从事Linux主机建设和运维的同事们在工作中应该经常会遇到批量修改配置信息或部署应用环境的需求,需要根据需求依次登录目标主机执行一些命令或脚本,使用shell脚本的循环语句是实现这一需求最直观方式。但是普通的for或do while循环都是串行执行的,脚本耗时每个循环耗时*循环次数,在较大规模实施或者目标语句耗时较长的情况下,串行方式的循环脚本执行时间也不容忽视。
要减少执行串行循环的耗时,自然要考虑如何用并行方式解决。在shell之外有一些现成的管理部署工具如parallel、ansible、puppet、saltstack都能解决并发执行多任务的问题,但生产系统一般不允许随意安装新软件,因而我们这里只讨论不借助工具,只使用shell脚本如何实现并发执行多任务。
串行执行循环时,脚本中每一次循环对应的子进程都是脚本执行所处shell的前台进程,同一时间一个shell只能有一个前台进程,要做到并行执行多个进程,意味着脚本中的循环要放到执行环境shell的后台,作为后台进程去执行。
直接使用后台执行
先来看下循环串行执行的情况。
脚本的循环内容以sleep为例,下同。
vim fork-0.sh
|
运行结果如下图所示:
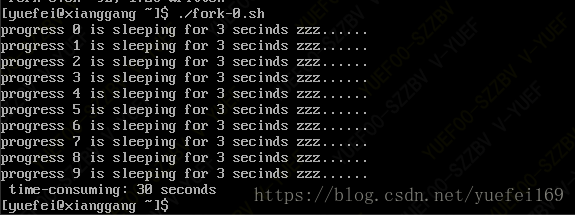
可以看到脚本执行时间30秒与预期10轮*3秒一致。
如果打开另一个窗口watch sleep进程的话,可以看到同一时刻只有1个sleep进程在跑:
修改脚本,采用循环并行执行的方式。
vim fork-1.sh
|
可以看到脚本执行耗时为3秒,与预期1轮*3秒一致。
watch sleep进程,可以看到同一时刻有10个PPID相同的sleep进程在跑:
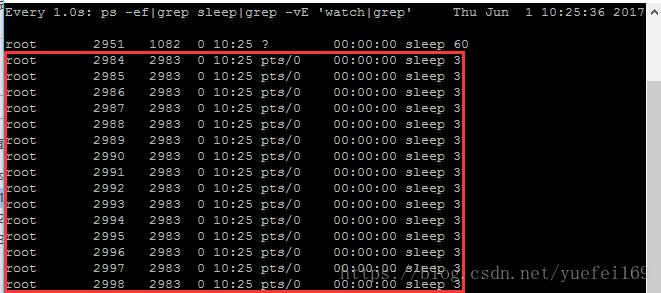
这种方式从功能上实现了使用shell脚本并行执行多个循环进程,但是它缺乏控制机制。
for设置了Njob次循环,同一时间Linux就触发Njob个进程一起执行。假设for里面执行的是scp,在没有pam_limits和cgroup限制的情况下,很有可能同一时刻过多的scp任务会耗尽系统的磁盘IO、连接数、带宽等资源,导致正常的业务受到影响。
一个应对办法是在for循环里面再嵌套一层循环,这样同一时间,系统最多只会执行内嵌循环限制值的个数的进程。不过还有一个问题,for后面的wait命令以循环中最慢的进程结束为结束(水桶效应)。如果嵌套循环中有某一个进程执行过程较慢,那么整体这一轮内嵌循环的执行时间就等于这个“慢”进程的执行时间,整体下来脚本的执行效率还是受到影响的。
2使用模拟队列来控制进程数量
要控制后台同一时刻的进程数量,需要在原有循环的基础上增加管理机制。
一个方法是以for循环的子进程PID做为队列元素,模拟一个限定最大进程数的队列(只是一个长度固定的数组,并不是真实的队列)。队列的初始长度为0,循环每创建一个进程,就让队列长度+1。当队列长度到达设置的并发进程限制数之后,每隔一段时间检查队列,如果队列长度还是等于限制值,那么不做操作,继续轮询;如果检测到有并发进程执行结束了,那么队列长度-1,轮询检测到队列长度小于限制值后,会启动下一个待执行的进程,直至所有等待执行的并发进程全部执行完。
vim para-2.sh
| #!/bin/bash Njob=15 #任务总数 Nproc=5 #最大并发进程数 function PushQue { #将PID值追加到队列中 Que="$Que $1" Nrun=$(($Nrun+1)) }
function GenQue { #更新队列信息,先清空队列信息,然后检索生成新的队列信息 OldQue=$Que Que=""; Nrun=0 for PID in $OldQue; do if [[ -d /proc/$PID ]]; then PushQue $PID fi done }
function ChkQue { #检查队列信息,如果有已经结束了的进程的PID,那么更新队列信息 OldQue=$Que for PID in $OldQue; do if [[ ! -d /proc/$PID ]]; then GenQue; break fi done }
for ((i=1; i<=$Njob; i++)); do echo "progress $i is sleeping for 3 seconds zzz…" sleep 3 & PID=$! PushQue $PID while [[ $Nrun -ge $Nproc ]]; do # 如果Nrun大于Nproc,就一直ChkQue ChkQue sleep 0.1 done done wait
echo -e "time-consuming: $SECONDS seconds" #显示脚本执行耗时#!/bin/bash |
运行结果如下图所示:
可以看到脚本执行时间9秒与预期3轮*3秒一致。
watch sleep进程,可以看到同一时刻只有5个sleep进程在跑,与我们限制的数量相符:
这种使用队列模型管理进程的方式在控制了后台进程数量的情况下,还能避免个别“慢”进程影响整体耗时的问题:
3使用fifo管道特性来控制进程数量
管道是内核中的一个单向的数据通道,同时也是一个数据队列。具有一个读取端与一个写入端,每一端对应着一个文件描述符。
命名管道即FIFO文件,通过命名管道可以在不相关的进程之间交换数据。FIFO有路径名与之相关联,以一种特殊设备文件形式存在于文件系统中。
FIFO有两种用途:
-
FIFO由shell使用以便数据从一条管道线传输到另一条,为此无需创建临时文件,常见的操作cat file|grepkeyword就是这种使用方式;
-
FIFO用于客户进程-服务器进程程序中,已在客户进程与服务器进程之间传送数据,下面的例子将使用这种方式。
根据FIFO文件的读规则,如果有进程写打开FIFO,且当前FIFO内没有数据,对于设置了阻塞标志的读操作来说,将一直阻塞状态。
利用这一特性可以实现一个令牌机制。设置一个行数等于限定最大进程数Nproc的fifo文件,在for循环中设置创建一个进程时先read一次fifo文件,进程结束时再write一次fifo文件。如果当前子进程数达到限定最大进程数Nproc,则fifo文件为空,后续执行的并发进程被读fifo命令阻塞,循环内容被没有触发,直至有某一个并发进程执行结果并做写操作(相当于将令牌还给池子)。
需要注意的是,当并发数较大时,多个并发进程即使在使用sleep相同秒数模拟时,也会存在进程调度的顺序问题,因而并不是按启动顺序结束的,可能会后启动的进程先结束。
vim para-3.sh
| #!/bin/bash Njob=15 #任务总数 Nproc=5 #最大并发进程数 mkfifo ./fifo.$$ && exec 777<> ./fifo.$$ && rm -f ./fifo.$$ #通过文件描述符777访问fifo文件 for ((i=0; i<$Nproc; i++)); do #向fifo文件先填充等于Nproc值的行数 echo "init time add $i" >&777 done
for ((i=0; i<$Njob; i++)); do { read -u 777 #从fifo文件读一行 echo "progress $i is sleeping for 3 seconds zzz…" sleep 3 echo "real time add $(($i+$Nproc))" 1>&777 #sleep完成后,向fifo文件重新写入一行 } & done wait echo -e "time-consuming: $SECONDS seconds" |
运行结果如下图所示:
可以看到脚本执行时间9秒与预期3轮*3秒一致。
watch sleep进程,同样可以看到同一时刻只有5个sleep进程。
4总结
并行多进程的循环语句能提高脚本执行效率。
例1这种没有控制机制,同一时间可能触发大量并发进程的脚本在生产环境中尽量避免使用,嵌套循环也尽量少用。
例2例3分别使用数组元素模拟队列和利用fifo读写阻塞性两种方式实现了后台进程数量的控制,适宜作为批量操作的shell脚本模版。
5后记
关于执行顺序的问题,把例2采用队列方式的例子中的动作 sleep 3修改成sleep$[$RANDOM/10000*5],执行结果仍然是顺序的。虽然例3的方式其执行过程是乱序的,考虑到如果使用脚本只是查询统计信息,可以利用Excel中的lookup、match、indirect函数进行信息整理,也是行得通的
最后
以上就是健忘秀发最近收集整理的关于shell脚本实现多进程的全部内容,更多相关shell脚本实现多进程内容请搜索靠谱客的其他文章。
![Linux中让进程(或正在运行的程序)到后台运行 Linux中如何让进程(或正在运行的程序)到后台运行?[zz]](https://www.shuijiaxian.com/files_image/reation/bcimg1.png)







发表评论 取消回复