文章目录
- 写在开始之前
- 什么是高效传输?
- 几个方案
- 类似阻塞,不成功就一直发送
- 事件驱动,被允许发送之后再发
- 接收缓冲区大小
- 测试对比
- 总结
本人博客 https://qinzheng7575.github.io/

写在开始之前
在听到这个单元的主题的时候,瞬间想起了在大三上学期那次字节的面试,被问到自己做过的项目的时候,就问我对于通信瓶颈怎么去判断、处理的,以前从来没有接触过这样的问题,也没有思考过这种多线程啊,多任务啊,搞并发问题。后来,自己好好看了python的并发,也算是了解了应用(主要是函数的应用),但是呢,显然了解语言、函数背后的思想更为重要。也是上面的遭遇,让我想要仔细的去学习这一章。????
什么是高效传输?
我们在利用网络传输消息的时候,当然期望能够尽可能压榨资源为我所用!也就是说要不停的send,直到系统承受不住send失败了为止。
问题来了,send失败了怎么办?立刻再开始下一次send?肯定不行,因为往往网络的堵塞是有持续性的,有极大概率会send失败。所以最好是等系统有能力的时候,立刻继续。
几个方案
类似阻塞,不成功就一直发送
我们可以设置一个templen代表已发送的全部数据,每次获取send的返回值加在templen上,直到等于想要发送的数据长度为止,否则一直在while循环里不停send。
显然这种不停的试错会加重系统的负担。
事件驱动,被允许发送之后再发
利用select实现一个时间驱动,当FD_SET(socket,&writefds)了,检查到可写了,再发送。
这种方案能够与系统有更好的配合,但是发送数据的缓冲、排序等会增加代码的复杂程度。
重点:缓冲区的设计
既然我们选择了“等一会”再发,那么在等待的时候,要发送的部分就该组织数据,并存在缓冲区了,这样才能够最大程度的利用好系统和网络的资源。**但是,单片缓存是不够的!**因为当网络空闲,发送很快的时候,一片缓存要等待发送结束之后才能重新装入要发的数据,这显然还是串行的,没有“流水线”。
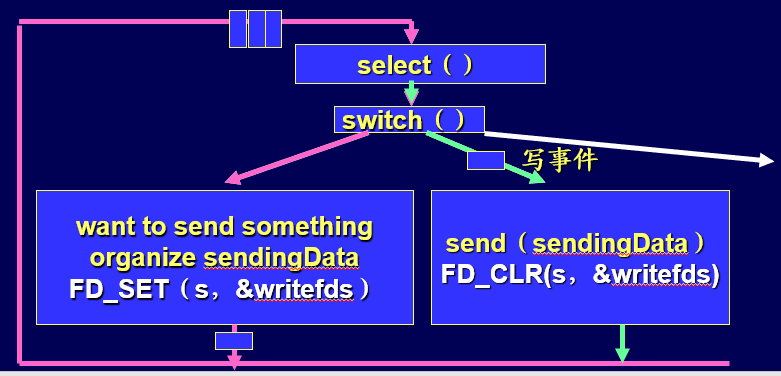
我们想做的,就是多块缓冲区,充分利用资源,保证在能发的时候就有数据发,在不能发的时候就等待并准备数据。
引入:缓冲队列
为什么要引入缓冲队列?因为在实际中,需要发送的进程不止一个,想一想有很多个进程,都在组织自己想发的东西,然后都通过socket发送出去,那么如果只有一个缓冲区,显然就不能够了,设置多个缓冲区就是为了减少阻塞,让多个进程在等待发送的时候先把要发的东西存下来,不影响别的工作。
如果服务器上不止一个socket,那么多个socket的缓冲队列合起来,就成为了一个缓冲池

当然,除了select的多路复用,我们还可以用多线程,为每个socket开一个线程,进行并发。如果进一步采用了多线程+select多路复用,那么就成为了一个线程池!
接收缓冲区大小
为什么说接收缓冲区的大小也会影响到程序的效率?如果是UDP,接收缓冲区不够会导致这个报文接收不完整,而且剩余的报文会直接丢弃,这样上层的应用自然会加大开销。而如果是TCP,那么虽然由于字节流的特点能够保留没有接收完的数据,但是也需要再次select,进入到writefds,再次接收,这就导致相较于大缓冲区需要多查询几次select,影响效率。
当然因为业务要求的不同,缓冲区的大小也需要具体情况而定,但是Linux的ioctl函数,能够查看在网卡收到的数据的大小,我们可以根据这个大小分配缓冲区大小,随后接受。也就是说先看一下要收多少,再确定缓冲区大小,不过当然会引入malloc的时延。
测试对比
这一段很重要,注重体会大/小缓冲区、缓冲队列长度、多线程与事件驱动之间的性能对比。见PPT《网络软件设计11——高效传输》
总结
- 发送失败是一定要处理的
- 多线程方案
- 一般情况下,因为代码简介且性能不差,成为最优选
- 在设计资源共享的时候,不一定是最好方案——为了可靠性和高性能
- select队列大小
- 要适当
- 可以多线程+基于select的并发方案
- 单片缓冲区的大小
- 不能太小
- 大流量压力下,可控范围内,应尽可能的大
http://libevent.org/
http://www.cppblog.com/xvsdf100/archive/2013/12/10/204689.html
*学习未停止,希望未来再接再厉!????
最后
以上就是开朗鸡最近收集整理的关于【C_socket】高并发、高性能通信软件设计写在开始之前什么是高效传输?测试对比总结的全部内容,更多相关【C_socket】高并发、高性能通信软件设计写在开始之前什么是高效传输内容请搜索靠谱客的其他文章。








发表评论 取消回复