一. 摘要
本次内容将分享文本向量化的一些方法。文本向量化的方法有很多,主要可分为以下两个大类:基于统计的方法、基于神经网络的方法。在自然语言处理的领域中,文本向量化是文本表示的一种重要方式。文本向量化的主要目的是将文本表示成一系列能够表达文本语义的向量。无论是中文还是英文,词语都是表达文本处理的最基本单元。当前阶段,对文本向量化大部分的研究都是通过词向量化实现的。
二. 向量化算法word2vec
词袋(Bag of Word)模型是最早的以语言为基本处理单元的文本向量化方法。下面我们将通过示例展示该方法的原理。
例子:句子1:“我喜欢坐高铁回家”。;句子2:“中国高铁非常快”。
句子1分词:“我、喜欢、坐、高铁、回家”;
句子2分词:“中国、高铁、非常、块”。
根据上述两句出现的词语,构建一个字典:{“我”:1,“喜欢”:2,“坐”:3,“高铁”:4,“回家”:5,“中国”:6,“非常”:7,“快”:8}
该字典中包含8个词,每个词都有唯一索引,并且它们出现的顺序是没有关联的,根据这个字典,我们将上述两句重新表达为两个向量:
[1,1,1,1,1,0,0,0]
[0,0,0,1,0,1,1,1]
这两个向量共包含8个元素,其中第i个元素表示字典中第i个词语在句子中出现的次数,因此BOW模型认为是一种统计直方图。在文本检索和处理中,可以通过该模型很方便的计算词频。该方法虽然简单,但却存在着三个大问题:
维度灾难:很明显,如果上述的字典中包含了9999个词语,那么每一个文本都需要用9999维的向量才能表示,如此高维度的向量很需要很大的计算力。
无法利用词语的顺序信息。
存在语义鸿沟的问题。
互联网的高速发展,随之产生的是大量无标注的数据,所以目前的主要方向是利用无标注数据挖掘出有价值的信息。词向量(word2vec)技术就是利用神经网络从大量的无标注文本中提取有用的信息。
可以说词语是表达语义的基本单元。因为词袋模型只是将词语符号化,所以在词袋模型中是无法包含任何语义信息的。所以如何通过“词表示”包含语义信息是该领域的主要门槛。目前有分布假说的提出,为解决上述问题提供了理论基础。该假说的主要思想是:上下文相似的词,其包含的语义也相似。利用上下文分布表示语义的方法就是词空间模型
三. 神经网络语言模型
神经网络模型逐渐在各个领域中得到蓬勃发展,使用神经网络构造词表示的最大优点是可以灵活的对上下文进行建模。神经网络词向量模型就是根据上下文与目标词之间的关系进行建模。
本次主要介绍一下神经网络语言模型(Neural Network Language Model,NNLM),可求解二元语言模型。NNLM模型直接通过一个神经网络结构对n元条件概率进行估计。NNLM模型的基本结构如下图1中所示:
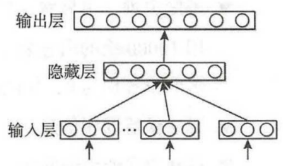
图1:NNLM模型结构
对于图1中的流程大致可描述为:首先从语料库中搜集一系列长度为n的文本序列Wi-(n-1),...,Wi-1,Wi,并且假设这些长度为n的文本序列组成的集合为D,那么此时的NNLM目标函数可表示为:
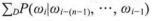
对于上述的表达式可以理解为:在输入词序列为Wi-(n-1),...,Wi-1的情况下,计算目标词Wi的概率。
在图1所示的神经网络语言模型是非常经典的三层前馈神经网络结构,其中包括三层:输入层、隐藏层和输出层。这里为了解决词袋模型数据稀疏的问题,输入层的输入为低维度的、紧密的词向量,输入层的操作就是将词序列Wi-(n-1),...,Wi-1中的每个词向量按顺序拼接。可表示为:
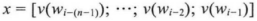
在输入层得到了经过计算的x之后,将x输入隐藏层得到h,再将h接入输出层就可以得到输出变量y,隐藏层变量h和输出变量y的计算表达式为:
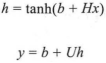
在上面表达式中H为输入层到隐藏层的权重矩阵,其维度为|h|×(n-1)|e|;U为隐藏层到输出层的权重矩阵,其维度为|V|×|h|,|V|表示的是词表的大小;b则是模型中的偏置项。NNLM模型中计算量最大的操作就是从隐藏层到输出层的矩阵运算Uh。输出的变量y则是一个|V|维的向量,该向量的每一分量依次对应下一个词表中某一个词的可能性。用y(w)表示由NNLM模型计算得到的目标词w的输出量,并且为了保证输出y(w)的值为概率值,所以还需要对输出层进行归一化处理。一般的处理方法是在输出层之后加入softmax函数,就可以将y转成对应的概率值,具体表达式如下:
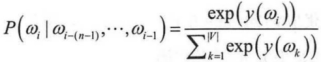
由于NNLM模型使用的是低维紧凑的词向量对上下文进行表示,这很好的解决了词袋模型带来的数据稀疏、语义鸿沟的问题。因此,NNLM模型是一种很好的n元语言模型,并且在另一个方面,在相似的上下文语境中,NNLM模型可以预测出相似的目标词,这是传统的模型所不具备的。例如,在预料中有A=“詹姆斯带领湖人队赢得了总冠军”出现过999次,而B=“浓眉哥带领湖人队赢得了总冠军”只出现了9次。那么如果是根据频率来计算概率的话,P(A)肯定会远远大于P(B)的概率。然而对比看语料A和语料B唯一的区别在于詹姆斯和浓眉哥,这两个词无论是语义和所处的语法位置都是非常相似的,所以P(A)远大于P(B)就是不合理的。这里如果是采用NNLM模型来计算的话,得到P(A)和P(B)的概率结果应该是大致相当的,主要原因是NNLM模型采用低维的向量表示词语,假定相似度词的词向量也大致相似。
因为输出的y(w)代表上文中出现词序列Wi-(n-1),...,Wi-1的情况下,下一个词wi的概率。那么在语料库D中最大化y(wi)的值,就是NNLM模型的目标函数。
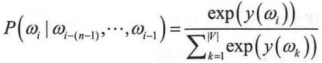
一般可以使用随机梯度下降的优化算法对NNLM模型进行训练。在训练每一个batch时,会随机的从语料库D中抽取若干的样本进行训练,随机梯度下降的数学表达式为:
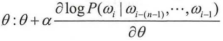
其上述表达式中,α符号表示为学习率参数,Θ符号表示为模型中涉及到的所有参数,包括NNLM模型中的权重、偏置以及输入的词向量。
四. 总结
本次的分享首先举例说明了使用普通词袋模型进行词向量操作的局限性,词向量方法面对的主要难题就是解决维度过高、语义鸿沟等问题。后面便主要接介绍了基于神经网络的词向量模型,通过基础的输入层、隐藏层、输出层的分部分介绍,描述了神经网络词向量模型。
以上是个人的一些见解,理解有限,欢迎大家指正讨论!
最后
以上就是敏感花卷最近收集整理的关于自然语言处理之——文本向量化的全部内容,更多相关自然语言处理之——文本向量化内容请搜索靠谱客的其他文章。








发表评论 取消回复