1. 对象的bool值
所有对象都有一个布尔值,可以调用内置函数bool(类bool 的构造方法)得到对象的布尔值。
以下对象的布尔值为False: False、数值零、None、空字符串、空列表、空元组、空字典、空集合。
In [1]: bool(False)
Out[1]: False
In [2]: bool(0)
Out[2]: False
In [3]: bool(0.0)
Out[3]: False
In [4]: bool(None)
Out[4]: False
In [5]: bool("")
Out[5]: False
In [6]: bool([])
Out[6]: False
In [7]: bool(list())
Out[7]: False
In [8]: bool(())
Out[8]: False
In [9]: bool(dict())
Out[9]: False
In [10]: bool(tuple())
Out[10]: False
In [11]: bool({})
Out[11]: False
In [12]: bool(set())
Out[12]: False
In [13]: bool(frozenset())
Out[13]: False
2. 循环语句的break-else语句
在执行while语句或for-in语句时,如果循环正常结束,也就是说,如果没有执行循环体中的break
语句从而提前退出循环,有时可能想在循环正常结束后执行某些操作。
为了判断循环是否正常结束,可以使用一个布尔变量,在循环开始前将布尔变量的值设置为False,
如果执行了循环体中的break语句从而提前退出循环,那就将布尔变量的值设置为True。
最后,在while语句或for-in语句的后面使用if语句判断布尔变量的值,以判断循环是否是正常结束的。
常规写法:
"""循环语句中的break-else结构"""
isBreak = False
n = 0
while n < 5:
if n == 6:
isBreak = True
break
n += 1
if not isBreak:
print('循环正常结束,没有执行循环体中的break语句')
isBreak = False
for n in range(5):
if n == 6:
isBreak = True
break
if not isBreak:
print('循环正常结束,没有执行循环体中的break语句')
对比:
上述的解决方案还有更好的替代。Python为循环语句提供了break-else结构,也就是说,
可以在while语句或for-in语句的后面添加else从句,这样,如果没有执行循环体中的break语句
从而提前退出循环,就会执行eLse从句。
n = 0
while n < 5:
if n == 6:
break
n += 1
else:
print('循环正常结束,没有执行循环体中的break语句')
for n in range(5):
if n == 6:
break
else:
print('循环正常结束,没有执行循环体中的break语句')
3. enumerate关键字
enumerate(sequence, [start=0])
参数
sequence – 一个序列、迭代器或其他支持迭代对象。
start – 下标起始位置。
返回值
返回 enumerate(枚举) 对象。
In [1]: """带索引的序列遍历"""
...: L = ['Java', 'Python', 'Swift', 'Kotlin']
...:
In [2]: print(enumerate(L))
<enumerate object at 0x000002922BD48438>
In [3]: print(list(enumerate(L)))
[(0, 'Java'), (1, 'Python'), (2, 'Swift'), (3, 'Kotlin')]
In [4]: print(list(enumerate(L, 1)))
[(1, 'Java'), (2, 'Python'), (3, 'Swift'), (4, 'Kotlin')]
In [5]: for index, item in list(enumerate(L)):
...: print('L[{}] = {}'.format(index, item))
...:
L[0] = Java
L[1] = Python
L[2] = Swift
L[3] = Kotlin
In [6]: for index, item in enumerate(L):
...: print('L[{}] = {}'.format(index, item))
...:
L[0] = Java
L[1] = Python
L[2] = Swift
L[3] = Kotlin
4. 并行遍历
4.1 常规:通过索引
In [1]: names = ['Jack', 'Mike', 'Tom']
...: ages = [16, 32, 43]
...:
...: for i in range(len(names)):
...: print(names[i], '的年龄是:', ages[i])
...:
Jack 的年龄是: 16
Mike 的年龄是: 32
Tom 的年龄是: 43
4.2 进阶:zip
上述的解决方案有更好的替代。如果需要同时遍历多个可迭代对象,可以调用内置函数zip(类zip的
构造方法)将多个可迭代对象打包压缩成zip对象。
既可以遍历zip对象转换后的列表,也可以直接遍历zip对象。
In [2]: zip(names,ages)
Out[2]: <zip at 0x2988e404148>
In [3]: for name, age in zip(names, ages):
...: print(name, '的年龄是:', age)
...:
Jack 的年龄是: 16
Mike 的年龄是: 32
Tom 的年龄是: 43
调用内置函数zip将多个可迭代对象进行打包压缩时,如果两个可迭代对象的长度不同,
那么较长的可迭代对象会被截断。
In [1]: list(zip(range(3),range(5)))
Out[1]: [(0, 0), (1, 1), (2, 2)]
可以使用*对zip对象解压缩。
# 压缩:x,y -> [(x1,y1)...]
# 解压缩:[(x1,y1)..] -> x,y
In [1]: x = [1, 2, 3];y = [4, 5, 6]
In [2]: list(zip(x, y))
Out[2]: [(1, 4), (2, 5), (3, 6)]
In [3]: list(zip(*zip(x, y)))
Out[3]: [(1, 2, 3), (4, 5, 6)]
5. 遍历可迭代对象的内置函数map和filter
一、遍历可迭代对象的内置函数 map(func, *iterables)
第一个参数指定函数名,
第二个参数指定可迭代对象。
调用内置函数map后,会使用指定的函数名作用于指定的可迭代对象的每个元素,然后生成
新的可迭代对象。
In [1]: result = map(ord, 'abcd')
...: print(result)
...: print(list(result))
...:
<map object at 0x00000236722BF208>
[97, 98, 99, 100]
In [2]: result = map(str.upper, 'abcd')
...: print(result)
...: print(list(result))
...:
<map object at 0x00000236722BFD68>
['A', 'B', 'C', 'D']
二、用于遍历可迭代对象的内置函数 filter(function or None, iterable)
第一个参数指定函数名,
第二个参数指定可迭代对象。
调用内置函数filter后,会使用指定的函数名作用于指定的可迭代对象的每个元素,过滤掉
函数返回值为False的相关元素,然后生成新的可迭代对象
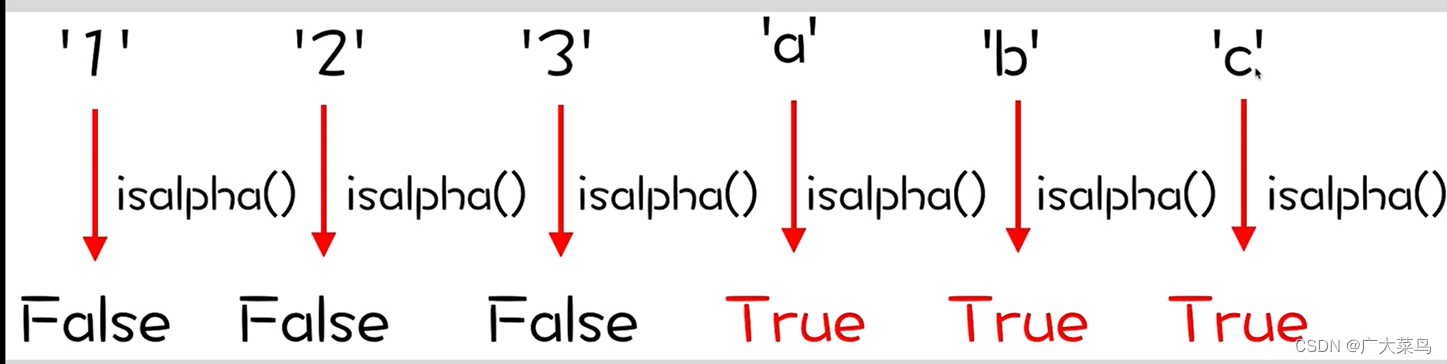
In [1]: filter(str.isalpha,'123abc')
Out[1]: <filter at 0x1b236517080>
In [2]: list(filter(str.isalpha,'123abc'))
Out[2]: ['a', 'b', 'c']
最后
以上就是彩色金针菇最近收集整理的关于Python 流程控制的小知识点的全部内容,更多相关Python内容请搜索靠谱客的其他文章。








发表评论 取消回复