目录
前言
一、锁
1.互斥锁
1.加锁过程
2.解锁过程
3.饥饿模式
4.锁的使用建议
2.读写锁
1.Lock()
2.Unlock()
3.RLock()
4.RUnlock()
5.阻塞关系
6.读写之间阻塞原理
7.readerWait的作用
3.锁检测
1.vet
2.race
二、WaitGroup
1.WaitGroup数据结构
2.Add()
3.Done()
3.Wait()
4.用法
三、Context
1. context接口
2. background
3. cancelCtx
4. timerCtx
5. valueCtx
总结
前言
Go开发中并发随处可见,如果不对并发加以控制的话,可能会出现一些意想不到的错误。因此Go语言提供了几种并发控制的方案,例如Channel、WaitGroup、Context、Mutex。
一、锁
1.互斥锁
在src/sync包下的mutex.go文件中可以看到互斥锁的数据结构
type Mutex struct {
state int32 // 互斥锁的状态
sema uint32 // 信号量,协程阻塞等待该信号量,解锁的协程释放信号量唤醒待信号量的协程
}Mutex.state内存布局把该变量分为四个部分,用于记录Mutex的状态:
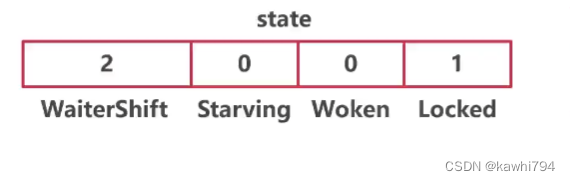
- Locked占用1位,表示当前锁的状态,1表示锁定。
- Woken占用1位,表示是否有协程被唤醒,
- Starving占用1位,表示当前锁是否处于饥饿状态,1表示饥饿,说明有协程阻塞超过了1ms。
- WaiterShift占用剩余的29位,表示阻塞等待锁的协程数量。
1.加锁过程
如果当前只有一个协程要加锁,并且锁处于没有锁定的状态,也就是Locked位为0,那么当前协程会直接将Locked位置1,加锁成功。
如果当前有多个协程要加锁,并且锁处于没有锁定的状态,则只会有一个协程加锁成功,其他没有抢到锁的协程不会立即转入阻塞,而是会进入自旋过程,自旋时会持续地检测Locked位是否为。
自旋的过程很短,如果在自旋过程中发现锁已被释放,那么可以直接获取锁,此时如果其他协程被唤醒也无法获取锁,只能再次阻塞。自旋的好处是协程加锁失败不会立即阻塞,避免了协程的切换。
如果自旋结束,还没有获取到锁,那么协程就会转而获取sema信号量,如果信号量小于1,那么协程就会进入休眠状态,WaiterShift+1,等待解锁协程释放信号量。
2.解锁过程
解锁时,解锁的协程会判断当前WaiterShift位是否大于0,如果WaiterShift <= 0,说明当前没有其他协程阻塞等待锁,此时只需要把Locked位置0即可。
如果WaiterShift > 0,解锁协程会将Locked位置0,并且会释放一个信号量,唤醒一个阻塞的协程,如果还有其他协程和被唤醒的协程竞争锁,那么被唤醒的协程还有可能会再次进入休眠撞他;如果没有其他协程与被唤醒的协程竞争,那么被唤醒的协程再把Locked位置1,那么被唤醒的协程就获取了锁。
3.饥饿模式
每个Mutex都有两种模式,一个是正常模式(上面加锁解锁过程都是在正常模式下),另一个是饥饿模式。
每次协程在进入休眠状态前,都会判断自己等待锁的时间,如果超过了1ms,那么锁会被表记为饥饿状态,然后协程才会进入休眠状态。
如果锁处于饥饿模式,那么不会启动自旋过程,任何新来的协程都会直接进入休眠模式,并且在饥饿模式中,被唤醒的协程会直接获取锁,不存在锁竞争的情况,同时会把等待计数WaiterShift减1。
当休眠队列中没有协程时,饥饿模式会转为正常模式。
4.锁的使用建议
- 尽量减少锁的使用时间,例如一个函数中有很长很长的业务代码,但是出现并发问题的地方可能只是那么几行代码,所以我们没有必要在函数的开头加锁、结尾解锁,否则这个加锁时间会很长加重锁竞争的情况,此时只需要在可能发生并发问题的代码前后加锁解锁即可。
- 使用defer解锁。如果一个函数中在加锁后,解锁前触发了panic,那么panic后面的解锁操作就不会执行,那么会导致这个锁永远没有被释放。
2.读写锁
读写锁可以说是互斥锁的改进,适用于读多写少的情况,Go语言中RWMutex表示读写锁,其数据结构如下:
type RWMutex struct {
w Mutex // 用于控制多个写锁,获得写锁首先要获取该锁
writerSem uint32 // 写操作等待的信号量,由最后一个读操作释放锁时释放
readerSem uint32 // 读操作等待的信号量,由最后一个写操作释放锁时释放
readerCount int32 // 读操作的数量
readerWait int32 // 写操作阻塞时的读操作数量
}1.Lock()
Lock()是写操作加锁,Lock()操作首先要获取RWMutex.w锁,如果当前有读操作,也就是判断readerCount>0,如果readerCount>0,那么写操作会阻塞直到所有读操作完成。
2.Unlock()
Lock()是写操作解锁,解锁前会先判断readerCount是否大于0,如果readerCount>0,说明当前有因为写操作而阻塞的读操作,那么会先唤醒阻塞的读操作协程,然后再解锁。如果readerCount=0,说明当前没有阻塞的读操作协程,会直接解锁。
3.RLock()
RLock()是读操作加锁,会将readerCount++,增加读操作的数量,然后阻塞到写操作协程结束。
4.RUnlock()
RUnlock()是读操作解锁,首先会将readerCount--,减少读操作的数量,如果当前读操作是最后一个读操作并且当前有写操作协程阻塞,那么当前读操作协程会先唤醒阻塞的写操作协程,然后才完成解锁。
5.阻塞关系
- 写锁阻塞写锁。
- 写锁阻塞读锁。
- 读锁阻塞写锁。
- 读锁不阻塞读锁。
6.读写之间阻塞原理
- 写与写之间阻塞的原理:通过RWMutex的数据结构可以知道,RWMutex中包含一个Mutex互斥锁,协程进行写操作锁定之前必须要获得这个锁,如果这个锁已经被获取了,那么其他进行写操作锁定的协程只能阻塞等待该锁。
- 读操作阻塞写操作的原理:RLock()是读操作加锁会将readerCount++,此时写操作协程发现readerCount不为0,说明当前有读操作协程在执行,那么写操作协程就会阻塞等待所有读操作协程解锁为止。
- 写操作阻塞读操作的原理:协程进行写操作锁定时,会将readerCount减去一个常量,这个常量大小为1 << 30,这个值也是实际可支持的最大读操作锁定的数量。当完整写操作锁定时,再有新的读操作前来,会发现readerCount<0,那么就可以知道当前有写操作在进行,于是读操作阻塞等待写操作解锁。当写操作完成时会将readerCount加上原来减去的常量,保证原始的readerCount不会丢失。源码如下:
const rwmutexMaxReaders = 1 << 30 // 读操作锁定时减去的常量 func (rw *RWMutex) Lock() { if race.Enabled { _ = rw.w.state race.Disable() } // First, resolve competition with other writers. rw.w.Lock() // Announce to readers there is a pending writer. // 读操作加锁时,减去rwmutexMaxReaders,使readerCount变为负数 r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders // Wait for active readers. if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 { runtime_SemacquireMutex(&rw.writerSem, false, 0) } if race.Enabled { race.Enable() race.Acquire(unsafe.Pointer(&rw.readerSem)) race.Acquire(unsafe.Pointer(&rw.writerSem)) } }
7.readerWait的作用
readerWait的主要作用就是记录写操作加锁被阻塞时排在他前面的读操作数量。RLock()是读操作加锁,会将readerCount++,而Lock()写操作加锁是需要判断readerCount数量的,如果写操作在阻塞的过程中,一直有新的读操作过来加锁,那么readerCount永远不为0,Lock()加锁操作就永远阻塞,所以需要记录排在写操作前面的读操作。
排在写操作前面的读操作解锁时,需要做两件事,将readerCount--和readerWait--,当readerWait变为0时,说明该到写操作加锁了。用readerWait记录排在写操作前面的读操作数量,可以避免写操作锁定等待时间过长而出现饥饿的情况。
3.锁检测
1.vet
如果我们的代码中出现了锁拷贝的情况,可能会导致锁的死锁问题,这时可以使用vet进行检测。vet用于检测是否存在锁拷贝问题或者其他可能的bug。
go vet main.go
为什么需要检测锁拷贝?
func main() {
var wg sync.Mutex
wg.Lock()
wg1 := wg
wg.Unlock()
wg1.Lock()
wg1.Unlock()
}上述代码中我们新建了一个锁wg,给wg加锁后,将wg拷贝给wg1,然后wg解锁,wg1再加锁,那么此时运行代码会报死锁,运行结果如下,14行就是wg1.Lock():
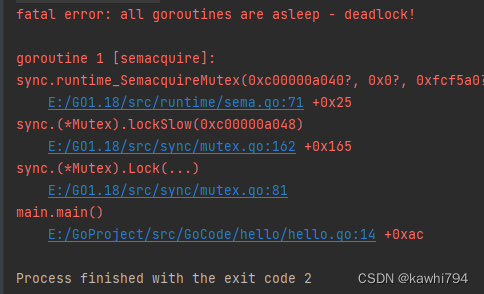
这里出现死锁就是因为锁拷贝,由代码可以看出wg处于上锁的状态拷贝给了wg1,所以wg1也是处于上锁的状态,对于已经上锁的再次上锁就会报错。
2.race
race竞争检测用于发现隐含的数据竞争问题。
>go build -race main.go // 编译成可执行文件
>./main.exe // 运行可执行文件二、WaitGroup
WaitGroup译为等待组,适用于一个协程需要等待另一组协程执行完成才执行的场景。源码中给出WaitGroup的解释是:WaitGroup等待goroutine集合完成。主goroutine调用Add()以设置要等待的goroutine的数量。然后运行每个goroutine,并在完成后完成调用。同时,可以使用Wait()阻塞,直到所有goroutine完成。
1.WaitGroup数据结构
type WaitGroup struct {
noCopy noCopy
state1 uint64
state2 uint32
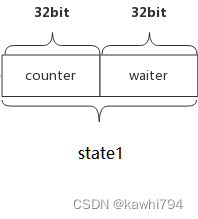
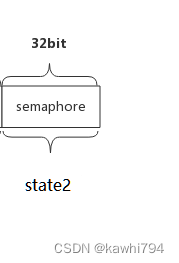
}state1为一个无符号的64位整型,其中高32位记录的是还未执行结束的协程计数器,记为counter;低32位为等待协程组执行结束的协程数量,即有多少个等候者,记为waiter count。
state2为一个无符号的32位整型,代表信号量sema。
2.Add()
Add(x int)首先会获取state1和state2字段的指针,然后将参数x左移32位累加到counter中,增加还未执行结束的协程数量。累加完成后会分别获取state1中counter和waiter的值,如果累加后的counter小于0,触发panic。当counter等于0时,说明等待组中的协程都结束了,如果waiter不等于0就会释放信号量唤醒等待的主协程。源码如下:
func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state() // 获取state1和stare2的指针
state := atomic.AddUint64(statep, uint64(delta)<<32) // 将delta累加到counter中
v := int32(state >> 32) // 获取counter值
w := uint32(state) // 获取waiter的值
if v < 0 {
panic("sync: negative WaitGroup counter")
}
if v > 0 || w == 0 {
return
}
// 当前说明counter的值为0,也就是协程组中的协程都结束了
// 如果等待的协程不为0,需要释放信号量
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0) // 释放信号量
}
}3.Done()
Done(x int)就做了一件事,那就是调用Add(-1)。
// Done decrements the WaitGroup counter by one.
// 将WaitGroup counter减1
func (wg *WaitGroup) Done() {
wg.Add(-1)
}3.Wait()
Wait()获取counter、waiter的数量,如果counter为0,表示需要等待的所有协程都结束了。如果需要等待的协程还未执行结束会累加waiter,累加waiter成功后,等待信号量释放。
func (wg *WaitGroup) Wait() {
statep, semap := wg.state()
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32)// 获取counter值
w := uint32(state)// 获取waiter的值
if v == 0 {
// Counter is 0, no need to wait.
// Counter为0,所有协程都结束了,无需等待。
return
}
// Increment waiters count.
// 递增waiters计数
if atomic.CompareAndSwapUint64(statep, state, state+1) {
// 释放信号量
runtime_Semacquire(semap)
if *statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
return
}
}
}4.用法
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(5)
go func() {
fmt.Println("第一个协程执行结束")
wg.Done()
}()
go func() {
fmt.Println("第二个协程执行结束")
wg.Done()
}()
go func() {
fmt.Println("第三个协程执行结束")
wg.Done()
}()
go func() {
fmt.Println("第四个协程执行结束")
wg.Done()
}()
go func() {
fmt.Println("第五个协程执行结束")
wg.Done()
}()
fmt.Println("所有协程都执行完毕,主协程可以执行了")
wg.Wait() // 阻塞等待counter变为0
}三、Context
context用于控制多级协程,例如主协程派生出了子协程,而子协程又派生出新的孙子协程。
1. context接口
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline():返回代表此context 完成工作的时间,如果未设置截止时间,则bool类型返回false。
Done():context 关闭后返回一个关闭的管道,如果无法取消此context,则Done可能返回 nil。另外Done()需要在select-case语句中使用,例如:
select {
case <-ctx.Done():
return
default:
return
}Err():如果Done未关闭,Err()返回nil;如果如果Done被关闭,Err返回一个error用于解释context关闭的原因,原因一为context主动关闭,原因二为context deadline到了。
Value():返回有关于context的k-v键值对,用于在多级协程之间传递数据。
2. background
background()主要用于main函数,作为Context这个树结构的最顶层的Context,也就是根Context。直接调用context.background()就可以获取一个根Context:
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
// Background returns a non-nil, empty Context. It is never canceled, has no
// values, and has no deadline. It is typically used by the main function,
// initialization, and tests, and as the top-level Context for incoming
// requests.
func Background() Context {
return background
}3. cancelCtx
type cancelCtx struct {
Context
mu sync.Mutex // 保护以下字段
// 由第一个cancel()调用时关闭
done atomic.Value
// 在第一次cancel()调用时设置为nil,记录了context所有的cancelCtx
children map[canceler]struct{}
// 在第一次cancel()调用时变为非nil,记录当前context关闭的原因
err error
}WithCancel()函数:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
// 创建一个cancelCtx
c := newCancelCtx(parent)
// 将自身添加到父节点,如果父节点不支持cancel,就继续向上查找祖父节点
propagateCancel(parent, &c)
return &c, func() { c.cancel(true, Canceled) }
}
var Canceled = errors.New("context canceled")cancel()函数:
func (c *cancelCtx) cancel(removeFromParent bool, err error) {
if err == nil { // err: context关闭的原因
panic("context: internal error: missing cancel error")
}
c.mu.Lock()
if c.err != nil {
c.mu.Unlock()
return // already canceled
}
c.err = err // 设置context关闭的原因
d, _ := c.done.Load().(chan struct{})
if d == nil {
c.done.Store(closedchan)
} else {
close(d)
}
for child := range c.children { // 遍历所有的child,逐个调用其cancel()方法,将其关闭
// NOTE: acquiring the child's lock while holding parent's lock.
child.cancel(false, err)
}
c.children = nil
c.mu.Unlock()
if removeFromParent {
removeChild(c.Context, c)
}
}当我们想在代码中控制多级子协程并通知多级子协程停止时,可以调用 WithCancel()和cancel():
package main
import (
"context"
"fmt"
"time"
)
func subGoroutine1(ctx context.Context) {
go subGoroutine3(ctx)
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine1 done")
return
default:
fmt.Println("subGoroutine1 is doing something")
time.Sleep(time.Second)
}
}
}
func subGoroutine2(ctx context.Context) {
go subGoroutine4(ctx)
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine2 done")
return
default:
fmt.Println("subGoroutine2 is doing something")
time.Sleep(time.Second)
}
}
}
func subGoroutine3(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine3 done")
return
default:
fmt.Println("subGoroutine3 is doing something")
time.Sleep(time.Second)
}
}
}
func subGoroutine4(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine4 done")
return
default:
fmt.Println("subGoroutine4 is doing something")
time.Sleep(time.Second)
}
}
}
func main() {
ctx, cancelFunc := context.WithCancel(context.Background())
go subGoroutine1(ctx)
go subGoroutine2(ctx)
time.Sleep(time.Second * 5)
fmt.Println("I think all goroutines are done")
cancelFunc()
time.Sleep(time.Second * 1)
}
// output:
subGoroutine2 is doing something
subGoroutine4 is doing something
subGoroutine1 is doing something
subGoroutine3 is doing something
subGoroutine3 is doing something
subGoroutine4 is doing something
subGoroutine2 is doing something
subGoroutine1 is doing something
subGoroutine1 is doing something
subGoroutine4 is doing something
subGoroutine3 is doing something
subGoroutine2 is doing something
subGoroutine2 is doing something
subGoroutine4 is doing something
subGoroutine1 is doing something
subGoroutine3 is doing something
subGoroutine1 is doing something
subGoroutine2 is doing something
subGoroutine3 is doing something
subGoroutine4 is doing something
I think all goroutines are done
subGoroutine3 done
subGoroutine2 done
subGoroutine4 done
subGoroutine1 done
WithCancel()返回了一个ConcelCtx和一个cancel()函数,在使用时,我们只要把这个ConcelCtx在多级协程之间传递,然后在需要关闭所有子协程的时候调用cancel()函数即可完成通知所有子协程关闭。
cancel()函数会查找父节点context,遍历其map中所有的child,逐个调用其child的cancel()方法。
4. timerCtx
type timerCtx struct {
cancelCtx
timer *time.Timer // Under cancelCtx.mu.
deadline time.Time
}timerCtx在cancelCtx的基础上新增了timer和deadline字段,由这两个字段可以衍生出
withDeadline()和withTimeout()。
withDeadline():
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) {
if parent == nil { // 没有父节点context
panic("cannot create context from nil parent")
}
if cur, ok := parent.Deadline(); ok && cur.Before(d) {
// The current deadline is already sooner than the new one.
return WithCancel(parent)
}
c := &timerCtx{ // 初始化一个timerCtx
cancelCtx: newCancelCtx(parent),
deadline: d,
}
propagateCancel(parent, c) // timerCtx添加到父节点的children map中
dur := time.Until(d)
if dur <= 0 { // 如果当前时间超过了设置的deadline,直接取消当前timerCtx
c.cancel(true, DeadlineExceeded) // deadline has already passed
return c, func() { c.cancel(false, Canceled) }
}
c.mu.Lock()
defer c.mu.Unlock()
if c.err == nil {
c.timer = time.AfterFunc(dur, func() {
c.cancel(true, DeadlineExceeded)
})
}
return c, func() { c.cancel(true, Canceled) }
}withDeadline()的用法:
package main
import (
"context"
"fmt"
"time"
)
func subGoroutine1(ctx context.Context) {
go subGoroutine3(ctx)
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine1 done")
return
default:
fmt.Println("subGoroutine1 is doing something")
time.Sleep(time.Second)
}
}
}
func subGoroutine2(ctx context.Context) {
go subGoroutine4(ctx)
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine2 done")
return
default:
fmt.Println("subGoroutine2 is doing something")
time.Sleep(time.Second)
}
}
}
func subGoroutine3(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine3 done")
return
default:
fmt.Println("subGoroutine3 is doing something")
time.Sleep(time.Second)
}
}
}
func subGoroutine4(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine4 done")
return
default:
fmt.Println("subGoroutine4 is doing something")
time.Sleep(time.Second)
}
}
}
func main() {
d := time.Now().Add(5 * time.Second)
ctx, cancelFunc := context.WithDeadline(context.Background(), d)
// 其实可以不调用cancelFunc(),因为5秒后所有的goroutine都会停止
defer cancelFunc()
go subGoroutine1(ctx)
go subGoroutine2(ctx)
time.Sleep(10 * time.Second)
fmt.Println("ten second passed")
}
withTimeout():其实就是调用了withDeadline(),只不过withDeadline()需要的是一个最后期限也就是高中物理中的时刻,例如12:00:00。
而withTimeout()传入的是最长存活时间,也就是高中物理中的时间,例如30秒、一分钟。
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}withTimeout()的用法其实和withDeadline()非常相似,需要把第二个参数换成时间即可,例如5秒后关闭所有goroutine:
func main() {
ctx, _ := context.WithTimeout(context.Background(), 5*time.Second)
go subGoroutine1(ctx)
go subGoroutine2(ctx)
time.Sleep(10 * time.Second)
fmt.Println("ten second passed")
}5. valueCtx
type valueCtx struct {
Context
key, val any
}使用withValue()即可创建valueCtx:
func WithValue(parent Context, key, val any) Context {
if parent == nil {
panic("cannot create context from nil parent")
}
if key == nil {
panic("nil key")
}
if !reflectlite.TypeOf(key).Comparable() {
panic("key is not comparable")
}
// 创建valueCtx然后返回
return &valueCtx{parent, key, val}
}valueCtx主要用于在各级协程之间传递数据,例如:
package main
import (
"context"
"fmt"
"time"
)
func subGoroutine1(ctx context.Context) {
go subGoroutine3(ctx)
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine1 done")
return
default:
fmt.Printf("I am Goroutine1, parent goroutine tell me" +
" should wait %d secondn", ctx.Value("time"))
time.Sleep(time.Second)
}
}
}
func subGoroutine2(ctx context.Context) {
go subGoroutine4(ctx)
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine2 done")
return
default:
fmt.Printf("I am Goroutine2, parent goroutine tell me" +
" should wait %d secondn", ctx.Value("time"))
time.Sleep(time.Second)
}
}
}
func subGoroutine3(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine3 done")
return
default:
fmt.Printf("I am Goroutine3, parent goroutine tell me" +
" should wait %d secondn", ctx.Value("time"))
time.Sleep(time.Second)
}
}
}
func subGoroutine4(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("subGoroutine4 done")
return
default:
fmt.Printf("I am Goroutine1, parent goroutine tell me" +
" should wait %d secondn", ctx.Value("time"))
time.Sleep(time.Second)
}
}
}
func main() {
ctx := context.WithValue(context.Background(), "time", 5)
go subGoroutine1(ctx)
go subGoroutine2(ctx)
time.Sleep(10 * time.Second)
fmt.Println("ten second passed")
}
总结
以上就是今天要讲的内容,本文简单介绍了Go语言中常用的并发控制方案。
最后
以上就是可耐小蝴蝶最近收集整理的关于Go语言 - 并发控制前言一、锁二、WaitGroup三、Context总结的全部内容,更多相关Go语言内容请搜索靠谱客的其他文章。








发表评论 取消回复