作者介绍
@贾少华
内蒙古大学计算机学院硕士,前某IT公司数据挖掘工程师;
现某乳业资源规划高级专员,负责业务数据化工作;
目前迷醉于经济与计算机的融合,坚信可解释性神经网络会带来更大的市场需求和学术进展;
深度中二少年,动漫无敌;
“数据人创作者联盟”成员。
1 理论介绍
LDA(Latent Dirichlet Allocation)于2003年BLei在论文中提出,该模型立足于LSA(Latent Senmantic Analysis与pLSI(probabilistic Latent Senmantic Analysis)模型,是一种更完善、成熟的概率主题模型。即LDA模型通过引入超参数的概念,使得整个模型较之pLSI更加概率化,形成了三层贝叶斯网络结构。LDA概率图模型见图1。
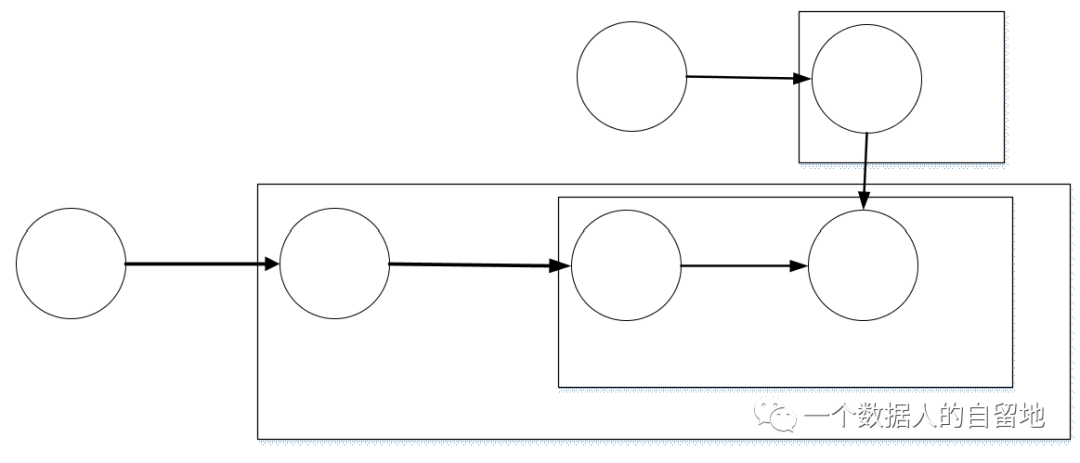
图1. 传统LDA模型
LDA模型意在寻求一篇文档中蕴含的潜在主题,其中对于潜在主题的个数一般通过困惑度亦或是对数似然值来确定。通常,一篇文档有包含多个部分,每个部分有N多词构成,也就是说由N多词构成一个个主题,而后由一个个主题构成了一篇文档。
对于文档集D中的每个文档w,LDA假设了以下的生成过程:
1)
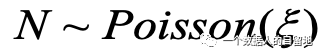
2)
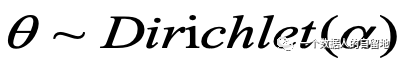
3)对于
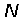
个单词中的每一个单词
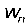
:
(a)
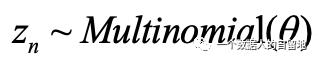
(b)从
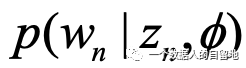
中选择一个单词
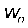
;
LDA模型中,需要估计的参数有两个,分别为θ和φ,即文档-主题概分布与主题-词概率分布。因使用EM对θ和φ进行参数估计的方法难以通过代码实现,故而在后续的模型学习与实现中,通常采用Gibbs抽样对这两个参数进行值的估计。
2 数据准备
此次Demo实验选取部分Yelp电商评论中的文本部分,其中评论有真有假,分别对真实评论和虚假评论进行主题抽取。其中表一展示的是一条原始的评论数据集和对应的清洗干净的数据集。
表1原始数据与干净数据
| reviewContent | Clean_review |
| Service was impeccable. Experience and presentation was cool. Eating a balloon was fun. Trying to make a reservation was ridiculous. Food was not mouth watering, tasted like it it was made in a lab. I appreciate delicious food, so I don't get the hype here. | service, impeccable, experience, presentation, cool, eating, balloon, fun, reservation, ridiculous, food, mouth, watering, tasted, lab, delicious, food, dont, hype |
当数据量较小的时候,LDA抽取的主题代表性不强,因此此处为了扩大建模的单词量,将真实评论合并为一个文档,虚假评论合并为一个文档,分别使用LDA对其进行建模,主题抽取结果如表2,表3所示。
表2 真实评论主题抽取
| Topic1 | Topic2 | Topic3 | Topic4 | Topic5 |
| promise | park | stones | writing | cube |
| quality | comments | discarded | reserve | parings |
| pushy | ramps | split | injure | shined |
| rationalize | edge | eavesdrop | damn | pomp |
| podium | cliff | strict | autographed | bamboo |
| decorated | spray | breadth | hate | heroin |
| peeled | shots | settle | zealand | absurd |
| gulped | care | swirling | olfactory | unsalted |
|
| comments | discarded | reserve | parings |
| pushy | ramps | split | injure | shined |
| rationalize | edge | eavesdrop | damn | pomp |
| podium | cliff | strict | autographed | bamboo |
| decorated | spray | breadth | hate | heroin |
| peeled | shots | settle | zealand | absurd |
| gulped | care | swirling | olfactory | unsalted |
表3 虚假评论主题抽取
| Topic1 | Topic2 | Topic3 | Topic4 | Topic5 |
| extremely | decadent | confirmed | prospect | collective |
| burnt | entertain | duke | eaten | smiled |
| vaguely | hiccup | warm | previous | cultural |
| arrives | successor | pour | night | mystery |
| content | troubles | laugh | dish | smothering |
| unstuck | mustards | transmogrify | completely | observing |
| twists | brighter | care | recognizable | kindle |
| redefining | responds | school | notable | tire |
附录:代码(python3.6,jupyter notebook)


最后
以上就是寂寞大侠最近收集整理的关于基于LDA的电商评论主题抽取的全部内容,更多相关基于LDA内容请搜索靠谱客的其他文章。








发表评论 取消回复