以驱虫市场数据为例,挖掘某店铺新的业务方向和市场增长点。
联系微信sinoleadgolf
一.整体驱虫市场潜力分析
1.导包
import glob
import os
import pandas as pd
import re
import numpy as np
import datetime as dt
from sklearn.linear_model import LinearRegression
import seaborn as sns
from matplotlib import pyplot as plt
import jieba
import jieba.analyse
import imageio
from wordcloud import WordCloud
把可能用到的包都先导入进来,如果事先不知道,也先不用管,后边再补充包进来,几个基础的包 pandas numpy matplotlib,大家开始工作前 也会自己习惯性的导入。不能导入的包在网上查一下 打开 cmd 然后 pip install + …先安装。
os.chdir("D:/data/python")
os.chdir("./驱虫剂市场")
这里把工作路径调整到当前的文件夹。
2.加载数据
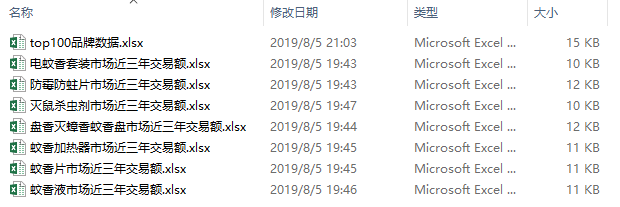
filenames = glob.glob('*市场近三年交易额.xlsx')
filenames
这段代码将文件夹下,以 市场近三年交易额.xlsx 结尾的文件 的文件名称 都拿到,其中*表示前面的任意所有字符。
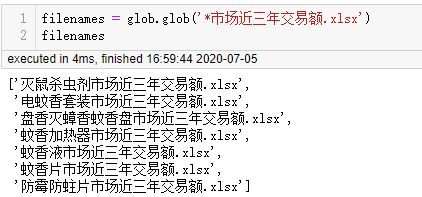
在定义函数 批量导入数据前,先查看 每一个文件名,同时用re正则表达式 提取出市场前面的字符,更改时间戳格式,这三项 后边在定义函数时会用到。
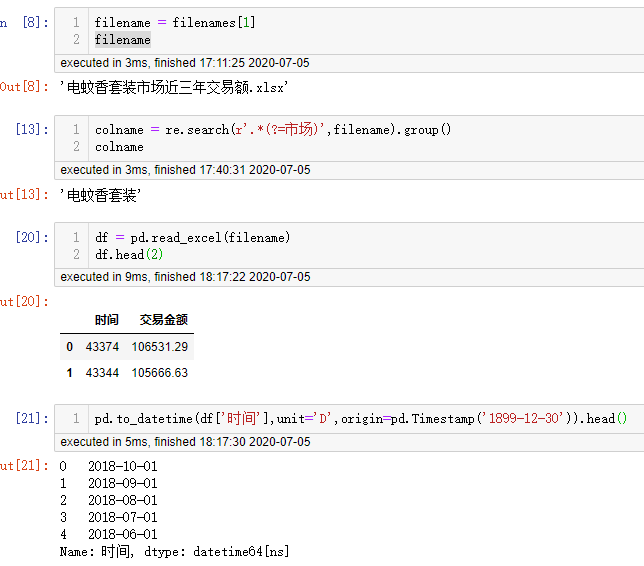
凡是涉及到文本处理通常用到 正则表达式re 常用的两个方法 找search 和 替换sub,re.search(通过什么模式,要找的对象)。 .group()的意思是返回找的内容。在使用正则表达式re前 建议先提前3个小时去官网https://docs.python.org/zh-tw/3.7/library/re.html 熟悉好(官网可切换中文)正则表达式的应用形式很多 不同模式的组合很多 需要在实际使用中去熟练。上图中的43374就是时间戳,下面的语句是按照规则改成通常用的时间格式。接下来定义函数 批量导入数据。
def load_xlsx(filename):
colname = re.search(r'.*(?=市场)',filename).group()
df = pd.read_excel(filename)
if df['时间'].dtypes == 'int64':
df['时间'] = pd.to_datetime(df['时间'],unit='D',origin=pd.Timestamp('1899-12-30'))
df.rename(columns={df.columns[1]:colname},inplace=True)
df = df.set_index('时间')
return df
dfs = [load_xlsx(i) for i in filenames]
dfs
这样所有的文件都读到一张叫 dfs 的大列表中了。下面将这张大表内的各个小表依照时间进行横向合并。
df = pd.concat(dfs,axis=1).reset_index()
df
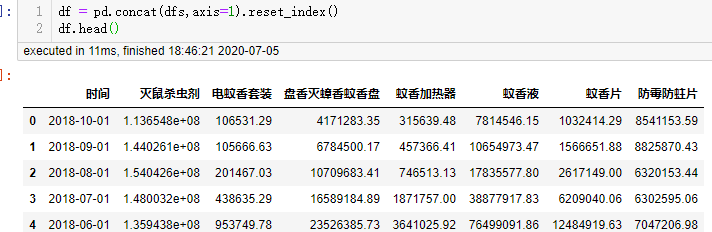
3.数据清洗
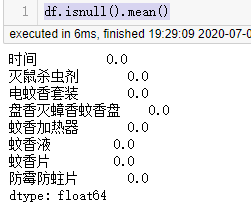
查看缺失值占比
df.isnull().mean()
循环预测2018年11月和12月的销售金额
month = df['时间'].dt.month
for i in [11,12]:
# 收取对应月份数据
dm = df[month == i]
# 训练x是年份
xtrain = np.array(dm['时间'].dt.year).reshape(-1,1)
# 测试y是新增加的行,第一列是对应的日期
ytest = [pd.datetime(2018,i,1)]
for j in range(1,len(dm.columns)):
# 训练y是指定的j列
ytrain = np.array(dm.iloc[:,j]).reshape(-1,1)
# 回归建模
lm = LinearRegression().fit(xtrain,ytrain)
# 预测当测试x是2018时的交易金额yhat
yhat = lm.predict(np.array([2018]).reshape(-1,1))
# 对应列的预测值附在新增加的行后
ytest.append(round(yhat[0][0],2))
# 给预测结果赋值对应的列名
newrow = pd.DataFrame([dict(zip(df.columns,ytest))])
# 预测结果行加在数据前
df = newrow.append(df)
这段代码是线性回归建模,根据16、16、17年11月和12月的数据来预测 2018年 这两个月的销售额,用到from sklearn.linear_model import LinearRegression。详细可在网上查找线性回归建模的使用。
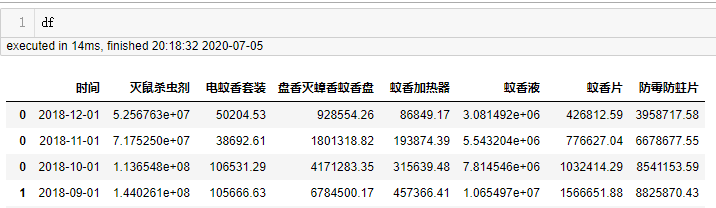
这样就补充了2018年11月和12月的销售数据,就可以以年为维度 看整体2016-2018年三年的行业整体趋势。
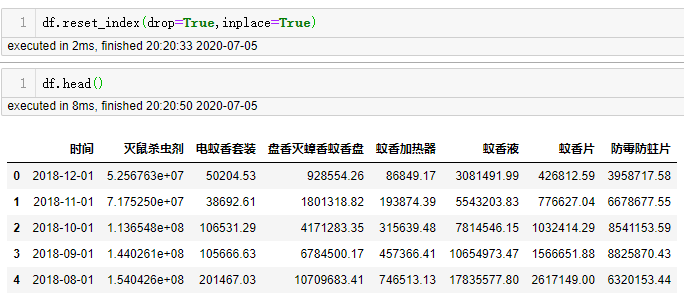
上图中的索引乱了0001,所以要重新设置索引,用代码
df.reset_index(drop=True,inplace=True)
去掉不用的2015年的数据
df = df[df['时间'].dt.year!=2015]
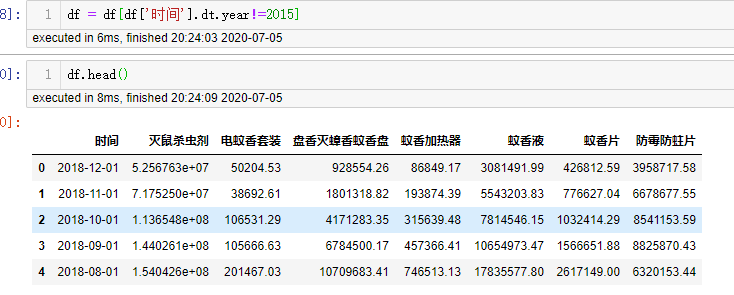
这便是我们最终用的数据!
数据规整完 下一步我们进行市场的分析!
原文链接:https://blog.csdn.net/wusheng9922/article/details/107141094
最后
以上就是自信茉莉最近收集整理的关于python怎么样用到电商上去_怎么用python电商文本挖掘?(1)的全部内容,更多相关python怎么样用到电商上去_怎么用python电商文本挖掘内容请搜索靠谱客的其他文章。








发表评论 取消回复