朴素贝叶斯分类器是一种众所周知的机器学习分类器,应用于自然语言处理(NLP)和其他领域。尽管它很简单,但它能够在不同的任务中实现高于平均水平的表现,例如情绪分析。今天我们将详细阐述该模型的核心原理,然后在Python中实现它。最后,我们将看到我们对2000年电影评论数据集的表现如何。
核心
如果您熟悉某些数学符号,那么这个模型背后的数学并不是特别难以理解。对于那些不了解的人,我会尽我所能详细解释这些。先正确地将评论分类为正面或负面。这是每个文档所属的两个类。
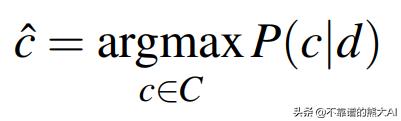
在更多的术语中,我们希望找到给定文档的最可能的类,这正是上面的公式所传达的。C是所有可能类的集合,c是这些类中的一个,d是我们当前正在分类的文档。我们把P(c|d)看成是给定文档d的c类的概率。
我们可以使用众所周知的贝叶斯规则重写这个等式,这是机器学习中最基本的规则之一。由于我们想要最大化方程,我们可以去掉分母,这不依赖于c类。
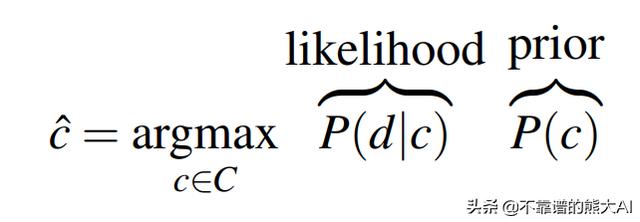
我们的分类器目标的重写形式自然地将其分为两部分,即可能性和先验。您可以将后者视为“给定c类,文档d属于它的概率”,前者为“具有来自c类的文档的概率”。为了更进一步,我们需要引入给这个模型命名的假设。
朴素贝叶斯假设:给定一个c类,文档中某个单独特征的存在与其他特征无关。
我们认为文档中的每个单词都是一个特征。如果我们正式地写下来,得到:
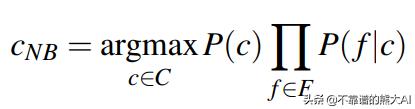
朴素贝叶斯假设我们把P(d|c)代入与类相关的每个特征的概率的乘积因为它假设它们是独立的。
我们可以再做一次更改:使函数的对数最大化。
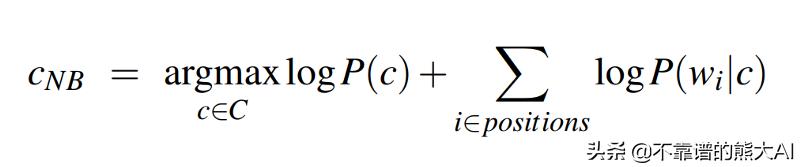
- P(c)只是在我们的语料库中遇到某个类的文档的概率。只需将c类的出现次数除以文档总数即可轻松计算出来。
- P(w_ i | c)是在c类的文档中出现单词w_i的概率。我们再次使用语料库中的频率来计算它。这就是单词w_i出现在c类文档中的次数,除以出现在类c文档中的每个单词的计数之和。
我们可以计算公式中的所有项,这意味着我们可以计算最可能的测试文档类。我们需要处理的问题只有一个:零概率。
Smoothing(平滑)
想象一下,您正在尝试对包含“stupendous”这个词的评论进行分类,而你的分类器之前没有看过这个词。当然,概率P(w_i | c)将为0,使得我们方程的第二项变为负无穷大。这是NLP中的常见问题,但是它有一个简单的解决方法:Smoothing。这种技术包括在P(w_i | c)公式中的每个计数添加一个常数,最基本的Smoothing类型称为add-one(拉普拉斯)平滑,其中常量仅为1。
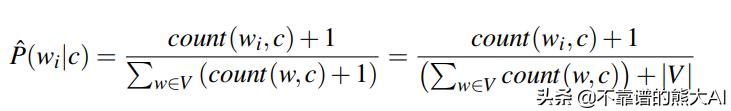
Add-one/拉普拉斯平滑
这解决了零概率问题,我们稍后会看到它对模型准确性的影响程度。
实现
我们将以朴素贝叶斯分类器类的形式实现我们的分类器。我们将算法分为两个基本部分,即训练和分类。
训练
在这个阶段,我们为分类器提供了一个大型文本语料库,表示为D,它计算出了计算重新表述的两项所需的所有计数。

朴素贝叶斯训练的伪代码
在实现时,虽然伪代码以循环遍历所有类开始,但我们将首先计算在循环之前不依赖于c类的所有内容。这是N_doc,词汇表和所有类的集合的情况。
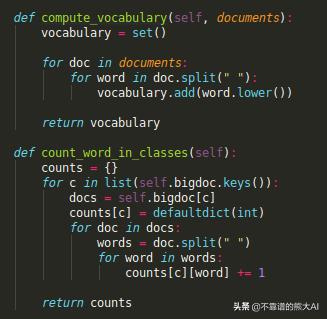
辅助函数
由于在计算单词计数时需要bigdoc,所以我们也在循环之前计算它。
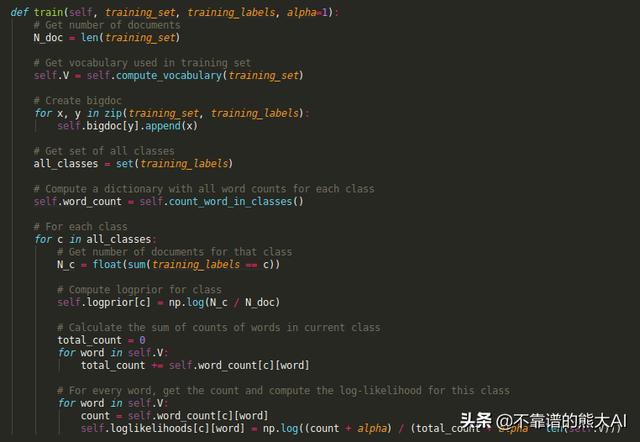
训练函数
在循环中,我们只遵循伪代码中给出的顺序。
- 首先,我们计算c类中D的文档数量。
- 然后我们计算特定类的logprior。
- 接下来,我们对词汇表进行循环,这样我们就可以得到c类中词汇量的总数。
- 最后,我们使用平滑法来计算c类中每个单词的对数概率,以避免被零分割的错误。
分类
训练完成后,我们拥有所有必要的值来进行预测。这将简单地包括获取一个新的文档并计算在训练期间观察到的每个类的概率。

分类部分的伪代码
我们初始化sums字典,我们将存储每个类的概率。我们总是计算所有类的概率,所以函数自然会通过对它们进行循环来开始。对于每个c类,我们首先添加logprior,即概率方程的第一项。第二个术语要求我们循环所有单词,并将当前概率增加每个单词的对数似然。
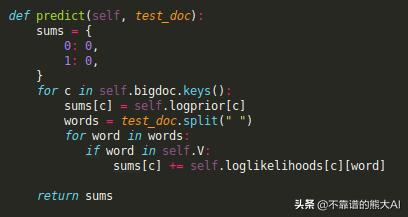
预测执行
一旦完成,我们就可以获得字典最大值的键,我们有一个预测。我们现在准备好看看朴素贝叶斯的行动。
数据
我们将在具有1000个正面和1000个负面电影评论的数据集上测试我们的模型。每个文档都是一个评论,由一个或多个句子组成。
我们将数据分成包含90%评论的训练集和包含剩余10%的测试集。前者用于train函数训练模型,而后者将使我们了解模型对不可见数据的泛化程度。
一旦完成,我们需要某种基线来比较我们的模型的准确性,否则我们无法确切地说它有多好。由于这是一个二元分类任务,我们至少知道,随机猜测的平均准确率应该在50%左右。任何接近这个数字的东西都是随机猜测。
结果
让我们从头到尾看一下算法的完整实现。

我们所要做的就是创建分类器,对其进行训练并使用验证集来检查其准确性。我省略了辅助函数来创建用于训练和验证的集合和标签。让我们通过将alpha设置为0并运行它来看看我们的模型如何在没有平滑的情况下完成
Predicted correctly 101 out of 202 (50.0%)Ran in 1.016 seconds即使不做平滑处理,我们至少也会比平均水平好一点。让我们添加平滑
Predicted correctly 167 out of 202 (82.67327%)Ran in 0.961 seconds现在这是准确的。平滑使我们的模型足以正确分类至少5个评论中的4个,这是一个非常好的结果。我们还看到,训练和预测总共花费的时间不超过1秒,这对于具有2000条评论的数据集而言是相对较低的运行时间。
结论
正如我们所看到的,即使朴素贝叶斯算法的一个非常基本的实现也可以为情绪分析的任务带来非常好的结果。请注意,这个模型本质上是一个二元分类器,这意味着它可以应用于我们有两个类别的任何数据集。它有各种各样的应用程序,例:垃圾邮件检测、简单情感分析。82%的准确率已经相当高了,你需要的只是标记数据集,当然数据集越大越好!
最后
以上就是天真刺猬最近收集整理的关于python表示无穷大_在Python中实现用于情绪分析的朴素贝叶斯的全部内容,更多相关python表示无穷大_在Python中实现用于情绪分析内容请搜索靠谱客的其他文章。








发表评论 取消回复