{neg}
Pneg。
负样本采样还有其他表示形式,todo
g) 批量读取数据
在批量读取数据中,我们同时进行了负采样的计算
h) 训练模型
损失函数
加入负采样模型, Word2Vec 词嵌入模型的loss函数更改为:

以上方法为:在小规模数据集上训练了一个 Word2Vec 词嵌入模型,并通过词向量的余弦相似度搜索近义词。
Classx-Word2Vec 词嵌入进阶
虽然 Word2Vec 已经能够成功地将离散的单词转换为连续的词向量,并能一定程度上地保存词与词之间的近似关系,但 Word2Vec 模型仍不是完美的,它还可以被进一步地改进:
a) 子词嵌入(subword embedding):FastText 以固定大小的 n-gram 形式将单词更细致地表示为了子词的集合,而 BPE (byte pair encoding) 算法则能根据语料库的统计信息,自动且动态地生成高频子词的集合;
b)GloVe 全局向量的词嵌入: 通过等价转换 Word2Vec 模型的条件概率公式,我们可以得到一个全局的损失函数表达,并在此基础上进一步优化模型。
实际中,我们常常在大规模的语料上训练这些词嵌入模型,并将预训练得到的词向量应用到下游的自然语言处理任务中。本节就将以 GloVe 模型为例,演示如何用预训练好的词向量来求近义词和类比词。
GloVe 全局向量的词嵌入(todo)
GloVe 模型
原始word2vec模型(skip-Gram模型,不使用负采样近似)的最大似然估计为:
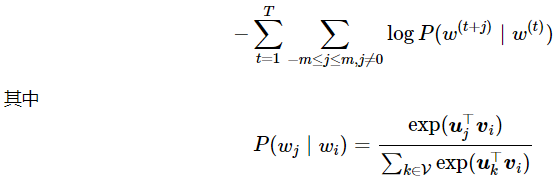
枚举方式为每个中心词循环(
t
=
1
t
o
T
t=1 to T
t=1toT),中心词的每个背景词循环(
j
∈
[
−
m
,
m
]
j in [-m,m]
j∈[−m,m])。使用另一种枚举方式:
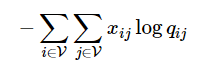
直接枚举每个词分别作为中心词和背景词的情况。其中,
x
i
j
x_{ij}
xij代表整个数据集中
w
j
w_{j}
wj作为
w
i
w_{i}
wi的背景词的次数总和(
i
:
c
e
n
t
e
r
;
j
:
c
o
n
t
e
x
t
i: center; j: context
i:center;j:context)。
该式还可以进一步表示为交叉熵形式:
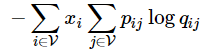
其中
x
i
x_{i}
xi是
w
i
w_{i}
wi的背景词窗大小总和,
p
i
j
p_{ij}
pij是
w
j
w_{j}
wj在
w
i
w_{i}
wi的背景词窗中所占的比例。
总结来说,词嵌入方法本质上:让模型学出, w j w_{j} wj有多大概率是 w i w_{i} wi的背景词。真实的标签是语料库上的统计数据。同时,语料库中的每个词根据 x i x_{i} xi(背景窗大小)的不同,在损失函数中所占的比重也不同。
注意到目前为止,我们只是改写了 Skip-Gram 模型损失函数的表面形式,还没有对模型做任何实质上的改动。而在 Word2Vec 之后提出的 GloVe 模型,则是在之前的基础上做出了以下几点改动:
1)
p
i
j
p_{ij}
pij和
q
i
j
q_{ij}
qij的表达形式,使用非概率分布,并对其取对数。
p
i
j
=
x
i
j
p_{ij}=x_{ij}
pij=xij,
q
i
j
=
e
x
p
(
u
j
T
v
i
)
q_{ij}=exp(u_{j}^Tv_{i})
qij=exp(ujTvi)。
2)为每个词
w
i
w_{i}
wi增加两个标量模型参数:中心词偏差项
b
i
b_{i}
bi和背景词偏差项
c
i
c_{i}
ci,松弛了概率定义中的规范性。
3)将每个损失项的权重
x
i
x_{i}
xi替换成函数
h
(
x
i
j
)
h(x_{ij})
h(xij),权重函数
h
(
x
)
h(x)
h(x)是值域在[0,1] 上的单调递增函数,松弛了中心词重要性与
x
i
x_{i}
xi线性相关的隐含假设;
4)用平方损失函数替代了交叉熵损失函数。
综上,我们获得了 GloVe 模型 的损失函数表达式:
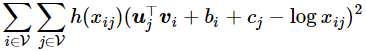
由于这些非零
x
i
j
x_{ij}
xij是预先基于整个数据集计算得到的,包含了数据集的全局统计信息,因此 GloVe 模型的命名取“全局向量”(Global Vectors)之意。
具体操作
a)载入预训练的 GloVe 向量
GloVe 官方 提供了多种规格的预训练词向量,可根据需要下载。
b)求近义词和类比词
求近义词:由于词向量空间中的余弦相似性可以衡量词语含义的相似性,我们可以通过寻找空间中的 k 近邻,来查询单词的近义词。
c)求类比词
除了求近义词以外,我们还可以使用预训练词向量求词与词之间的类比关系。
例如“man”之于“woman”相当于“son”之于“daughter”。
求类比词问题可以定义为:对于类比关系中的4个词“ a 之于 b 相当于 c 之于 d ”,给定前3个词 a,b,c 求 d 。
求类比词的思路是,搜索与
c
⃗
+
b
⃗
−
a
⃗
vec{textbf{c}}+vec{textbf{b}}-vec{textbf{a}}
c+b−a的结果向量最相似的词向量,其中
a
⃗
vec{textbf{a}}
a为
w
a
w_textbf{a}
wa的词向量。
Classx-文本情感分类
对于给定一段文字,得到该文字的情感,为情感分类问题,可看作是文本分类问题。
同搜索近义词和类比词一样,文本分类也属于Word2Vec词嵌入的下游应用。
在本节中,我们将应用预训练的词向量,分别使用含多个隐藏层的双向循环神经网络,卷积神经网络,来判断一段不定长的文本序列中包含的是正面还是负面的情绪。后续内容将从以下几个方面展开:
1)文本情感分类数据集
2)使用循环神经网络进行情感分类
3)使用卷积神经网络进行情感分类
文本情感分类数据
我们使用斯坦福的IMDb数据集(Stanford’s Large Movie Review Dataset)作为文本情感分类的数据集。(该数据集来自影评网站IMDb)
具体操作
a)预处理数据
取数据后,我们先根据文本的格式进行单词的切分,再利用 torchtext.vocab.Vocab 创建词典。
使用建立好的字典,将数据集文本从字符串转换为单词下标序列表示。
b)创建数据迭代器
利用 torch.utils.data.TensorDataset,可以创建 PyTorch 格式的数据集,从而创建数据迭代器。
c) 加载预训练的词向量
注意,夹在的预训练词向量并不一定包括我们的数据集全部词语,因此我们加载与训练词向量(net.embedding.weight.requires_grad = False使得网络不要动权重值),后续训练继续补全模型。
d.1)使用循环神经网络(多层双向RNN)
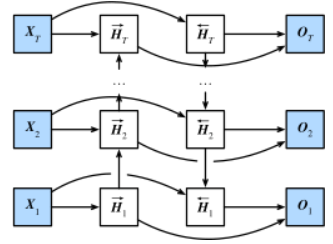
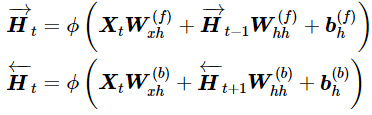
可以注意到,正向
H
t
H_{t}
Ht依靠
H
t
−
1
H_{t-1}
Ht−1进行计算,反向
H
t
H_{t}
Ht依靠
H
t
+
1
H_{t+1}
Ht+1进行计算,之后正反向
H
t
H_{t}
Ht连结得到最终的隐层输出
H
t
H_{t}
Ht,最终的
O
t
O_{t}
Ot包含了整个序列的信息。
d.2)使用卷积神经网络(TextCNN)
在此,我们首先介绍TextCNN的基本理论。
一维卷积层
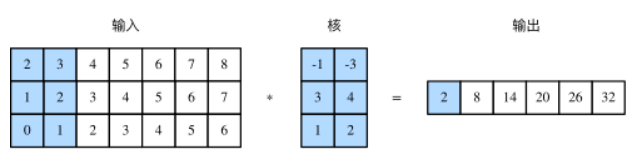
一维卷积层使用一维的互相关运算。在一维互相关运算中,卷积窗口从输入数组的最左方开始,按从左往右的顺序,依次在输入数组上滑动。当卷积窗口滑动到某一位置时,窗口中的输入子数组与核数组按元素相乘并求和,得到输出数组中相应位置的元素。

多输入通道的一维互相关运算也与多输入通道的二维互相关运算类似:在每个通道上,将核与相应的输入做一维互相关运算,并将通道之间的结果相加得到输出结果。
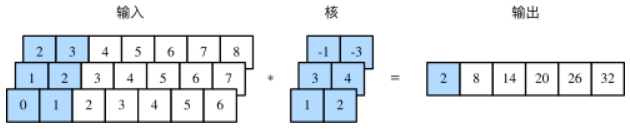
我们也可以将图中多输入通道的一维互相关运算以等价的单输入通道的二维互相关运算呈现。
时序最大池化层
一维全局最大池化层:假设输入包含多个通道,各通道由不同时间步上的数值组成,各通道的输出即该通道所有时间步中最大的数值。因此,时序最大池化层的输入在各个通道上的时间步数可以不同。
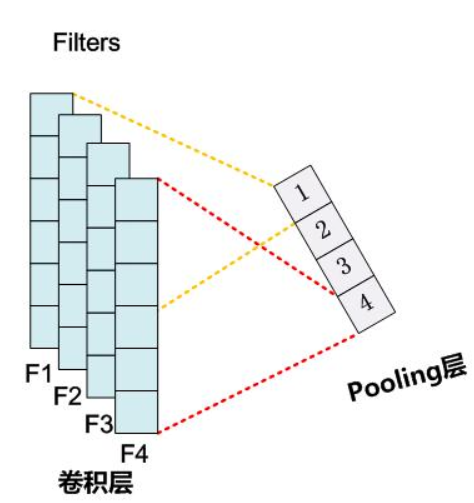
为提升计算性能,我们常常将不同长度的时序样本组成一个小批量,并通过在较短序列后附加特殊字符(如0)令批量中各时序样本长度相同。这些人为添加的特殊字符当然是无意义的。由于时序最大池化的主要目的是抓取时序中最重要的特征,它通常能使模型不受人为添加字符的影响。
TextCNN 模型
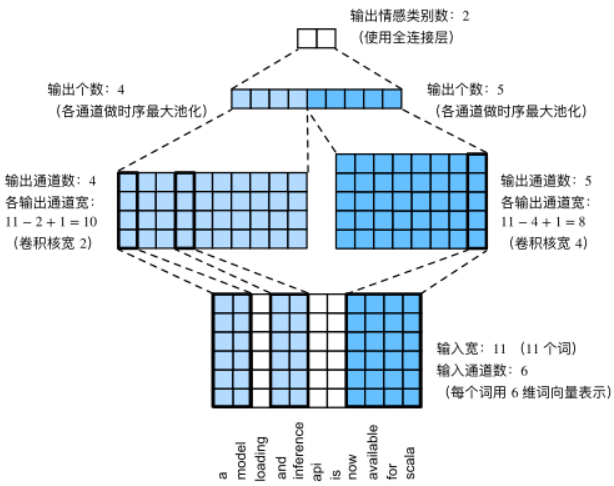
Supp
1. python的括号
小括号( ):tuple – 元组数据类型,元组是一种不可变序列。
>>> tup = (1,2,3)
>>> tup
(1, 2, 3)
中括号[ ]:list – 列表数据类型
>>> a = list('python')
['p', 'y', 't', 'h', 'o', 'n']
列表中,常采用’:'取list中元素。(todo)
a[2] # a中第idx=2的元素,idx从0开始
a[-2] # a中idx=end_idx+1-2的元素,倒数第2个
a[:n] # a中[0,n)元素
a[n:] # a中[n,end]元素
a[:-n] # a中[0,end_idx+1-n)元素
a[-n:] # a中[end_idx+1-n,end]元素
a[m:n] # a中[m:n),a中从idx=m到n的左闭右开区间
a[:3:2] #
a[3:6:2] #
大括号{ }:dict – 字典数据类型。由键对值组(key-value)组成。冒号‘:’分开键和值,逗号‘,’隔开组。
>>> dic={'jon':'boy','lili':'girl'}
>>> dic
{'lili': 'girl', 'jon': 'boy'}
counter = collections.Counter([tk for st in raw_dataset for tk in st]) (todo)
2. 交叉熵损失函数
原始表达:(from class)

(from https://blog.csdn.net/xg123321123/article/details/52864830)

最后
以上就是欣喜黄豆最近收集整理的关于课程学习总结3Classx-word2vec(词嵌入基础)Classx-Word2Vec 词嵌入进阶Classx-文本情感分类Supp2. 交叉熵损失函数的全部内容,更多相关课程学习总结3Classx-word2vec(词嵌入基础)Classx-Word2Vec内容请搜索靠谱客的其他文章。








发表评论 取消回复