在实际工作中,更多的情况是通过Python读取外部数据集,这些数据集可能包含在本地的本文文件(如csv、txt等)、电子表格Excel和数据库中(如MySQL、SQL Server等)。现在学习是如何基于pandas模块实现文本文件、电子表格和数据库数据的读取。
文本文件的读取
要读取txt和csv格式中的数据 ,可以使用pandas模块中的read_table函数或read_csv函数。而并不是说每个函数只能读取一种格式的数据,而是这两种函数均可以文本文件的数据。由于两种函数功能和参数使用上类似,因此这里仅以read_table函数为例:
pd.read_table(filepath_or_buffer,sep='t',header='infer',
names=None,index_col=None,usecols=None,dtype=None,converters=None,
skiprows=None,skipfooter=None,nrows=None,na_values=None,
skip_blank_lines=True,parse_dates=False,thousands=None,
comment=None,encoding=None)
filepath_or_buffer:指定文件的具体路径
sep:指定原数据集中各字段之间的分隔符,默认为tab制表符
header:默认将第一行用作字段名称
names:如果原数据没有字段可以通过该参数在数据读取时给数据框添加具体的表头
index_col:指定原数据集的某些列作为数据框的行索引
usecols:指定读取原数据集的哪些变量名
dtype:读取数据集时,可以为原数据集的每个字段设置不同的数据类型
converters:通过字典格式,为数据集中的某些字段设置转换函数
skiprows:数据读取时,指定需要跳过原数据集开头的行数
skipfooter:数据读取时,指定需要跳过原数据集末尾的行数
nrows:指定读取数据集的行数
na_values:指定原数据集中哪些哪些特征的值作为缺失值
skip_blank_lines:读取数据时是否需要跳过原数据集中的空白行,默认为true
parse_dates:如果参数值为true,则尝试解析数据框的行索引,如果参数为列表,则尝试解析对应的日期列,如果参数为嵌套列表,则将某些列合并为日期列,如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)。
thousands:指定原始数据集中的千分位符
comment:指定注释符,在读取数据时,如果碰到行首指定的注释符,则跳过该行
encoding:如果文件中含有中文,有时需要指定字符编码
数据集如下图所示:
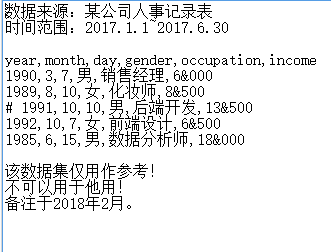
# 读取文本文件中的数据
user_income = pd.read_table(r'd:data_test01.txt', sep = ',',
parse_dates={'birthday':[0,1,2]},skiprows=2, skipfooter=3,
comment='#', encoding='utf8', thousands='&')
user_income
电子表格的读取
pd.read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0,
index_col=None, names=None, parse_cols=None, parse_dates=False,
na_values=None, thousands=None, convert_float=True)
io:指定电子表格的具体路径
sheetname:指定需要读取电子表格中的第几个Sheet,既可以传递整数也可以传递具体的Sheet名称
header:是否需要将数据集的第一行用作表头,默认为是需要的
skiprows:读取数据时,指定跳过的开始行数
skip_footer:读取数据时,指定跳过的末尾行数
index_col:指定哪些列用作数据框的行索引(标签)
names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头
parse_cols:指定需要解析的字段
parse_dates:如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)
na_values:指定原始数据中哪些特殊值代表了缺失值
thousands:指定原始数据集中的千分位符
convert_float:默认将所有的数值型字段转换为浮点型字段
converters:通过字典的形式,指定某些列需要转换的形式
child_cloth = pd.read_excel(io = r'd:data_test02.xlsx', header = None,
names = ['Prod_Id','Prod_Name','Prod_Color','Prod_Price'], converters = {0:str})
child_cloth
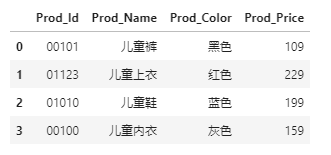
这里需要重点说明的是converters参数,通过该参数可以指定某些变量需要转换的函数。很显然,原始数据集中的商品ID是字符型的,如果不将该参数设置为{0:str},读入的数据与原始数据集就不一致。
数据库数据的读取
数据库可以存放海量数据也可以便捷的实现数据的查询。以MySQL和SQL server为例,使用pandas模块和对应的数据库模块(分别是pymysql模块和pymssql模块,如果还没有安装这两个模块,需要通过cmd命令输入pip install pymysql和pip install pymssql)实现数据的链接与读取。
首先介绍pymysql模块和pymssql模块中的连接函数connect,虽然两个模块中的连接函数名称一致,但函数中参数并不完全相同,所以需要分别学习。
pymysql中的connect
pymysql.connect(host=None, user=None, password=‘’,
database=None, port=0, charset=‘’)
host:指定需要访问的MySQL服务器
user:指定访问MySQL数据库的用户名
password:指定访问MySQL数据库的密码
database:指定访问MySQL数据库的具体库名
port:指定访问MySQL数据库的端口号
charset:指定读取MySQL数据库的字符集,如果数据库表中含有中文,一般可以尝试将该参数设置为“utf8”或“gbk”
pymssql中connect
pymssql.connect(server = None, user = None, password = None,
database = None, charset = None)
server:指定需要访问的MySQL服务器
user:指定访问MySQL数据库的用户名
password:指定访问MySQL数据库的密码
database:指定访问MySQL数据库的具体库名
charset:指定读取MySQL数据库的字符集,如果数据库表中含有中文,一般可以尝试将该参数设置为“utf8”或“gbk”
# 导入模块
import pymysql
# 连接MySQL数据库
conn = pymysql.connect(host='localhost', user='root', password='1q2w3e4r',
database='test', port=3306, charset='utf8')
# 读取数据
user = pd.read_sql('select * from topy', conn)
# 关闭连接
conn.close()
# 数据输出
user
由于mysql的原数据集中含有中文,为了避免乱码的现象,将connect函数中的chartset参数设置为utf8。读取数据时,需要用到pandas模块中的read_sql函数,该函数至少传入两个参数,一个是读取数据的查询语句(sql),另一个是连接桥梁(con);在读取完数据之后,请务必关闭连接conn,因为它会一直占用计算机的资源,影响计算机的运行效率。
# 导入第三方模块
import pymssql
# 连接SQL Server数据库
connect = pymssql.connect(server = 'localhost', user = '', password = '',
database = 'train', charset = 'utf8')
# 读取数据
data = pd.read_sql("select * from sec_buildings where direction = '朝南'", con=connect)
# 关闭连接
connect.close()
# 数据输出
data.head()
访问SQLserver不需要填写用户名和密码,因此user参数和password参数需要设置为空字符;在读取数据时,可以写入更加灵活的SQL代码,数据代入会 ,仍然需要关闭连接。
最后
以上就是舒服汉堡最近收集整理的关于Python外部数据的读取的全部内容,更多相关Python外部数据内容请搜索靠谱客的其他文章。


![读取外部输入的方式Python3 中 sys.argv[ ]的用法解释](https://www.shuijiaxian.com/files_image/reation/bcimg3.png)





发表评论 取消回复