机器学习系列专栏
选自 Python-Machine-Learning-Book On GitHub
作者:Sebastian Raschka
翻译&整理 By Sam
这篇《教你用Scikit-Learn来做分类器》对于我们入门scikit learn有很好的参考价值,之前分了三篇来分别阐述,相对篇幅会小一点,这篇的话就是把先前的全部内容进行汇总,所以篇幅看起来会相对吓人,大家可以收藏起来慢慢研究,给自己充电哦?!
由于文章篇幅较长,还是先把本文的结构贴在前面,如下:
Scikit-Learn初认识
使用Scikit-Learn训练感知器
使用逻辑回归构建一个概率类的分类模型
逻辑回归的激活函数
逻辑回归的损失函数
使用sklearn训练一个逻辑回归模型
使用正则化处理过拟合
使用Kernel-SVM来解决非线性问题
什么是非线性问题
核方法函数及原理
利用核技巧Kernel-SVM在高维空间中寻找分隔超平面
机器学习决策树模型
最大化信息增益-获得最大的提升度
建立决策树
通过随机森林将“弱者”与“强者”模型集成
K近邻分类模型(一个懒惰的算法)
参考文献
PS:代码已单独保存:可在公众号后台输入“sklearn”进行获取ipynb文件
Scikit-Learn初认识
关于Scikit的介绍,大家应该看过很多了,简答来说它就是用Python开发的机器学习库,其中包含大量机器学习算法、数据集,是数据挖掘方便的工具,更多的介绍这里就不说了,大家有兴趣可以去百度一下呗。
我们直接从scikit-learn里加载iris数据集。在这里,第三列表示花瓣长度,第四列表示花瓣宽度。这些类已经转换为整数标签,其中0=Iris-Setosa, 1=Iris-Versicolor, 2=Iris-Virginica。
使用Scikit-Learn训练感知器
导入数据集:
1# 导入sklearn里面的iris数据集,并且获取特征和目标列
2from sklearn import datasets
3import numpy as np
4iris = datasets.load_iris()
5X = iris.data[:, [2, 3]]
6y = iris.target划分数据集:
1# 根据sklearn的版本使用不同的类
2if Version(sklearn_version) < '0.18':
3 from sklearn.cross_validation import train_test_split
4else:
5 from sklearn.model_selection import train_test_split
6X_train, X_test, y_train, y_test = train_test_split(
7 X, y, test_size=0.3, random_state=0)特征标准化:
1from sklearn.preprocessing import StandardScaler
2sc = StandardScaler()
3sc.fit(X_train)
4X_train_std = sc.transform(X_train)
5X_test_std = sc.transform(X_test)
训练模型:
1from sklearn.linear_model import Perceptron
2ppn = Perceptron(n_iter=40, eta0=0.1, random_state=0)
3ppn.fit(X_train_std, y_train)
模型效果:
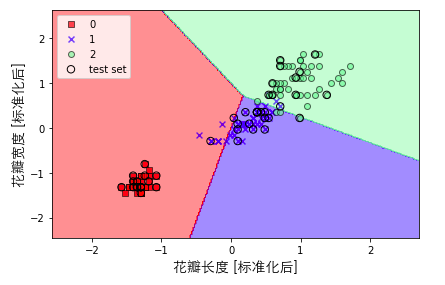
绘制分类情况:
1from matplotlib.colors import ListedColormap
2import matplotlib.pyplot as plt
3import warnings
4def versiontuple(v):
5 return tuple(map(int, (v.split("."))))
6def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
7 # setup marker generator and color map
8 markers = ('s', 'x', 'o', '^', 'v')
9 colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
10 cmap = ListedColormap(colors[:len(np.unique(y))])
11 # plot the decision surface
12 x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
13 x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
14 xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
15 np.arange(x2_min, x2_max, resolution))
16 Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
17 Z = Z.reshape(xx1.shape)
18 plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
19 plt.xlim(xx1.min(), xx1.max())
20 plt.ylim(xx2.min(), xx2.max())
21 for idx, cl in enumerate(np.unique(y)):
22 plt.scatter(x=X[y == cl, 0],
23 y=X[y == cl, 1],
24 alpha=0.6,
25 c=cmap(idx),
26 edgecolor='black',
27 marker=markers[idx],
28 label=cl)
29 # highlight test samples
30 if test_idx:
31 # plot all samples
32 if not versiontuple(np.__version__) >= versiontuple('1.9.0'):
33 X_test, y_test = X[list(test_idx), :], y[list(test_idx)]
34 warnings.warn('Please update to NumPy 1.9.0 or newer')
35 else:
36 X_test, y_test = X[test_idx, :], y[test_idx]
37 plt.scatter(X_test[:, 0],
38 X_test[:, 1],
39 c='',
40 alpha=1.0,
41 edgecolor='black',
42 linewidths=1,
43 marker='o',
44 s=55, label='test set')
再次训练模型并可视化:
1# 为了显示中文(这里是Mac的解决方法,其他的大家可以去百度一下)
2from matplotlib.font_manager import FontProperties
3font = FontProperties(fname='/System/Library/Fonts/STHeiti Light.ttc')
4# vstack:纵向合并,更多具体用法可以百度
5# hstack:横行合并,更多具体用法可以百度
6X_combined_std = np.vstack((X_train_std, X_test_std))
7y_combined = np.hstack((y_train, y_test))
8plot_decision_regions(X=X_combined_std, y=y_combined,
9 classifier=ppn, test_idx=range(105, 150))
10plt.xlabel('花瓣长度 [标准化后]',FontProperties=font,fontsize=14)
11plt.ylabel('花瓣宽度 [标准化后]',FontProperties=font,fontsize=14)
12plt.legend(loc='upper left')
13plt.tight_layout()
14plt.show()
output:
使用逻辑回归构建一个概率类的分类模型
逻辑回归的激活函数
关于激活函数,首先要搞清楚的问题是,激活函数是什么,有什么用?不用激活函数可不可以?答案是不可以。
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
激活函数的性质:
可微性:当优化方法是基于梯度的时候,这个性质是必须的。
单调性:当激活函数是单调的时候,单层网络能够保证是凸函数。
输出值的范围:当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate
Sigmoid 是使用范围最广的一类激活函数,具有指数函数形状,它在物理意义上最为接近生物神经元。此外,(0, 1) 的输出还可以被表示作概率,或用于输入的归一化,代表性的如Sigmoid交叉熵损失函数。(一般会用于二分类问题的激活函数,深度学习大概还有3种激活函数,大家可以去百度一下。)
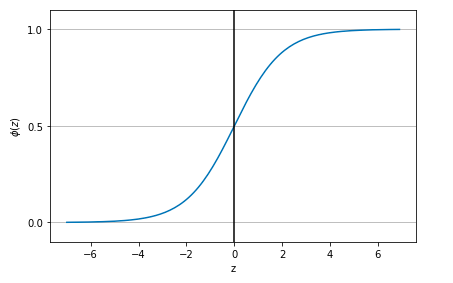
图:sigmoid函数长酱紫
逻辑回归的损失函数
逻辑回归的对数似然损失函数cost function:
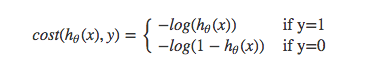

图:详见参考文献[2]
也可以直观地从图里看到损失函数的原理:
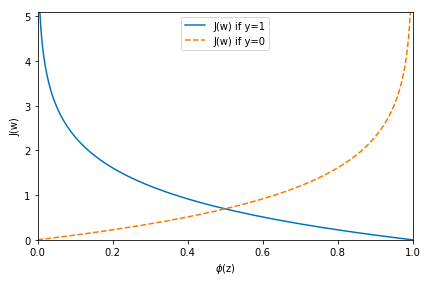
使用sklearn训练一个逻辑回归模型
关于逻辑回归算法,调用的方式和上面的ppn算法是类似,如下:
1from sklearn.linear_model import LogisticRegression
2# 导入逻辑回归算法包
3lr = LogisticRegression(C=1000.0, random_state=0)
4lr.fit(X_train_std, y_train)
5plot_decision_regions(X_combined_std, y_combined,
6 classifier=lr, test_idx=range(105, 150))
7plt.xlabel('花瓣长度 [标准化后]',FontProperties=font,fontsize=14)
8plt.ylabel('花瓣宽度 [标准化后]',FontProperties=font,fontsize=14)
9plt.legend(loc='upper left')
10plt.tight_layout()
11plt.show()
output:
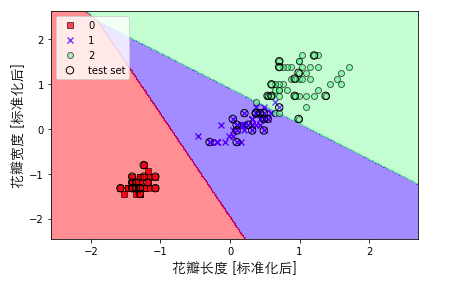
使用正则化处理过拟合
关于过拟合的概念这里就不做过多的解释了,大概就是如下图一样(从左至右分别是欠拟合-正常-过拟合)。
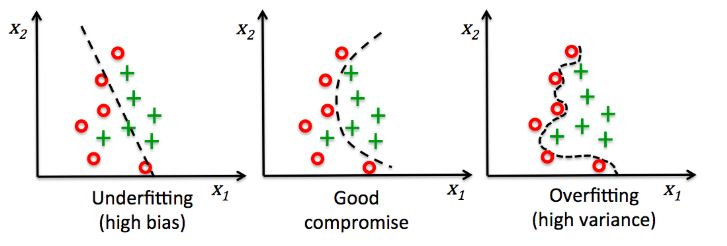
正则化是用来降低overfitting(过拟合)的,对于数据集梳理有限的情况下,防止过拟合的一种方式就是降低模型的复杂度,怎么降低?一种方式就是在cost函数中加入正则化项,正则化项可以理解为复杂度,cost越小越好,但cost加上正则项之后,为了使cost小,就不能让正则项变大,也就是不能让模型更复杂,这样就降低了模型复杂度,也就降低了过拟合。这就是正则化。正则化也有很多种,常见为两种L2和L1。
(机器学学习中的正则化相关的内容可以参见李航的书:《统计学习方法》)
简单来说,越是复杂的模型,对于数据的表达能力就越强,就更加容易出现过度拟合的情况,所以正则化就是通过来降低模型复杂度从而达到模型泛化能力的提升,也就是处理过拟合。
使用Kernel-SVM来解决非线性问题
什么是非线性问题
关于线性和非线性问题的区别,大家应该也有一定的概念,如下图:
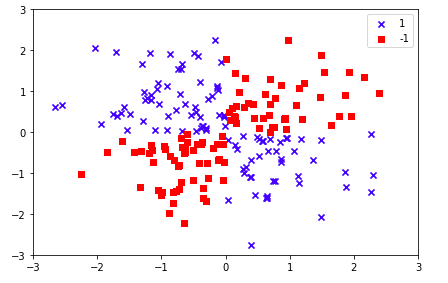
很明显,我们是无法通过线性的方法来达到分类的目的,这样子的问题我们统称为“非线性问题”(个人直观定义,不是很专业严谨)
核方法函数及原理
什么是核方法?核方法就是在原来特征基础上创造出非线性的组合,然后利用映射函数将现有特征维度映射到更高维的特征空间,并且这个高维度特征空间能够使得原来线性不可分数据变成了线性可分的。
同样是上面的数据,其实我们是可以做一定的处理来达到线性分类的目的的,而这个处理就是核方法了。
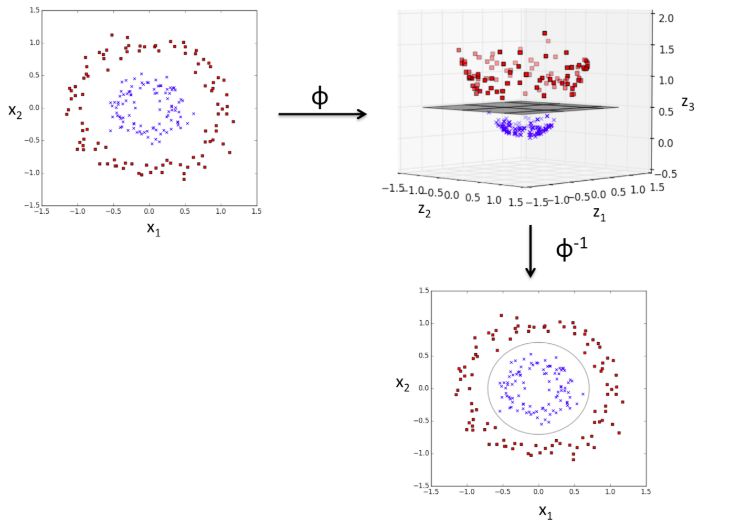
从上图可以看出,高维空间中的线性决策界实际上是低维空间的非线性决策界,这个非线性决策界是线性分类器找不到的,但是通过核方法就找到了。
而我们通过使用SVM(支持向量机)来达到上面的原理,支持向量机是基于线性划分的,它的原理是将低维空间中的点映射到高维空间中,使它们成为线性可分的。再使用线性划分的原理来判断分类边界。在高维空间中,它是一种线性划分,而在原有的数据空间中,它是一种非线性划分。
图:核函数的家族【更多内容见文献2】
利用核技巧kernel SVM在高维空间中寻找分隔超平面
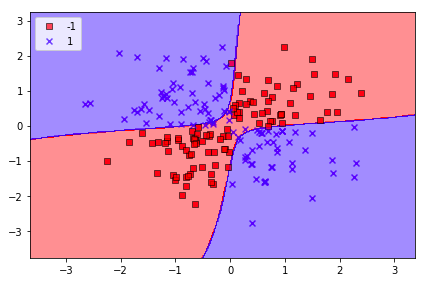
上面讲了那么原理,还是实践出真理,我们自己来通过核SVM来训练一个模型,我们用的数据还是上面的“非线性”数据集。
从下面的分类结果来看,Kernel SVM对于非线性的数据集分类的效果还是非常优秀的,其中我们用到的核函数是高斯核函数。
1from sklearn.svm import SVC
2svm = SVC(kernel='rbf', random_state=0, gamma=0.10, C=10.0)
3# kernel=‘rbf’:径向基函数 (Radial Basis Function 简称 RBF), 就是某种沿径向对称的标量函数,也成为高斯核函数
4# gamma:如果我们增大gamma值,会产生更加柔软的决策界
5svm.fit(X_xor, y_xor)
6plot_decision_regions(X_xor, y_xor,
7 classifier=svm)
8plt.legend(loc='upper left')
9plt.tight_layout()
10plt.show()
output:
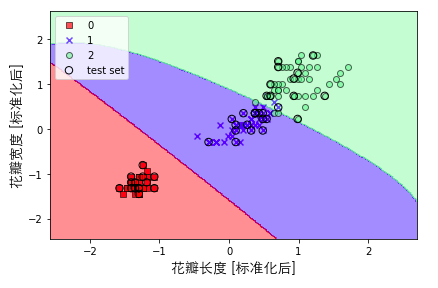
我们试着把Kernel SVM应用在iris数据集看看效果。可以看出,分类的效果也是很好的,这里我们的gamma值(0.2)相比之前(0.1)是变大了,所以分类边界会显得更加“柔软”。
1from sklearn.svm import SVC
2# 为了显示中文(这里是Mac的解决方法,其他的大家可以去百度一下)
3from matplotlib.font_manager import FontProperties
4font = FontProperties(fname='/System/Library/Fonts/STHeiti Light.ttc')
5svm = SVC(kernel='rbf', random_state=0, gamma=0.2, C=1.0)
6svm.fit(X_train_std, y_train)
7# 这里的gamma值比上面的大,边界更加“柔软”
8plot_decision_regions(X_combined_std, y_combined,
9 classifier=svm, test_idx=range(105, 150))
10plt.xlabel('花瓣长度 [标准化后]',FontProperties=font,fontsize=14)
11plt.ylabel('花瓣宽度 [标准化后]',FontProperties=font,fontsize=14)
12plt.legend(loc='upper left')
13plt.tight_layout()
14plt.show()
output:
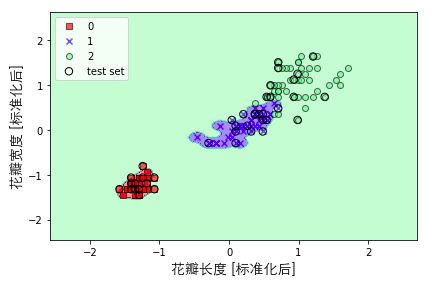
我们可以试着继续加大gamma值,可以看到其实决策边界是过度拟合,模型在训练集上的表现效果很好,但是泛化能力将会是一塌糊涂,所以,我们经常会通过控制gamma值来防止过拟合。
1svm = SVC(kernel='rbf', random_state=0, gamma=100.0, C=1.0)
2svm.fit(X_train_std, y_train)
3# 这里我们继续加大gamma值,可以看出其实是过拟合了
4plot_decision_regions(X_combined_std, y_combined,
5 classifier=svm, test_idx=range(105, 150))
6plt.xlabel('花瓣长度 [标准化后]',FontProperties=font,fontsize=14)
7plt.ylabel('花瓣宽度 [标准化后]',FontProperties=font,fontsize=14)
8plt.legend(loc='upper left')
9plt.tight_layout()
10plt.show()
output:
机器学习决策树模型
关于决策树模型的定义解释这边就不说明了,该算法的框架表述还是比较清晰的,从根节点开始不断得分治,递归,生长,直至得到最后的结果。根节点代表整个训练样本集,通过在每个节点对某个属性的测试验证,算法递归得将数据集分成更小的数据集.某一节点对应的子树对应着原数据集中满足某一属性测试的部分数据集.这个递归过程一直进行下去,直到某一节点对应的子树对应的数据集都属于同一个类为止。
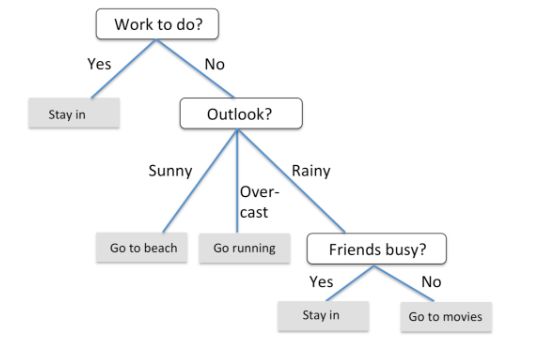
图:决策数模型过程
基于训练集中的特征,决策树模型提出了一系列问题来推测样本的类别。虽然上图中做出的每个决策都是根据离散变量,但也可以用于连续型变量,比如,对于Iris中sepal width这一取值为实数的特征,我们可以问“sepal width是否大于2.8cm?”
训练决策树模型时,我们从根节点出发,使用信息增益(information gain, IG)最大的特征对数据分割。然后迭代此过程。显然,决策树的生成是一个递归过程,在决策树基本算法中,有三种情形会导致递归返回:
(1)当前节点包含的样本全属于同一类别,无需划分;
(2)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
(3)当前节点包含的样本集合为空,不能划分。
每一个节点的样本都属于同一个类,同时这也可能导致树的深度很大,节点很多,很容易引起过拟合。因此,剪枝操作是必不可少的,来控制树深度。
最大化信息增益-获得最大的提升度
关于对信息、熵、信息增益是信息论里的概念,是对数据处理的量化,这几个概念主要是在决策树里用到的概念,因为在利用特征来分类的时候会对特征选取顺序的选择,这几个概念比较抽象。
信息增益( ID3算法 )定义:
以某特征划分数据集前后的熵的差值。熵表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
划分前样本集合D的熵是一定的,entroy(前)
使用某个特征A划分数据集D,计算划分后的数据子集的熵,entroy(后)
信息增益 = entroy(前) - entroy(后)
原理:计算使用所有特征划分数据集D,得到多个特征划分数据集D的信息增益,从这些信息增益中选择最大的,因而当前结点的划分特征便是使信息增益最大的划分所使用的特征。
详细解释:对于待划分的数据集D,其 entroy(前)是一定的,但是划分之后的熵 entroy(后)是不定的,entroy(后)越小说明使用此特征划分得到的子集的不确定性越小(也就是纯度越高),因此 entroy(前) - entroy(后)差异越大,说明使用当前特征划分数据集D的话,其纯度上升的更快。而我们在构建最优的决策树的时候总希望能更快速到达纯度更高的集合,这一点可以参考优化算法中的梯度下降算法,每一步沿着负梯度方法最小化损失函数的原因就是负梯度方向是函数值减小最快的方向。同理:在决策树构建的过程中我们总是希望集合往最快到达纯度更高的子集合方向发展,因此我们总是选择使得信息增益最大的特征来划分当前数据集D。
缺点:信息增益偏向取值较多的特征。
原因:当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,因此划分之后的熵更低,由于划分前的熵是一定的,因此信息增益更大,因此信息增益比较偏向取值较多的特征。
此外,还有信息增益比( C4.5算法 ),基尼指数等算法,大家可以去阅读一下参考文献3的文章。
建立决策树
上面讲了这么多原理,还是要放一些code来给大家学习一下。决策树通过将特征空间分割为矩形,所以其决策界很复杂。但是要知道过大的树深度会导致过拟合,所以决策界并不是越复杂越好。我们调用sklearn,使用熵作为度量,训练一颗最大深度为3的决策树,代码如下:
1from sklearn.tree import DecisionTreeClassifier
2tree = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=0)
3tree.fit(X_train, y_train)
4X_combined = np.vstack((X_train, X_test))
5y_combined = np.hstack((y_train, y_test))
6plot_decision_regions(X_combined, y_combined,
7 classifier=tree, test_idx=range(105, 150))
8plt.xlabel('petal length [cm]')
9plt.ylabel('petal width [cm]')
10plt.legend(loc='upper left')
11plt.tight_layout()
12plt.show()
output:
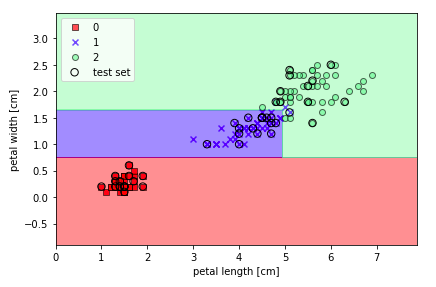
可以看出,这个决策树将数据划分成了三类,不同的颜色代表着一类,此外,sklearn的一大优点是可以将训练好的决策树模型输出,保存在.dot文件。
1from sklearn.tree import export_graphviz
2export_graphviz(tree, out_file='tree.dot', feature_names=['petal length', 'petal width'])
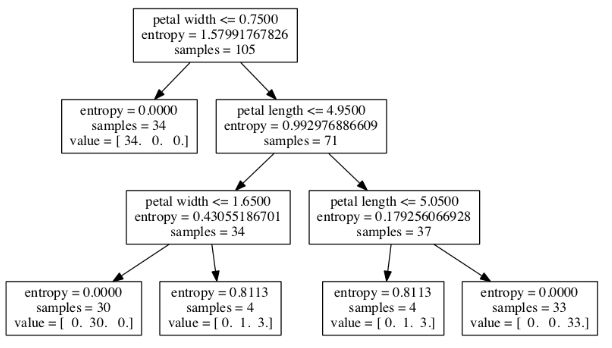
通过随机森林将“弱者”与“强者”模型集成
随机森林一直是广受欢迎的模型,优点很多:优秀的分类表现、扩展性和使用简单。随机森林的思想也不复杂,一个随机森林模型就是多颗决策树的集成。集成学习(ensemble learning)的观点是将多个弱分类器结合来构建一个强分类器,它的泛化误差小且不易过拟合。
随机森林算法大致分为4个步骤:
步骤1: 通过自助法(bootstrap)构建大小为n的一个训练集,即重复抽样选择n个训练样例;
步骤2: 对于刚才新得到的训练集,构建一棵决策树。在每个节点执行以下操作:
通过不重复抽样选择d个特征
利用上面的d个特征,选择某种度量分割节点
步骤3: 重复步骤1和2,k次;
步骤4: 对于每一个测试样例,对k颗决策树的预测结果进行投票。票数最多的结果就是随机森林的预测结果。
直接调用sklearn来看一下随机森林吧。
1from sklearn.ensemble import RandomForestClassifier
2forest = RandomForestClassifier(criterion='entropy',
3 n_estimators=10,
4 random_state=1,
5 n_jobs=2)
6forest.fit(X_train, y_train)
7plot_decision_regions(X_combined, y_combined,
8 classifier=forest, test_idx=range(105, 150))
9plt.xlabel('petal length [cm]')
10plt.ylabel('petal width [cm]')
11plt.legend(loc='upper left')
12plt.tight_layout()
13plt.show()
output:
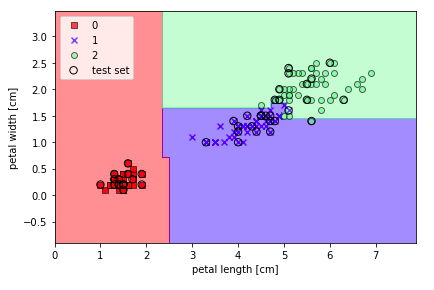
K近邻分类模型(一个懒惰的算法)
本系列最后一个监督学习算法是k紧邻算法(k-nearest neighbor classifier, KNN), 这个算法很有意思,因为他背后的思想和本章其他算法完全不同。
KNN是懒惰学习的一个典型示例。之所以称为“懒惰”并不是由于此类算法看起来很简单,而是在训练模型过程中这类算法并不去学习一个判别式函数(损失函数)而是要记住整个训练集。
这里引入一个概念:参数模型VS变参模型
机器学习算法可以被分为两大类:参数模型和变参模型。
对于参数模型,在训练过程中我们要学习一个函数,重点是估计函数的参数,然后对于新数据集,我们直接用学习到的函数对齐分类。典型的参数模型包括感知机、逻辑斯蒂回归和线性SVM。
对于变参模型,其参数个数不是固定的,它的参数个数随着训练集增大而增多!很多书中变参(nonparametric)被翻译为无参模型,一定要记住,不是没有参数,而是参数个数是变量!变参模型的两个典型示例是决策树/随机森林和核SVM。
KNN属于变参模型的一个子类:基于实例的学习(instance-based learning)。基于实例的学习的模型在训练过程中要做的是记住整个训练集,而懒惰学习是基于实例的学习的特例,在整个学习过程中不涉及损失函数的概念。
KNN算法本身非常简单,步骤如下:
确定k大小和距离度量。
对于测试集中的一个样本,找到训练集中和它最近的k个样本。
将这k个样本的投票结果作为测试样本的类别。
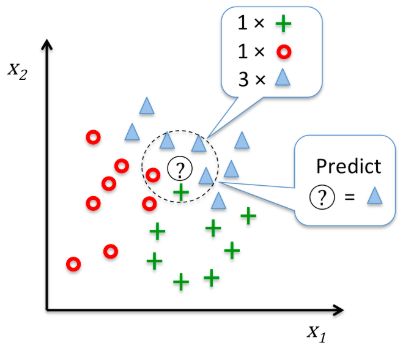
对每一个测试样本,基于事先选择的距离度量,KNN算法在训练集中找到距离最近(最相似)的k个样本,然后将k个样本的类别的投票结果作为测试样本的类别。
像KNN这种基于内存的方法一大优点是:一旦训练集增加了新数据,模型能立刻改变。另一方面,缺点是分类时的最坏计算复杂度随着训练集增大而线性增加,除非特征维度非常低并且算法用诸如KD-树等数据结构实现。此外,我们要一直保存着训练集,不像参数模型训练好模型后,可以丢弃训练集。因此,存储空间也成为了KNN处理大数据的一个瓶颈。
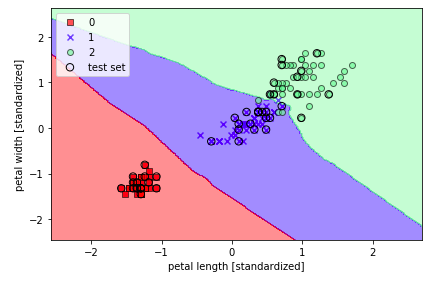
下面我们调用sklearn训练一个KNN模型:
output:
参考文献
1. 深度学习笔记(三):激活函数和损失函数
https://blog.csdn.net/u014595019/article/details/52562159
2. logistic回归详解(二):损失函数(cost function)详解
https://blog.csdn.net/bitcarmanlee/article/details/51165444?locationNum=2&fps=1
3. 为什么说regularization是缓解overfitting的好办法?
https://www.zhihu.com/question/274502949/answer/376629836
4. 最优化方法:L1和L2正则化regularization
https://blog.csdn.net/pipisorry/article/details/52108040
5. 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
https://www.cnblogs.com/arachis/p/Regulazation.html?utm_source=itdadao&utm_medium=referral
6. 核函数(Kernel Function)与SVM
https://blog.csdn.net/bitcarmanlee/article/details/77604484
7. 机器学习技法--Kernel SVM
https://www.jianshu.com/p/446fae533b17
8. 关于线性SVM以及非线性SVM的问题
https://blog.csdn.net/armily/article/details/8452879
9. 高斯核函数
https://baike.baidu.com/item/%E9%AB%98%E6%96%AF%E6%A0%B8%E5%87%BD%E6%95%B0/6661425?fr=aladdin
10. 信息熵(Entropy)、信息增益(Information Gain)
https://www.cnblogs.com/liyuxia713/archive/2012/11/02/2749375.html
11. [机器学习]信息&熵&信息增益
https://www.cnblogs.com/fantasy01/p/4581803.html
12. 决策树--信息增益,信息增益比,Geni指数的理解
https://www.cnblogs.com/muzixi/p/6566803.html
最后
以上就是隐形小蝴蝶最近收集整理的关于Machine Learning-教你用Scikit-Learn来做分类器(完整版)由于文章篇幅较长,还是先把本文的结构贴在前面,如下:的全部内容,更多相关Machine内容请搜索靠谱客的其他文章。








发表评论 取消回复