#sklearn 朴素贝叶斯NB算法常用于文本分类,尤其是对于英文等语言来说,分类效果很好;它常用于垃圾文本过滤、情感预测、推荐系统等;是基于概率进行预测的模型,可以做二分类及多分类( 朴素贝叶斯是个不建模的算法,不建模的还有KNN,KMeans,PCA):
目的:预测文本的类别;
工具:语言python;数据分析:pandas,matplotlib,numpy三剑客;数据预测:sklearn;
操作流程:查找并分析数据,sklearn NB机器学习算法进行文本类别预测。
1.数据收集:
sklearn :from sklearn.datasets import fetch_20newsgroups 模块下面有很多数据集供我们测试使用,我们可以引用里面的20类新闻文本数据集,3万篇的数据,来验证我们的算法:
实例化:(加载失败看这里)
加载20篇文章:
news = fetch_20newsgroups(subset=“all”)
2.文章识别,需要先进行特征提取,抽取主要的作用就是抽取出关键词,根据关键词的类别,进行文章类别的确认(里面的程序帮助我们认识文本特征抽取的概念):
特征提取主要针对文本及字典的数据,提出出数据的重要性,方便后面的识别及预测:
a.特征抽取:
# coding=gb2312 #加入编码格式
#导入包:特征抽取
from sklearn.feature_extraction.text import CountVectorizer
#1.文本特征抽取:
#实例化:
vector = CountVectorizer()
#调用fit_transform并转换数据
res = vector.fit_transform(["Life is short,i like python","Life is too long,i dislike python"])
#打印结果:
print(vector.get_feature_names()) #打印筛选出的特征值
print(res)
print(res.toarray()) #将结果转换为数组的样式
#2.============jiba,文本特征抽取===================================
import jieba
c1 = jieba.cut("韩正将与新加坡副总理王瑞杰共同主持召开中新双边合作机制会议")
c2 = jieba.cut("“年味儿”是种很奇妙的氛围,不管这一年有多少收获或是遗憾,只要到了这个特殊的节点,我们就会不由自主地,喜气洋洋地,把年货置办得丰富一些,热闹一些,以告慰这一年的得与失。")
c3 = jieba.cut("记者从国家航天局获悉,12月8日6时59分,嫦娥五号上升器按照地面指令受控离轨,7时30分左右降落在月面经度0度、南纬30度附近的预定落点。")
content1 = list(c1)
content2 = list(c2)
content3 = list(c3)
c1 = " ".join(content1)
c2 = " ".join(content2)
c3 = " ".join(content3)
# print(c1,c2,c3,"n",content1,content2,content3)
cv = CountVectorizer()
data = cv.fit_transform([c1,c2,c3])
print(cv.get_feature_names())
print(data.toarray())
#3.查看一个词对于一个文本的重要性:文本特征抽取(相当于概率,朴素贝叶斯预测前可用)
#主要就是使用这个:
from sklearn.feature_extraction.text import TfidfVectorizer
tf = TfidfVectorizer()
# idf = tf.fit_transform(["Life is short,i like python","Life is too long,i dislike python"])
idf = tf.fit_transform([c1,c2,c3]) #第三个里面的文本
print(tf.get_feature_names()) #返回单词列表
print(idf.toarray()) #返回词的权重矩阵
#4.字典特征抽取:
from sklearn.feature_extraction import DictVectorizer
'''
字典数据抽取:
:return:None
'''
#实例化:
dict = DictVectorizer()
data = [{"city":"北京","temperate":100},{"city":"上海","temperate":60},{"city":"深圳","temperate":30}]
result = dict.fit_transform(data)
print(dict.get_feature_names())
print(result.toarray())
#resurt的数据类型是sparse矩阵,为的是节约内存,方便读取处理
#ndarray 二维数组
3.朴素贝叶斯算法简介:
a.算法概念:朴素贝叶斯(NB)属于生成式模型(即需要计算特征与类的联合概率分布),计算过程非常简单,只是做了一堆计数。NB有一个条件独立性假设,即在类已知的条件下,各个特征之间的分布是独立的。
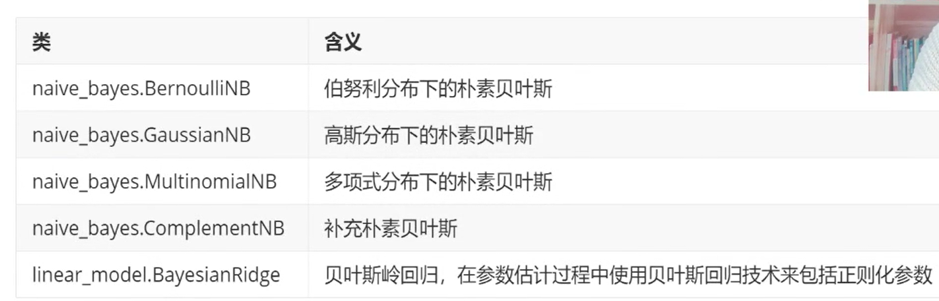
b.算法思路:NB思路
贝叶斯公式可以表示成下面的样子,其中特征是有多个的(不理解可以进入链接看一下),P(类别|特征)就是我们预测的值:
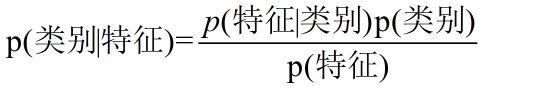
等号右边的概率都是可计算的,因此可以根据特征预测出文章的类别:
'''
1.朴素贝叶斯的原理:假设特征间相互独立,我们就可以根据概率进行分类;
联合概率:P(X=x,Y=y) 条件概率:P(Y=y|X=x)
贝叶斯等式:P(Y=y|X=x) = P(X=x|Y=y)*P(Y=y)/P(X=x) 大X可以有多个特征;
对于二分类为例:我们可以表示成为全概率公式:P(X=x) = P(Y=1)*P(X=x|Y=1)+P(Y=0)*P(X=x|Y=0)
P(Y=1|X=x) = P(Y=1)*P(X=x|Y=1)/P(X=x)
P(Y=0|X=x) = P(Y=0)*P(X=x|Y=0)/P(X=x)
P(Y=1|X=x)+P(Y=0|X=x)=1 求出:P(X=x)
求出概率后,我们结果跟大概率的一致:
分类的时候可以选择P(Y=1|X=x),P(Y=0|X=x)较大的一个作为分类的取值;分母一致,可以只考虑分子;
2.处理连续型变量(特征):
注:对于概率密度函数f(x),负无穷-正无穷积分是1;
P(xi<x<xi+a)= ∫(xi-xi+a)f(x)dx = f(xi)*a ,a在后验概率计算过程中会消掉;所以就可以将连续型变量转化为xi某个点取值的概率问题;
f(x)可以主观认为符合高斯分布,伯努利分布,多项式分布;
因此:我们可以将连续型变量下某个点概率问题,转化为f(x)在xi上的取值问题;
'''
实例定量的看一下朴素贝叶斯的原理:
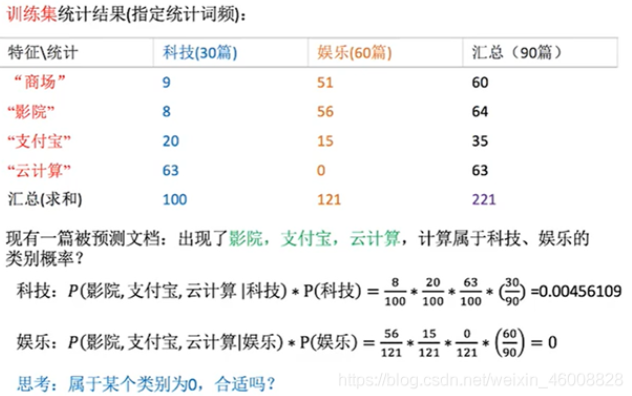
拉普拉斯平滑:
属于娱乐的概率是0,显然是不太好的,所以出现了拉普拉斯平滑系数,就是加上个系数,不让他的值是0:拉普拉斯平滑(模块内部函数已经给定了,可以修改,但是没必要,了解即可)

c.优缺点:
优点:稳定的分类效率。 对小规模的数据表现良好;能处理多分类任务,适合增量式训练;对缺失数据不太敏感,算法也比较简单,常用于文本分类(如垃圾邮件过滤)
缺点:需要计算先验概率;分类决策存在错误率;对输入数据的表达形式很敏感;它的主要缺点是它不能学习特征间的相互作用,用mRMR中的R来讲,就是特征冗余。
d.代码实例(文本类别预测):
# coding=gb2312 #加入编码格式
from sklearn.naive_bayes import MultinomialNB,ComplementNB,BernoulliNB
from sklearn.metrics import brier_score_loss as BS
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import classification_report
import numpy as np
'''
朴素贝叶斯:预测文章所属的类别;
'''
#1.加载20篇文章并进行分割
'''
参数简介:subset选择类中包含的数据子集;train表示训练集,test表示测试集;all表示加载所有数据。
categories可输入None,或者数据所在的标签;不想加载全部数据可以输入参数;
download_if_missing发现本地数据不全,是否自动下载;True/False.
shuffle是否打乱样本数据:True/False
'''
categories = ["sci.space" #科学技术-太空
,"rec.sport.hockey"#运动-曲棍球
# ,"talk.politics.guns"#政治-枪支问题
# ,"talk.politics.mideast"#政治-中东问题
]
train = fetch_20newsgroups(subset="train",categories=categories)
test = fetch_20newsgroups(subset="test",categories=categories)
#查看是否存在样本不均衡问题:
for i in [0,1,2,3]:
print(i,(train.target == i).sum()/len(train.target))
print(train.target_names)
#进行数据分割:
x_train = train.data
x_test = test.data
y_train = train.target
y_test = test.target
#2.生成文章的特征词:重要程度抽取
tf = TfidfVectorizer()
x_train_ = tf.fit_transform(x_train)
x_test_ = tf.transform(x_test)
# print(tf.get_feature_names())
#3.朴素贝叶斯estimator流程进行预估:
name = ["MultinomialNB","ComplementNB","BernoulliNB"]
#高斯朴素贝叶斯不接受稀疏矩阵:
models = [MultinomialNB(),ComplementNB(),BernoulliNB()]
for name,clf in zip(name,models):
clf.fit(x_train_,y_train)
# #模型预测:
y_pred = clf.predict(x_test_)
proba = clf.predict_proba(x_test_)
score = clf.score(x_test_,y_test)
# #准确率和召回率:
# print("每个类别的准确率和召回率:",classification_report(y_test,y_pred))
print(name)
#四个不同标签的取值下的布里尔分数:
Bscore = []
for i in range(len(np.unique(y_train))):
bs = BS(y_test,proba[:,i],pos_label=i)
Bscore.append(bs)
print("tBrier under {}:{:.3f}".format(train.target_names[i],bs))
print("tAverage Brier:{:.3f}".format(np.mean(Bscore)))
print("tAccuracy:{:.3f}".format(score))
print("n")
#布里尔分数只能计算二分类了,刚刚调试半天,最后根据提示,注释掉两个分类后就好了:
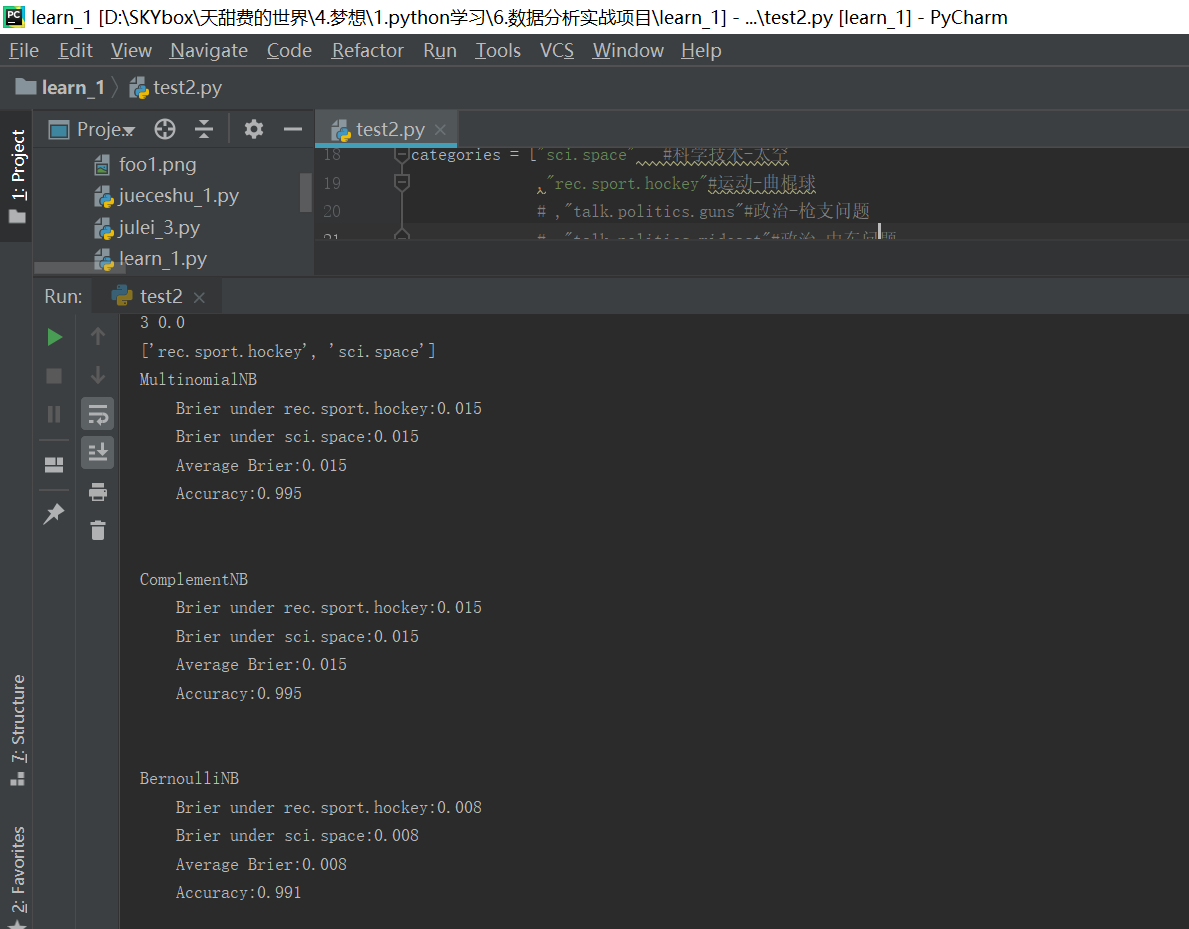
以上就完成了一个文本分类的预测,有新的知识再补充吧,布里尔分数用不了可以用其他的评判方式。
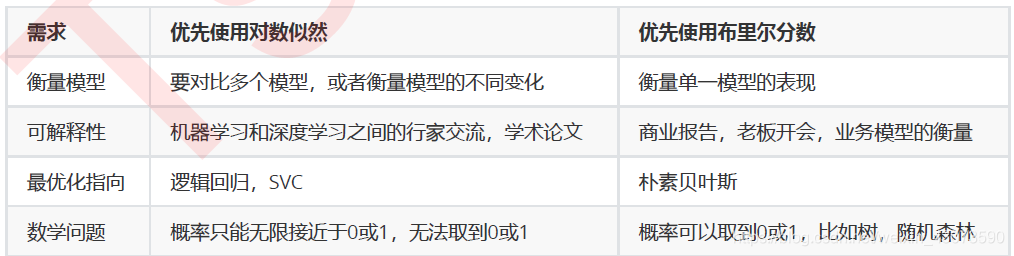
4.朴素贝叶斯模型的评判方式:这个讲解还是清楚的
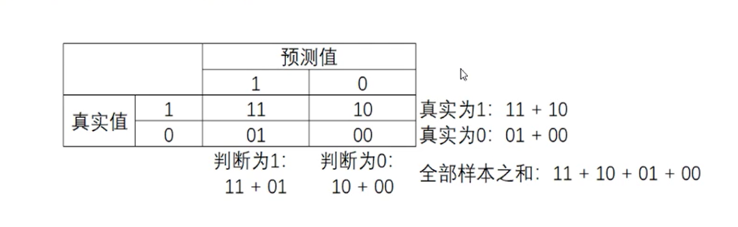
a.混淆矩阵(二分类可以用ROC曲线来看一下:横坐标假正率,纵坐标召回率):
可以看下视频感受一下:混淆矩阵指标

b.布里尔分数(范围0-1;越靠近0越好):


c.对数似然函数(是损失函数,所以数值越小,模型越好):
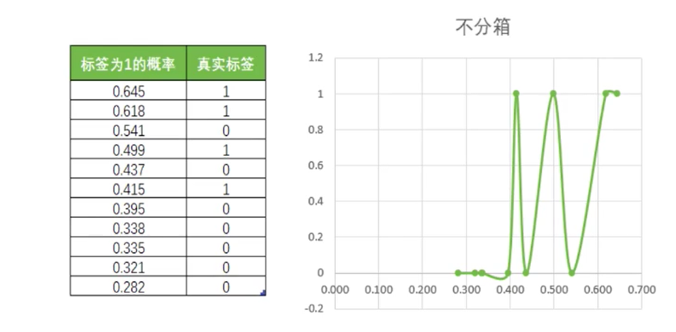
d.可靠性曲线(横坐标预测概率,纵坐标真实标签,越靠近对角线越好):
数据未分箱,看着很杂乱:
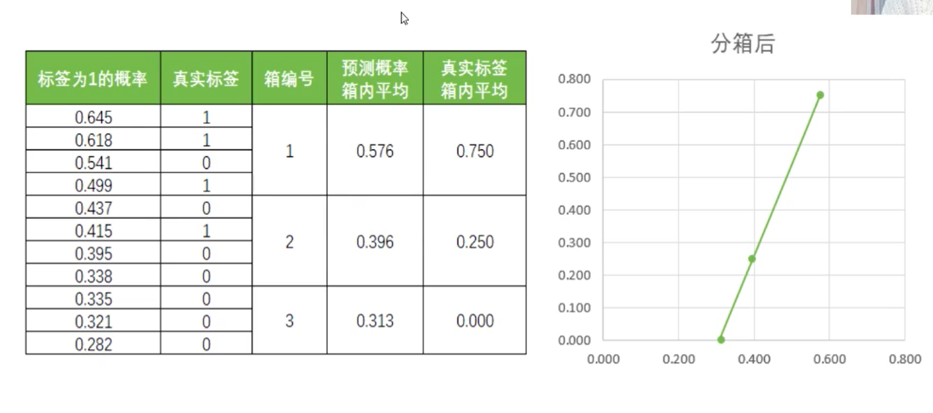
树分箱之后,好多了:
e.预测概率直方图:
我们可以通过绘制直方图来查看模型的预测概率的分布。直方图是以样本的预测概率分箱后的结果为横坐标,每个箱中的样本数量为纵坐标的一个图像。
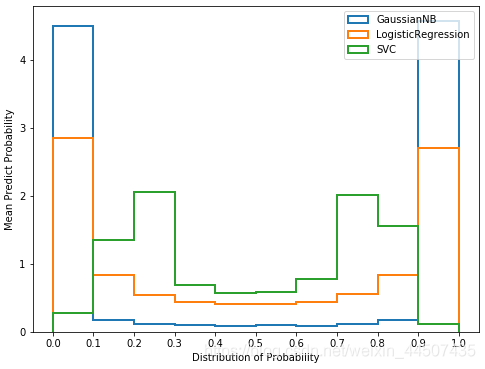
f.校准可靠性曲线:
等近似回归有两种回归可以使用,一种是基于Platt的Sigmoid模型的参数校准方法,一种是基于等渗回归(isotonic calibration)的非参数的校准方法。概率校准应该发生在测试集上,必须是模型未曾见过的数据。在数学上,使用这两种方式来对概率进行校准的原理十分复杂,而此过程我们在sklearn中无法进行干涉,大家不必过于去深究。
以上就是对朴素贝叶斯的一个简单介绍,前路漫漫,不忘初心。
持续更新,,,,,,
最后
以上就是谨慎过客最近收集整理的关于#第26篇分享:一个文本分类的数据挖掘(python语言:sklearn 朴素贝叶斯NB)(2)的全部内容,更多相关#第26篇分享:一个文本分类的数据挖掘(python语言:sklearn内容请搜索靠谱客的其他文章。








发表评论 取消回复