文章目录
- 1、分词
- 2、停用词和N-gram
- 停用词
- N-gram
- 3、 更多任务(词性标注、依赖分析、NER、关键词抽取)
- 词性标注
- 句法依存分析
- 命名实体识别
- 关键词抽取
- 4、 jieba工具库使用
- (1)基本分词函数与用法
- (2)词性标注
- (3)关键词抽取
- 基于TF-IDF算法的关键词抽取
- 基于TextRank算法的关键词抽取
- PageRank的基本思想
- TextRank的基本思想
- TextRank提取关键词的主要步骤
- TextRank实际应用
1、分词
对于中文和日文这样的特殊亚洲语系文本而言,字和字之间是紧密相连的,单纯从文本形态上无法区分具备独立含义的次(拉丁语系纯天然由空格分割不同的word),而不同的词以不同的方式排布,可以表达不同的内容和情感,因此在很多中文任务中,我们需要做的第一个处理就是“分词”。
目前主流的分词方法主要是基于词典匹配的分配方式(正向量大匹配法、逆向量大匹配法和双向匹配分词法)和基于统计的分词方法(HMM、CRF、和深度学习);主流的分词工具包括:中科院计算所NLPIR、哈工大LTP、清华大学THULAC、hanlp分词器、python jieba工具库等。


2、停用词和N-gram
停用词
在自然语言处理的很多任务中,文本中有一些功能性词汇经常出现,然而对于最后的任务目标来说并没有帮助,甚至会对统计方法带来一些干扰,我们把这类词叫做停用此,通常我们会用一个停用词表把它们过滤出来。比如英语中的定冠词和不定冠词(a、an、the)等
中文当中常用的停用词词表参见:
https://github.com/goto456/stopwords
关于机器学习中停用词的产出与收集方法,可以参见知乎讨论:机器学习中如何收集停用词
https://www.zhihu.com/question/34939177
N-gram
N-gram在中文中叫做n元语法,指文本中连续出现n个词语,n元语法模型是基于(n-1)阶马尔可夫链的一种概率语言模型,通过n个语词出现的概率来推断语句的结构。
3、 更多任务(词性标注、依赖分析、NER、关键词抽取)
词性标注
https://www.ngui.cc/el/1856417.html?action=onClick
词性(part-of-speech)是词汇基本的语法属性,通常也称为词性。
词性标注,又称为词类标注或简称标注,是指分词结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词或者是其他词性的过程
词性标注是多NLP任务的预处理步骤,如句法分析,经过词性标注后的文本会带来很大的便利性,但也不是不可或缺的步骤。
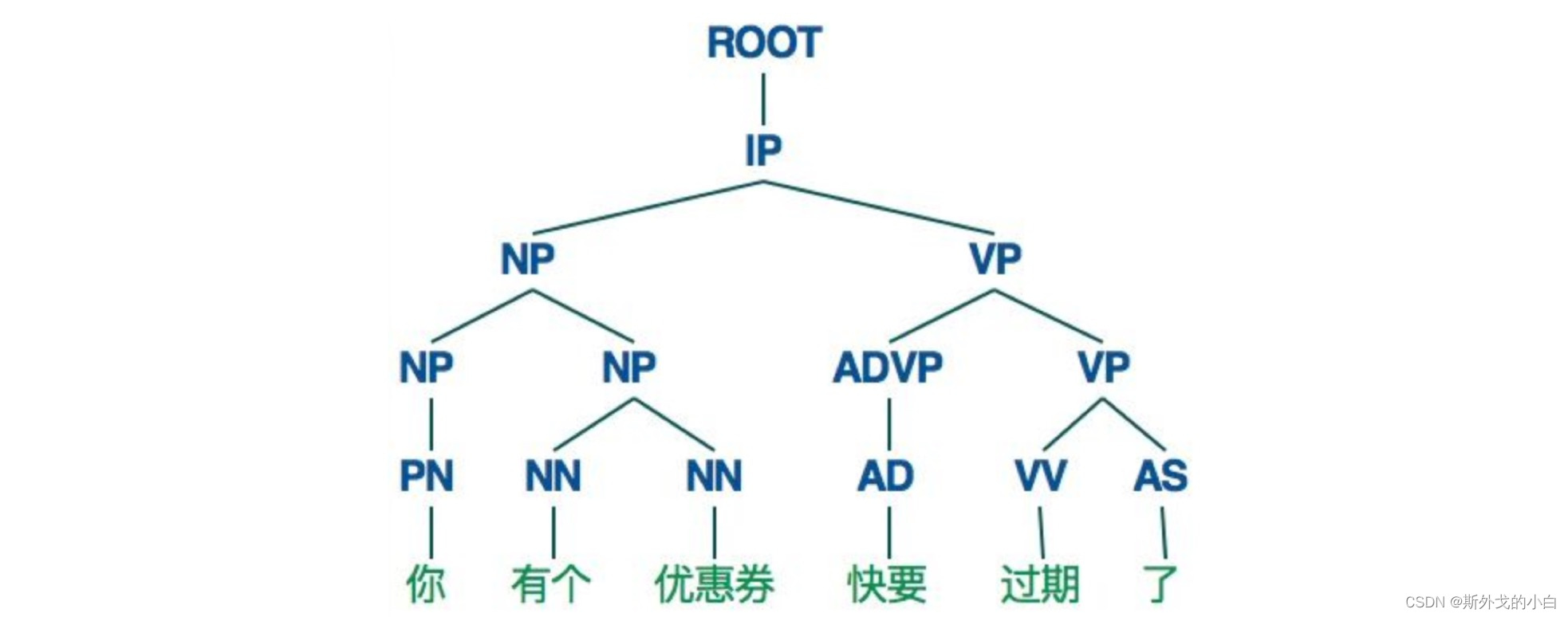
句法依存分析
在很多复杂nlp问题中,我们还需要完成句法分析的任务,更具体一点说,需要确定橛子的句法结构,确定句子中各词之间的依存关系。
命名实体识别
从一段非结构化文本中找出相关实体,并标注其位置以及类型,是nlp领域中的一些复杂任务的基础(比如关系抽取、信息检索、知识问答、知识图谱等)的基础。
关键词抽取
对文本信息进行高度凝练的一种有效手段,通过3-5个词语准确概述文本的主题,帮助读者快速理解文本信息,是文本检索、文本摘要等许多下游文本挖掘任务的基础性和必要性工作。
4、 jieba工具库使用
(1)基本分词函数与用法
jieba.cut 以及jieba.cut_for_search返回的结构都是一个可迭代的generator,可以使用for循环获得分词后得到的每一个词语
jieba.cut方法接受三个输入参数:
a. 需要分词的字符串;
b. cut_all参数用来控制是否采用全模式;
c. HMM参数用来控制是否使用HMM模式
jieba.cut_for_search方法接受两个参数:
a. 需要分词的字符串;
b. HMM(马尔可夫)参数用来控制是否使用HMM模式
全模式方法适合用于搜索引擎构建倒排序索引的分词,粒度比较细
import jieba
seg_list = jieba.cut("我在网易云课堂科学自然语言处理", cut_all=True)
print("Full model:" + "/".join(seg_list))
#Full model:我/在/网易/云/课堂/科学/自然/自然语言/语言/处理
#在cut_all模式下,得到的分词粒度较细,自然语言既保持了其原本的单词构成,也能切分成自然和语言两个单词
print(seg_list)
#<generator object Tokenizer.cut at 0x7fd8edab2dd0>
#返回的是一个迭代器
seg_list_1 = jieba.cut("我在网易云课堂科学自然语言处理", cut_all=False)
print("Default model:" + "/".join(seg_list_1))
#Default model:我/在/网易/云/课堂/科学/自然语言/处理
#在默认切分模式下,只返回常用的分词情况
seg_list_2 = jieba.cut("他毕业于北京航空航天大学,在百度深度学习研究所进行研究") #默认是精确模式
print(",".join(seg_list_2))
#他,毕业,于,北京航空航天大学,,,在,百度,深度,学习,研究所,进行,研究
seg_list_3 = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在斯坦福大学深造") #搜索引擎
print(",".join(seg_list_3))
#小明,硕士,毕业,于,中国,科学,学院,科学院,中国科学院,计算,计算所,,,后,在,福大,大学,斯坦福,斯坦福大学,深造
seg_list_4 = jieba.cut_for_search("他毕业于北京航空航天大学,在百度深度学习研究所进行研究")
print(",".join(seg_list_4))
#他,毕业,于,北京,航空,空航,航天,天大,大学,北京航空航天大学,,,在,百度,深度,学习,研究,研究所,进行,研究
出现报错:AttributeError: partially initialized module ‘jieba’ has no attribute ‘cut’ (most likely due to a circular import)
原因:py文件或者模块名以“jieba” 进行命名了。
当我们希望返回的分词不是以迭代器形式呈现,而是返回列表形式,那么就使用lcut和lcut_for_search
print(jieba.lcut("我在网易云课堂科学自然语言处理"))
#['我', '在', '网易', '云', '课堂', '科学', '自然语言', '处理']
print(jieba.lcut_for_search("小明硕士毕业于中国科学院计算所,后在斯坦福大学深造"))
#['小明', '硕士', '毕业', '于', '中国', '科学', '学院', '科学院', '中国科学院', '计算', '计算所', ',', '后', '在', '福大', '大学', '斯坦福', '斯坦福大学', '深造']
添加用户自定义字典
很多时候我们需要针对自己的场景进行分词,有一些领域内的专用词汇出现
可以使用jieba.load_userdict(filename)加载用户字典;
少量词汇可以自己用下面方法手动添加:
·用add_word(word, freq=None, tag=None)和del_word(word)在程序中动态修改词典
·用suggest_freq(segment, tune=True)可调节单个词语的词频,使其能(不能)被分出来
print("/".join(jieba.cut("如果放到旧字典中将出错", HMM=False)))
#如果/放到/旧/字典/中将/出错
jieba.suggest_freq(("中", "将"), True)
print("/".join(jieba.cut("如果放到旧字典中将出错", HMM=False)))
#如果/放到/旧/字典/中/将/出错
(2)词性标注
import jieba.posseg as pseg
words = pseg.cut("我在网易云课堂学习自然语言处理")
for word, flag in words:
print('{}: {}'.format(word, flag))
'''
我: r
在: p
网易: n
云: ns
课堂: n
学习: v
自然语言: l
处理: v
'''
(3)关键词抽取
基于TF-IDF算法的关键词抽取
<1> import jieba. analyse
<2>jieba. analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
其中,sentence为待提取的文本,topK为返回几个TF/IDF权重最大的关键词,默认值是20,withWeight为是否一并返回关键词权重,默认值是False,allowPOS仅包括指定词性的词,默认为空,即不筛选
import jieba.analyse as analyse
lines = open('NBA.txt').read()
print(" ".join(analyse.extract_tags(lines, topK=20, withWeight=False, allowPOS=())))
#韦少 杜兰特 全明星 全明星赛 MVP 威少 正赛 科尔 投篮 勇士 球员 斯布鲁克 更衣柜 NBA 三连庄 张卫平 西部 指导 雷霆 明星队
lines_1 = open('西游记.txt', encoding='gb18030').read()
key_word = analyse.extract_tags(lines_1, topK=20, withWeight=False, allowPOS=())
print(" ".join(key_word))
#行者 八戒 师父 三藏 唐僧 大圣 沙僧 妖精 菩萨 和尚 那怪 那里 长老 呆子 徒弟 怎么 不知 老孙 国王 一个
TF-IDF计算原理:
1、计算TF词频

2、计算IDF逆文档频率

3、计算TF-IDF

可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。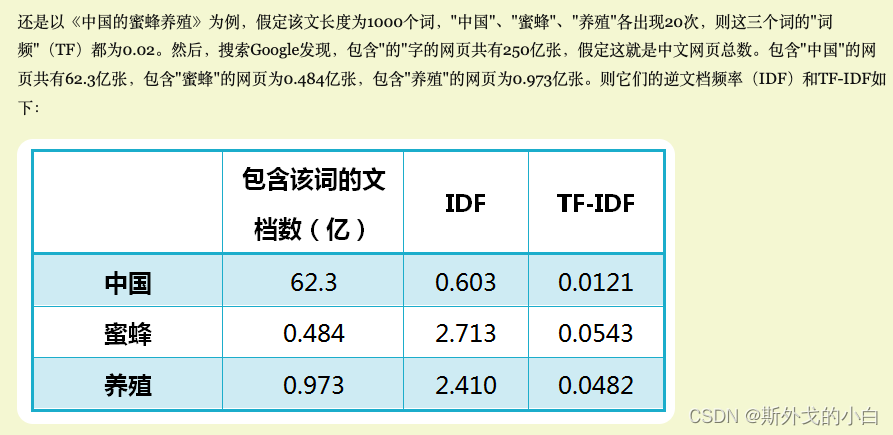
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。
关于TF-IDF 算法的关键词抽取补充
(1)关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
自定义语料库示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/idf.txt.big
(目前这个语料库看不到了)
用法示例见:
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags_idfpath.py [file name] -k [top k]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
content = open(file_name, 'rb').read()
jieba.analyse.set_idf_path("../extra_dict/idf.txt.big");
tags = jieba.analyse.extract_tags(content, topK=topK)
print(",".join(tags))
(2)关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
自定义语料库:https://github.com/fxsjy/jieba/blob/master/extra_dict/stop_words.txt
用法示例:
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags_stop_words.py [file name] -k [top k]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
content = open(file_name, 'rb').read()
jieba.analyse.set_stop_words("../extra_dict/stop_words.txt")
jieba.analyse.set_idf_path("../extra_dict/idf.txt.big");
tags = jieba.analyse.extract_tags(content, topK=topK)
print(",".join(tags))
(3)关键词一并返回关键词权重值示例
用法示例:
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags_with_weight.py [file name] -k [top k] -w [with weight=1 or 0]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
parser.add_option("-w", dest="withWeight")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
if opt.withWeight is None:
withWeight = False
else:
if int(opt.withWeight) is 1:
withWeight = True
else:
withWeight = False
content = open(file_name, 'rb').read()
tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=withWeight)
if withWeight is True:
for tag in tags:
print("tag: %stt weight: %f" % (tag[0],tag[1]))
else:
print(",".join(tags))
基于TextRank算法的关键词抽取
jieba. analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’,‘n’,‘vn’, ‘v’))直接使用,接口相同,注意默认过滤词性
jieba. analyse.TextRank()新建自定义TextRank实例
TextRank的思想来源于PageRank
PageRank的基本思想
PageRank网页排名、谷歌左侧排名,是一种由搜索引擎根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一。以Google公司创办人拉里.佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。
其有两个基本假设:
1、数量假设:如果越多的网页指向A,即A的入链数量越多,则该网页越重要;
2、质量假设:如果指向A的网页质量越高,则A越重要,即权重因素不同。
图1表示一个有向图,假设是简化的互联网例,结点 A 、B、C和 D 表示网页,结点之间的有向边表示网页之间的超链接,边上的权值表示网页之间随机跳转的概率。假设有一个浏览者,在网上随机游走。如果浏览者在网页 A ,则下一步以 1/3 的概率转移到网页 B 、C 和 D。如果浏览者在网页 B,则下一步以 1/2 的概率转移到网页 A和 D。如果浏览者在网页 C ,则下一步以概率 1 转移到网页 A 。如果浏览者在网页 D ,则下一步以 1/2 的概率转移到网页B和 C。
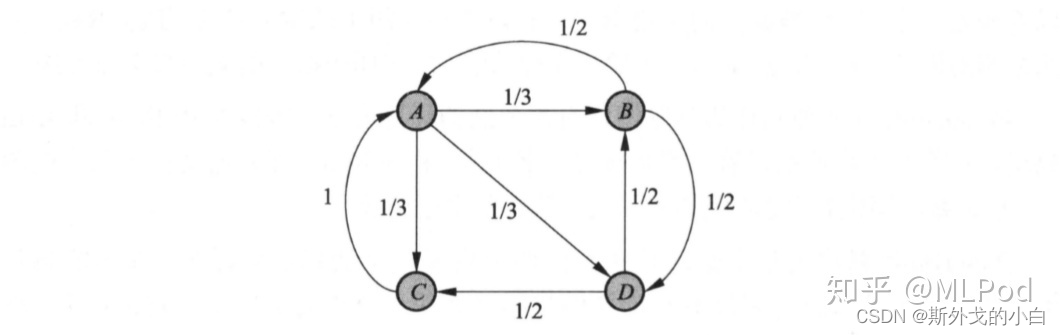
直观上,一个网页,如果指向该网页的超链接越多,随机跳转到该网页的概率也就越高,该网页的PageRank值就越高,这个网页也就越重要。一个网页,如果指向该网页的PageRank值越高,随机跳转到该网页的概率也就越高,该网页的PageRank值就越高,这个网页也就越重要。PageRank值依赖于网络的拓扑结构,一旦网络的拓扑(连接关系)确定,PageRank值就确定。
TextRank的基本思想
进行关键词提取时,TextRank算法思想和PageRank算法类似,不同的是,TextRank中时以词为节点,以共现关系建立起节点之间的链接,需要强调的是,PageRank中是有向边,而TextRank中是无向边,或者说是双向边。
什么是共现关系呢?将文本进行分词,去除停用词或词性筛选等之后,设定窗口长度为K,即最多只能出现K个词,进行窗口滑动,在窗口中共同出现的词之间即可建立起无向边。
TextRank提取关键词的主要步骤
(1)把给定的文本T按照完整句子进行分割;
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词等。这些词形成候选关键词;
(3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现;
(4)根据PageRank原理中的衡量重要性的公式,初始化各节点的权重,然后迭代计算各节点的权重,直至收敛;
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词;
(6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
TextRank实际应用
import jieba.analyse as analyse
lines = open('NBA.txt').read()
key_words = analyse.textrank(lines, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
print(' '.join(key_words))
#全明星赛 勇士 正赛 指导 对方 投篮 球员 没有 出现 时间 威少 认为 看来 结果 相隔 助攻 现场 三连庄 介绍 嘉宾
key_words_1 = analyse.textrank(lines, topK=20, withWeight=False, allowPOS=('ns', 'n'))
print(' '.join(key_words_1))
#勇士 正赛 全明星赛 指导 投篮 玩命 时间 对方 现场 结果 球员 嘉宾 时候 全队 主持人 照片 全程 目标 快船队 肥皂剧
最后
以上就是可爱薯片最近收集整理的关于NLP_learning 中文基本任务与处理(分词、停用词、词性标注、语句依存分析、关键词抽取、命名实体识别)介绍、jieba工具库1、分词2、停用词和N-gram3、 更多任务(词性标注、依赖分析、NER、关键词抽取)4、 jieba工具库使用的全部内容,更多相关NLP_learning内容请搜索靠谱客的其他文章。








发表评论 取消回复