- 最近完成神经网络的大作业,要求使用KNN对消极和积极的英文评论进行分析,以消极和积极评论各2995条样例作为样本集进行实验,并且通过各2000条测试样例作为测试集判断准确率。
- 代码没有调用sklearn库,所有的代码都是博主手写,数据集放在了本文的最后。
- 情感分析是根据文本所表达的含义和情感信息将文本划分成褒扬和贬义两种类型。目前,比较常用的分类算法有: 支持向量机 (SVM)、 贝叶斯
(NB)、K-近邻 (KNN)等,其中 KNN 方法有着广泛的应用领域。 情感分析的步骤一般如下:

目录
- 1. 文本向量化
- 2. 特征选择
- 2.1 方差选择法
- 2.2 皮尔逊相关系数法
- 3. KNN分类器
- 4.总结
- 5.所有代码
1. 文本向量化
-
文本向量化是情感分析中必须要经历的一步,为了便于计算文档之间的相似度,进行分类处理,我们需把文档转成统一空间的向量。
-
为了计算文档之间的相似度,在英文中,我们可以忽略文档内的单词顺序和语法、句法等要素,将其仅仅看作是单词的集合。在情感分析中,我们将消极语料库和积极语料库进行向量表示。
-
在文本向量化的过程中,句子中会出现停用词,所谓停用词就是非常常见且实际意义有限的词,如英文中“the”, “a”, “of”, “an”
等。这些词几乎可能出现在所有场合,因而对某些应用如信息检索、文本分类等区分度不大。所以在文本向量化的过程中,我们要将这些停用词删掉。 -
我们还需要统计单词在文本中出现的频率,即计算词条的权重。比较Tf - idf 和布尔权重两种计算词条权重的方法,发现Tf – idf
的正确率略高一点,为了节约时间成本,在这里计算权重时我们使用布尔权重法来计算。 文本向量化的步骤具体如下:- 将文件夹中的文本导入进行程序中
- 按照词对语料库进行文本的划分
- 删除文本中的停用词
- 计算词条出现的权重
-
代码如下:
# 删除停用词
def delete_stopwords(word_lst):
lst_add = ['could','will','can','would','also']
text_collection = []
wordnet_lematizer = WordNetLemmatizer() # 统一单词的形式,比如将三单原型化
new_word_lst = []
for j in range(len(word_lst)):
lst1 = []
token_words = pos_tag(word_lst[j])
for word,tag in token_words:
if word not in stopwords.words('english'): # 提取所有形容词,并且将他们统一单词的形式,比如将三单原型化
new_word = wordnet_lematizer.lemmatize(word)
lst1.append(new_word)
if new_word not in text_collection and new_word not in lst_add:
text_collection.append(new_word)
if lst1 != []:
new_word_lst.append(lst1)
return new_word_lst,text_collection
def text_CountVectorizer(new_word_lst,text_collection):
num_collection = len(text_collection)
num_text = len(new_word_lst)
array_text = np.zeros((num_text,num_collection), dtype=int)
for i in range(num_text):
for j in range(len(new_word_lst[i])):
if new_word_lst[i][j] in text_collection:
place = text_collection.index(new_word_lst[i][j])
array_text[i][place] += 1
return array_text
2. 特征选择
- 虽然我们已经删除了停用词,但在文本中还有许多与学习任务没有帮助的特征。加入这些特征会影响对文本的判断,所以我们下一步要删除这些词汇,通过降低维度来提升模型的效率。
- 常见的特征选择方法有: 方差选择法,皮尔逊相关系数法(Pearson correlation coefficient),基于森林的特征选择法,递归特征消除法。情感分析常用的两种方法是:方差选择法和皮尔森相关系数法。
2.1 方差选择法
- 原理:方差非常小的特征维度对样本的区分作用很小,因此在特征选取中我们可以剔除这些特征值。
- 方法:1. 计算每个特征的方差。2. 根据阈值,保留方差大于阈值的特征。
- 这里我们阈值选取0.001正确率最高
- 具体代码如下:
def feature_Var_selection(array_text,text_collection):
array_text_new = array_text.T
yuzhi = 0.0595
delete_lst = []
for i in range(array_text_new.shape[0]):
var_line = np.var(array_text_new[i])
if var_line < yuzhi:
delete_lst.append(i)
array_text = np.delete(array_text, delete_lst, axis=1)
lst_word = [text_collection[i] for i in range(len(text_collection)) if i not in delete_lst]
return array_text,lst_word
2.2 皮尔逊相关系数法
- 原理:显示两个随机变量之间线性关系的强度和方向。计算公式为:
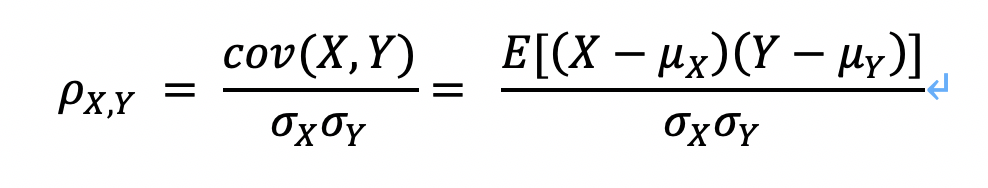
其中,???????????? ????, ???? 表示???? 和????之间的协方差(Covariance) σ_X是????的均方差,μ_X是????的均值,????表示数学期望 - 方法:用上述公式将与目标相关性较小的特征过滤掉。相关系数的绝对值越大,相关性越强,相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
通常情况下通过以下取值范围判断变量的相关强度:
相关系数 0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
这里我们选择阈值为0.06效率最高
- 具体代码如下:
def Person(array_text,text_collection, len_negative, len_positive):
yuzhi = 0.06
delete_lst = []
array_negative = np.zeros(len_negative)
array_positive = np.ones(len_positive)
vb = np.hstack((array_negative, array_positive))
num = array_text.shape[1]
for i in range(num):
vc = array_text[:,i]
co = np.mean(np.multiply((vc - np.mean(vc)), (vb - np.mean(vb)))) / (np.std(vb) * np.std(vc))
if abs(co) < yuzhi:
delete_lst.append(i)
array_text = np.delete(array_text, delete_lst, axis=1)
lst_word = [text_collection[i] for i in range(len(text_collection)) if i not in delete_lst]
return array_text,lst_word
3. KNN分类器
- KNN算法是常见的分类算法之一,属于有监督学习中的分类算法,全称为K-Nearest
Neighbor。KNN算法的工作方法是将测试集中的每个特征与样本集中的特征进行比较,然后提取前k个最相似的数据标签,比较出现的频率,最后将频率最高的类别作为分类的结果输出。 - KNN算法的基本步骤是对测试集中的每个点依次执行以下操作:
- 计算训练集中的点与当前点之间的距离;
- 按照距离递增次序排序;
- 选取与当前点距离最小的 k 个点;
- 确定前 k 个点所在类别的出现频率;
- 返回前 k个点出现频率最高的类别作为当前点的预测分类。
- 这里两个n维向量点A(A1,A2,…,An) 与B(B1,B2, …,Bn ) 之间的距离选用欧式距离公式:
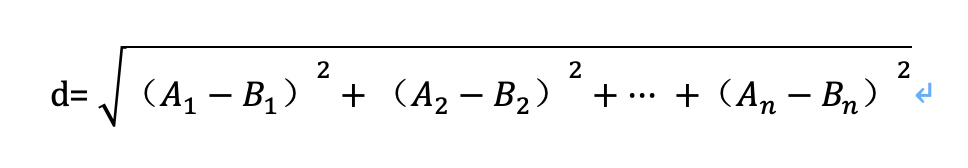
def KNN(array_train, array_text,k):
negative_correct = 0 ; positive_correct =0
train_len = len(array_train)
text_len = len(array_text)
for i in range(text_len): # 计算每一组数的距离
dis = []
for j in range(train_len):
temp_dis = sqrt(np.sum((array_train[j] - array_text[i])**2)) # 计算距离
dis.append(temp_dis)
dis = np.array(dis)
sort_id = dis.argsort() #返回原数组的下标
dic = {'negative' : 0, 'positive' : 0}
# 对于前排在前面k个元素进行统计,从而判断是negative还是positive。
for w in range(k):
num = sort_id[w] # 为对应的标签记数
if num <= train_len/2:
dic['negative'] += 1
else:
dic['positive'] += 1
if dic['negative'] > dic['positive'] and i < text_len/2 :
negative_correct += 1
if dic['negative'] < dic['positive'] and i >= text_len/2:
positive_correct += 1
print(negative_correct,positive_correct)
return negative_correct/(text_len/2), positive_correct/(text_len/2)
4.总结
在情感分析中,使用皮尔森相关系数法要比方差选择法效率更高,在这种方法中,通过计算每一个特征和标签的相关系数,留下少量能够表达情感特点的特征词,比如在样本集中抽取出的:消极词汇:poor,ridiculous, boring ;积极词汇:laughable, amazing, fascinating。
该方法不仅检测数据的运行时间短,还避免了干扰项对最后结果的判断,所以正确率也有很大的提升,本文认为在情感分析中这是一种很好的提高效率和准确率的方法。
通过不断实验我们发现阈值选择0.06,k值选择15时正确率和时间效率最高,可以保持在70%以上,对样本的分析时间13分钟左右
5.所有代码
from math import sqrt
import re
import numpy as np
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk import pos_tag
from time import *
def delete_stopwords(word_lst):
lst_add = ['could','will','can','would','also']
text_collection = []
wordnet_lematizer = WordNetLemmatizer() # 统一单词的形式,比如将三单原型化
new_word_lst = []
for j in range(len(word_lst)):
lst1 = []
token_words = pos_tag(word_lst[j])
for word,tag in token_words:
if word not in stopwords.words('english'): # 提取所有形容词,并且将他们统一单词的形式,比如将三单原型化
new_word = wordnet_lematizer.lemmatize(word)
lst1.append(new_word)
if new_word not in text_collection and new_word not in lst_add:
text_collection.append(new_word)
if lst1 != []:
new_word_lst.append(lst1)
return new_word_lst,text_collection
# 将文本向量化
def text_CountVectorizer(new_word_lst,text_collection):
num_collection = len(text_collection)
num_text = len(new_word_lst)
array_text = np.zeros((num_text,num_collection), dtype=int)
for i in range(num_text):
for j in range(len(new_word_lst[i])):
if new_word_lst[i][j] in text_collection:
place = text_collection.index(new_word_lst[i][j])
array_text[i][place] += 1
return array_text
# 皮尔森相关系数法
def Person(array_text,text_collection, len_negative, len_positive):
yuzhi = 0.06
delete_lst = []
array_negative = np.zeros(len_negative)
array_positive = np.ones(len_positive)
vb = np.hstack((array_negative, array_positive))
num = array_text.shape[1]
for i in range(num):
vc = array_text[:,i]
co = np.mean(np.multiply((vc - np.mean(vc)), (vb - np.mean(vb)))) / (np.std(vb) * np.std(vc))
if abs(co) < yuzhi:
delete_lst.append(i)
array_text = np.delete(array_text, delete_lst, axis=1)
lst_word = [text_collection[i] for i in range(len(text_collection)) if i not in delete_lst]
return array_text,lst_word
# 方差选择法
def feature_Var_selection(array_text,text_collection):
array_text_new = array_text.T
yuzhi = 0.0595
delete_lst = []
for i in range(array_text_new.shape[0]):
var_line = np.var(array_text_new[i])
if var_line < yuzhi:
delete_lst.append(i)
array_text = np.delete(array_text, delete_lst, axis=1)
lst_word = [text_collection[i] for i in range(len(text_collection)) if i not in delete_lst]
return array_text,lst_word
# 将文本文件以数组的形式输出
def input_test(where_from,num):
s1 = open(where_from, 'r')
X = s1.readlines()
lst = []
for i in range(num):
lst1 = re.compile(r'b[a-zA-Z-]+b', re.I).findall(X[i])
lst.append(lst1)
return lst
def KNN(array_train, array_text,k):
negative_correct = 0 ; positive_correct =0
train_len = len(array_train)
text_len = len(array_text)
for i in range(text_len): # 计算每一组数的距离
dis = []
for j in range(train_len):
temp_dis = sqrt(np.sum((array_train[j] - array_text[i])**2)) # 计算距离
dis.append(temp_dis)
dis = np.array(dis)
sort_id = dis.argsort() #返回原数组的下标
dic = {'negative' : 0, 'positive' : 0}
# 对于前排在前面k个元素进行统计,从而判断是negative还是positive。
for w in range(k):
num = sort_id[w] # 为对应的标签记数
if num <= train_len/2:
dic['negative'] += 1
else:
dic['positive'] += 1
if dic['negative'] > dic['positive'] and i < text_len/2 :
negative_correct += 1
if dic['negative'] < dic['positive'] and i >= text_len/2:
positive_correct += 1
print(negative_correct,positive_correct)
return negative_correct/(text_len/2), positive_correct/(text_len/2)
def main():
begin_time = time()
tr_negative = input_test('venv/train_negative.txt',2995)
tr_positive = input_test('venv/train_positive.txt',2995)
te_negative = input_test('venv/test_negative.txt',2000)
te_positive = input_test('venv/test_positive.txt',2000)
train_lst = tr_negative + tr_positive
text_lst = te_negative + te_positive
# 输出训练集的向量组
lst1, word_lst_train = delete_stopwords(train_lst)
array_train = text_CountVectorizer(lst1, word_lst_train)
array_train, word_train = Person(array_train, word_lst_train, 2995, 2995)
print('训练集的特征数目是:', len(word_train))
end_time_train = time()
run_time_train = end_time_train - begin_time
print('训练的时间是:', str(run_time_train)+'s')
# 输出测试集的向量组
lst2, word_lst_text = delete_stopwords(text_lst)
array_text = text_CountVectorizer(lst2, word_train) # 这里的向量化是根据训练集的词库生成的
k = 25
negative_correct, positive_correct = KNN(array_train, array_text,k)
print('此时的k值是',k)
end_time_text = time()
run_time_text = end_time_text - end_time_train
print('测试的时间是:', str(run_time_text)+'s')
run_time = end_time_text - begin_time
print('总运行的时间是', str(run_time)+'s')
print('消极和积极文本分析的正确率分别是:',negative_correct, positive_correct)
print('总正确率是',end = '')
return (negative_correct+positive_correct)/2
if __name__ == '__main__':
print(main())
样本集和测试集:
http://share.weiyun.com/5GNMKZm 密码:642c54
最后
以上就是调皮菠萝最近收集整理的关于神经网络实战之利用KNN进行情感分析 python实现 不使用sklearn库1. 文本向量化2. 特征选择3. KNN分类器4.总结5.所有代码的全部内容,更多相关神经网络实战之利用KNN进行情感分析内容请搜索靠谱客的其他文章。








发表评论 取消回复