因为实习的缘故,所以有机会接触到了自然语言处理的一些方面。
这里主要总结一下在python环境下进行自然语言处理的相关包和可能会出现的相关错误,目前接触的都比较Low,但是还是想要记录下来。
Nltk是python下处理语言的主要工具包,可以实现去除停用词、词性标注以及分词和分句等。
安装nltk,我写python一般使用的是集成环境EPD,其中有包管理,可以在线进行安装。如果不是集成环境,可以通过pip install nltk安装。
》pip install nltk #安装nltk
》nltk.download() #弹出一个选择框,可以按照自己需要的语义或者是功能进行安装
一般要实现分词,分句,以及词性标注和去除停用词的功能时,需要安装stopwords,punkt以及
当出现LookupError时一般就是由于缺少相关模块所导致的
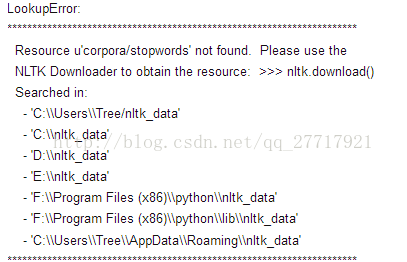
就是没有安装stopwords所导致的,可以手动安装,也可以
》nltk.download(‘stopwords’)
如果出现
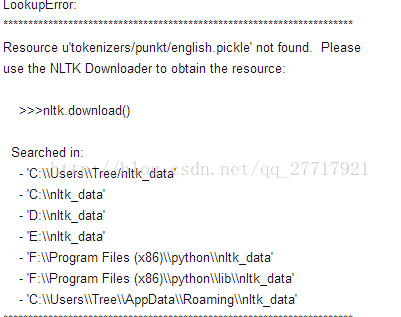
则是需要安装punkt,这个模块主要负责的是分词功能。同stopwords一样有两种方式安装。
同理当报出
LookupError
Resource ***/maxent_treebank_pos_tagger/
*********************************
对应下载maxent_treebank_pos_tagger就可以,这一部分主要就负责词性标注。
去除停用词,分词以及词性标注的调用方法
from nltk.corpus import stopwords
import nltk
disease_List = nltk.word_tokenize(text)
#去除停用词
filtered = [w for w in disease_List if(w not in stopwords.words('english')]
#进行词性分析,去掉动词、助词等
Rfiltered =nltk.pos_tag(filtered)
Rfiltered以列表的形式进行返回,列表元素以(词,词性)元组的形式存在
最后
以上就是傲娇金毛最近收集整理的关于NLTK在去停用词、分词、分句以及词性标注的使用的全部内容,更多相关NLTK在去停用词、分词、分句以及词性标注内容请搜索靠谱客的其他文章。








发表评论 取消回复