今天开始大规模爬取数据了,花了5个小时爬了700多万条的数据,从来没做过大数据分析,不知道这是啥概念,但直觉太多了。
一、python日志文件
运行程序在自动爬取数据,已经进行了好长时间,突然发现程序自动关闭了,也没有出现任何异常错误。但是问题就来了,那么程序结束时爬取到哪里了呢?这时候就十分需要日志文件,来记录程序执行过程。
感谢下列文章,作者指出‘培养码代码的好习惯,设置日志,打印程序运行中的细节,以便调试代码’。
(文本挖掘从小白到精通(二)---语料库和词向量空间,来源Scottish Fold Cats Social Listening与文本挖掘 2019-05-08)
代码如下,注意,要生成log文件的话,一定要加上filemode="w",不然写不进去。
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO,filemode="w",filename=r"E:/Result/logmsg.log")
二、Python 自定义模块的相互应用
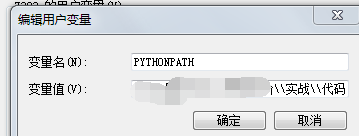
在pycharm中建立了多个python文件,各个文件间,可以相互引用。用‘import 文件名’的形式进行引用。注意:这些文件要在同一个文件夹中,并且要设置环境变量,变量名为“PYTHONPATH”,变量值为这些代码所在的目录。
三、用python找出一个txt文件中的重复数据,并将重复数据输出成另一个txt文件(来自网络)
原文链接:https://blog.csdn.net/zouxiaolv/article/details/101541920
假设你的文件名是a.txt,写到b.txt
d = {}
for line in open('a.txt'):
d[line] = d.get(line, 0) + 1
fd = open('b.txt', 'w')
for k, v in d.items():
if v > 1:
fd.write(k)
fd.close()
四、20210401续:昨天在读取stopwords文件时报错:pandas.errors.ParserError: Error tokenizing data. C error: Expected 1 fields in line 3, saw 3
百度发现:一篇博文有解决办法(https://blog.csdn.net/alicelmx/article/details/83902760)
在使用pandas读取csv文件时报以上错误,解决办法,如下:
pd.read_csv(filename,error_bad_lines=False)
在pd.read_csv的括号内加上error_bad_lines=F就可以了,它就会自动跳过不合适的行而不报错
最后
以上就是兴奋钢笔最近收集整理的关于python 文本挖掘 实战中遇到的问题的全部内容,更多相关python内容请搜索靠谱客的其他文章。








发表评论 取消回复