Reference:
Pattern recognition, by Sergios Theodoridis, Konstantinos Koutroumbas (2009)
Slides of CS4220, TUD
Content
- The Peaking Phenomenon (5.3)
- Class Separability Measures (5.6)
- Divergence
- Chernoff Bound and Bhattacharyya Distance
- Scatter Matrices
- Feature Selection (5.7)
- Sequential Backward Selection
- Sequential Forward Selection
- Floating Search Methods
- Feature Extraction
- Supervised-Linear Discriminant Analysis-LDA (5.8)
- Unsupervised-Principal Component Analysis-PCA (6.3)
- Karhunen–Loève (KL) transform
- Mean Square Error Approximation
- Total Variance
- Nonlinear-Kernel PCA (6.7.1)
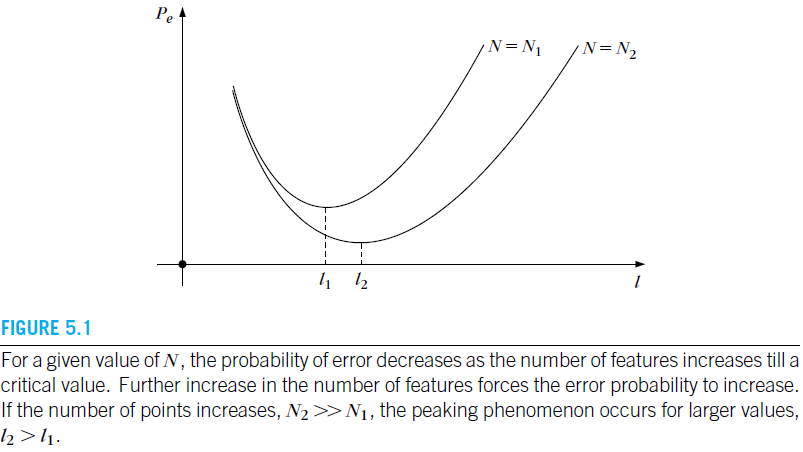
The Peaking Phenomenon (5.3)
More features ⟹ ? stackrel{?}{Longrightarrow} ⟹? Better performance
- If the corresponding PDFs are known, the Bayesian error goes down with more features. We can perfectly discriminate the two classes by arbitrarily increasing the number of features.
- If the PDFs are unknown and the associated parameters must be estimated using a finite training set, then we must try to keep the number of features to a relatively low number.
In practice, for a finite N N N, by increasing the number of features one obtains an initial improvement in performance, but after a critical value further increase of the number of features results in an increase of the probability of error. This phenomenon is also known as the peaking phenomenon.
What feature subset to keep? ⟹ Longrightarrow ⟹ Feature selection / extraction
- Feature selection: select d d d out of p p p measurements
- Feature extraction: map p p p measurements to d d d measurements
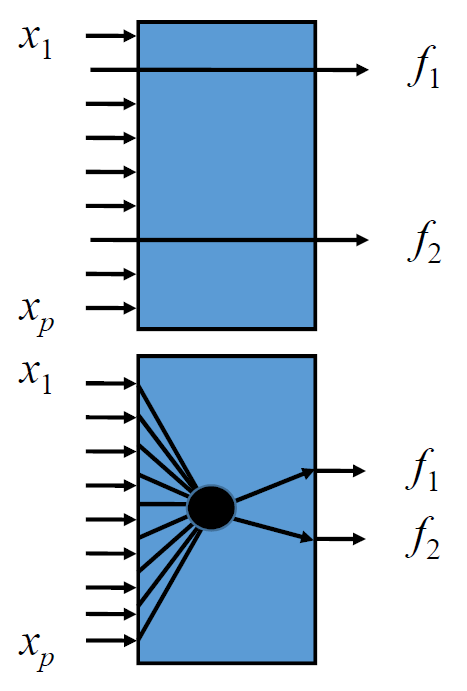
What do we need?
- Criterion functions, e.g., error, class overlap, information loss…
- Optimization or “search” algorithms to find mapping for given criterion
Class Separability Measures (5.6)
Divergence
Let us recall our familiar Bayes rule. Given two classes
ω
1
omega_1
ω1 and
ω
2
omega_2
ω2 and a feature vector
x
mathbf x
x, we select
ω
1
omega _1
ω1 if
P
(
ω
1
∣
x
)
>
P
(
ω
2
∣
x
)
P(omega_1|mathbf x)>P(omega_2|mathbf x)
P(ω1∣x)>P(ω2∣x)
The classification error probability depends on the difference between
P
(
ω
1
∣
x
)
P(omega_1|mathbf x)
P(ω1∣x) and
P
(
ω
2
∣
x
)
P(omega_2|mathbf x)
P(ω2∣x), hence the ratio
P
(
ω
1
∣
x
)
/
P
(
ω
2
∣
x
)
P(omega_1|mathbf x)/P(omega_2|mathbf x)
P(ω1∣x)/P(ω2∣x) can convey useful information concerning the discriminatory capabilities associated with an adopted feature vector
x
mathbf x
x. Alternatively, the same information resides in the ratio
ln
p
(
x
∣
ω
1
)
p
(
x
∣
ω
2
)
≡
D
12
(
x
)
ln frac{p(mathbf x|omega_1)}{p(mathbf x|omega_2)}equiv D_{12}(mathbf x)
lnp(x∣ω2)p(x∣ω1)≡D12(x)
Since
x
mathbf x
x takes different values, it is natural to consider the mean value over class
ω
1
omega_1
ω1 (because
x
mathbf x
x is classified to class
ω
1
omega_1
ω1), that is
D
12
=
∫
−
∞
+
∞
p
(
x
∣
ω
1
)
ln
p
(
x
∣
ω
1
)
p
(
x
∣
ω
2
)
d
x
(DV.1)
D_{12}=int_{-infty}^{+infty} p(mathbf x|omega_1)ln frac{p(mathbf x|omega_1)}{p(mathbf x|omega_2)}dmathbf xtag{DV.1}
D12=∫−∞+∞p(x∣ω1)lnp(x∣ω2)p(x∣ω1)dx(DV.1)
Similar arguments hold for class
ω
2
omega_2
ω2, and we define
D
21
=
∫
−
∞
+
∞
p
(
x
∣
ω
2
)
ln
p
(
x
∣
ω
2
)
p
(
x
∣
ω
1
)
d
x
(DV.2)
D_{21}=int_{-infty}^{+infty} p(mathbf x|omega_2)ln frac{p(mathbf x|omega_2)}{p(mathbf x|omega_1)}dmathbf xtag{DV.2}
D21=∫−∞+∞p(x∣ω2)lnp(x∣ω1)p(x∣ω2)dx(DV.2)
The sum
d
12
=
D
12
+
D
21
(DV.3)
d_{12}=D_{12}+D_{21}tag{DV.3}
d12=D12+D21(DV.3)
is known as the divergence and can be used as a separability measure for the classes
ω
1
,
ω
2
omega_1,omega _2
ω1,ω2, with respect to the adopted feature vector
x
mathbf x
x.
For a multiclass problem, the divergence is computed for every class pair
ω
i
,
ω
j
omega_i,omega_j
ωi,ωj
d
i
j
=
D
i
j
+
D
j
i
=
∫
−
∞
+
∞
[
p
(
x
∣
ω
i
)
−
p
(
x
∣
ω
j
)
]
ln
p
(
x
∣
ω
i
)
p
(
x
∣
ω
j
)
d
x
(DV.4)
d_{ij}=D_{ij}+D_{ji}=int_{-infty}^{+infty}[p(mathbf x|omega_i)-p(mathbf x|omega_j)]ln frac{p(mathbf x|omega_i)}{p(mathbf x|omega_j)}dmathbf x tag{DV.4}
dij=Dij+Dji=∫−∞+∞[p(x∣ωi)−p(x∣ωj)]lnp(x∣ωj)p(x∣ωi)dx(DV.4)
and the average class separability can be computed using the average divergence
d
=
∑
i
=
1
M
∑
j
=
1
M
P
(
ω
i
)
P
(
ω
j
)
d
i
j
(DV.5)
d=sum_{i=1}^Msum_{j=1}^MP(omega_i)P(omega_j)d_{ij}tag{DV.5}
d=i=1∑Mj=1∑MP(ωi)P(ωj)dij(DV.5)
If the components of the feature vector are statistically independent, then it can be shown that
d
i
j
(
x
1
,
x
2
,
⋯
,
x
l
)
=
∫
−
∞
+
∞
[
p
(
x
∣
ω
i
)
−
p
(
x
∣
ω
j
)
]
∑
r
=
1
l
ln
p
(
x
r
∣
ω
i
)
p
(
x
r
∣
ω
j
)
d
x
=
a
∑
r
=
1
l
∫
−
∞
+
∞
[
p
(
x
r
∣
ω
i
)
−
p
(
x
r
∣
ω
j
)
]
ln
p
(
x
r
∣
ω
i
)
p
(
x
r
∣
ω
j
)
d
x
r
=
∑
r
=
1
l
d
i
j
(
x
r
)
(DV.6)
begin{aligned} d_{ij}(x_1,x_2,cdots,x_l)&=int_{-infty}^{+infty}[p(mathbf x|omega_i)-p(mathbf x|omega_j)]sum_{r=1}^{l}ln frac{p(x_r|omega_i)}{p(x_r|omega_j)}dmathbf x \ &stackrel{a}{=}sum_{r=1}^{l}int_{-infty}^{+infty}[p(x_r|omega_i)-p(x_r|omega_j)]ln frac{p(x_r|omega_i)}{p(x_r|omega_j)}dx_r\ &=sum_{r=1}^{l}d_{ij}(x_r) end{aligned}tag{DV.6}
dij(x1,x2,⋯,xl)=∫−∞+∞[p(x∣ωi)−p(x∣ωj)]r=1∑llnp(xr∣ωj)p(xr∣ωi)dx=ar=1∑l∫−∞+∞[p(xr∣ωi)−p(xr∣ωj)]lnp(xr∣ωj)p(xr∣ωi)dxr=r=1∑ldij(xr)(DV.6)
where
=
a
stackrel{a}{=}
=a is due to
∫
−
∞
+
∞
⋯
∫
−
∞
+
∞
p
(
x
∣
ω
i
)
−
p
(
x
∣
ω
j
)
d
x
1
⋯
d
x
r
−
1
d
x
r
+
1
⋯
d
x
l
=
p
(
x
r
∣
ω
i
)
−
p
(
x
r
∣
ω
j
)
int_{-infty}^{+infty}cdotsint_{-infty}^{+infty}p(mathbf x|omega_i)-p(mathbf x|omega_j)dx_1cdots dx_{r-1}dx_{r+1}cdots dx_l=p(x_r|omega_i)-p(x_r|omega_j)
∫−∞+∞⋯∫−∞+∞p(x∣ωi)−p(x∣ωj)dx1⋯dxr−1dxr+1⋯dxl=p(xr∣ωi)−p(xr∣ωj)
Assuming now that the density functions are Gaussians
N
(
μ
i
,
Σ
i
)
mathcal N(boldsymbol mu_i,boldsymbol Sigma_i)
N(μi,Σi) and
N
(
μ
j
,
Σ
j
)
mathcal N(boldsymbol mu_j,boldsymbol Sigma_j)
N(μj,Σj), respectively, the computation of the divergence is simplified, and it is not difficult to show that
d
i
j
=
1
2
t
r
a
c
e
{
Σ
i
−
1
Σ
j
+
Σ
j
−
1
Σ
i
−
2
I
}
+
1
2
(
μ
i
−
μ
j
)
T
(
Σ
i
−
1
+
Σ
j
−
1
)
(
μ
i
−
μ
j
)
(DV.7)
d_{ij}=frac{1}{2}mathrm{trace}{boldsymbol Sigma_i^{-1}boldsymbol Sigma_j+boldsymbol Sigma_j^{-1}boldsymbol Sigma_i-2I }+frac{1}{2}(boldsymbol mu_i-boldsymbol mu_j)^T(boldsymbol Sigma_i^{-1}+boldsymbol Sigma_j^{-1})(boldsymbol mu_i-boldsymbol mu_j)tag{DV.7}
dij=21trace{Σi−1Σj+Σj−1Σi−2I}+21(μi−μj)T(Σi−1+Σj−1)(μi−μj)(DV.7)
It can be seen that a class separability measure cannot depend only on the difference of the mean values; it must also be variance dependent. If the covariance matrices of the two Gaussian distributions are equal, then the divergence is further simplified to
d
i
j
=
(
μ
i
−
μ
j
)
T
Σ
−
1
(
μ
i
−
μ
j
)
d_{ij}=(boldsymbol mu_i-boldsymbol mu_j)^Tboldsymbol Sigma^{-1}(boldsymbol mu_i-boldsymbol mu_j)
dij=(μi−μj)TΣ−1(μi−μj)
which is nothing other than the Mahalanobis distance between the corresponding mean vectors. This has a direct relation with the Bayes error, which is a desirable property for class separation measures.
Chernoff Bound and Bhattacharyya Distance
The minimum attainable classification error of the Bayes classifier for two classes
ω
1
,
ω
2
omega_1,omega_2
ω1,ω2 can be written as
P
e
=
∫
−
∞
+
∞
min
[
P
(
ω
i
)
p
(
x
∣
ω
i
)
,
P
(
ω
j
)
p
(
x
∣
ω
j
)
]
d
x
(CB.1)
P_e=int_{-infty}^{+infty} min [P(omega_i)p(mathbf x|omega_i),P(omega_j)p(mathbf x|omega_j)]dmathbf x tag{CB.1}
Pe=∫−∞+∞min[P(ωi)p(x∣ωi),P(ωj)p(x∣ωj)]dx(CB.1)
Analytic computation of this integral in the general case is not possible. However, an upper bound can be derived based on the inequality
min
[
a
,
b
]
≤
a
s
b
1
−
s
for
a
,
b
≥
0
,
and
0
≤
s
≤
1
(CB.2)
min [a,b]le a^sb^{1-s}quad text{for }a,bge 0, text{ and }0le s le1 tag{CB.2}
min[a,b]≤asb1−sfor a,b≥0, and 0≤s≤1(CB.2)
Combining
(
C
B
.
1
)
(CB.1)
(CB.1) and
(
C
B
.
2
)
(CB.2)
(CB.2), we get
P
e
≤
P
(
ω
i
)
s
P
(
ω
j
)
1
−
s
∫
−
∞
+
∞
p
(
x
∣
ω
i
)
s
p
(
x
∣
ω
j
)
1
−
s
d
x
≡
ϵ
C
B
(CB.3)
P_ele P(omega_i)^sP(omega_j)^{1-s}int_{-infty}^{+infty}p(mathbf x|omega _i)^sp(mathbf x|omega_j)^{1-s}dmathbf xequiv epsilon_{CB}tag{CB.3}
Pe≤P(ωi)sP(ωj)1−s∫−∞+∞p(x∣ωi)sp(x∣ωj)1−sdx≡ϵCB(CB.3)
ϵ
C
B
epsilon_{CB}
ϵCB is known as the Chernoff bound. The minimum bound can be computed by minimizing
ϵ
C
B
epsilon_{CB}
ϵCB w.r.t
s
s
s.
A special form of the bound results for
s
=
1
/
2
s=1/2
s=1/2. For Gaussian distributions
N
(
μ
i
,
Σ
i
)
mathcal N(boldsymbol mu_i,boldsymbol Sigma_i)
N(μi,Σi) and
N
(
μ
j
,
Σ
j
)
mathcal N(boldsymbol mu_j,boldsymbol Sigma_j)
N(μj,Σj), it reduces to
ϵ
C
B
=
P
(
ω
i
)
P
(
ω
j
)
exp
(
−
B
)
epsilon_{CB}=sqrt{P(omega_i)P(omega_j)}exp(-B)
ϵCB=P(ωi)P(ωj)exp(−B)
where
B
=
1
8
(
μ
i
−
μ
j
)
T
(
Σ
i
+
Σ
j
2
)
−
1
(
μ
i
−
μ
j
)
+
1
2
ln
∣
Σ
i
+
Σ
j
2
∣
∣
Σ
i
∣
∣
Σ
j
∣
(CB.4)
B=frac{1}{8}(boldsymbol mu_i-boldsymbol mu_j)^Tleft(frac{boldsymbol Sigma_i+boldsymbol Sigma_j}{2}right)^{-1}(boldsymbol mu_i-boldsymbol mu_j)+frac{1}{2}ln frac{left|frac{boldsymbol Sigma_i+boldsymbol Sigma_j}{2} right|}{sqrt{|boldsymbol Sigma_i||boldsymbol Sigma_j|}}tag{CB.4}
B=81(μi−μj)T(2Σi+Σj)−1(μi−μj)+21ln∣Σi∣∣Σj∣∣∣∣2Σi+Σj∣∣∣(CB.4)
which is known as the Bhattacharyya distance.
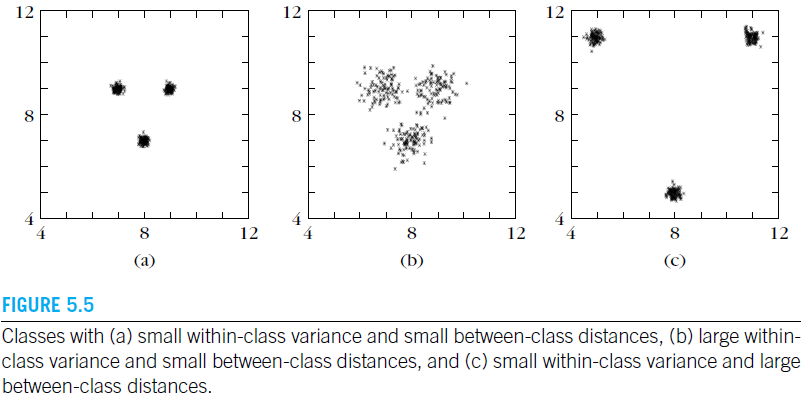
Scatter Matrices
A major disadvantage of the class separability criteria considered so far is that they are not easily computed,unless the Gaussian assumption is employed. We will now turn our attention to a set of simpler criteria, built upon information related to the way feature vector samples are scattered in the l l l-dimensional space. To this end, the following matrices are defined:
-
Within-class scatter matrix
S w = ∑ i = 1 M P i Σ i (SM.1) mathbf S_w=sum_{i=1}^MP_i boldsymbol Sigma_i tag{SM.1} Sw=i=1∑MPiΣi(SM.1)
where Σ i boldsymbol Sigma_i Σi is the covariance matrix for class ω i omega_i ωi
Σ i = E [ ( x − μ i ) ( x − μ i ) T ] ≃ ∑ x ∈ ω i x x T n i − μ i μ i T boldsymbol Sigma_i=E[(mathbf x-boldsymbol mu_i)(mathbf x-boldsymbol mu_i)^T]simeqfrac{sum_{mathbf xin omega_i}mathbf xmathbf x^T}{n_i}-boldsymbol mu_iboldsymbol mu_i^T Σi=E[(x−μi)(x−μi)T]≃ni∑x∈ωixxT−μiμiT
and P i P_i Pi is the priori probability of class ω i omega_i ωi. That is, P i ≃ n i / N P_isimeq n_i/N Pi≃ni/N, where n i n_i ni is the number of samples in class ω i omega_i ωi, out of a total of N N N samples. -
Between-class scatter matrix
S b = ∑ i = 1 M P i ( μ i − μ 0 ) ( μ i − μ 0 ) T (SM.2) mathbf S_b=sum_{i=1}^M P_i(boldsymbol mu_i-boldsymbol mu_0)(boldsymbol mu_i-boldsymbol mu_0)^Ttag{SM.2} Sb=i=1∑MPi(μi−μ0)(μi−μ0)T(SM.2)
where μ 0 boldsymbol mu_{0} μ0 is the global mean vector
μ 0 = ∑ i M P i μ i boldsymbol{mu}_{0}=sum_{i}^{M} P_{i} boldsymbol{mu}_{i} μ0=i∑MPiμi -
Mixture scatter matrix
S m = E [ ( x − μ 0 ) ( x − μ 0 ) T ] ≃ ∑ x x T N − μ 0 μ 0 T (SM.3) mathbf S_{m}=Eleft[left(mathbf x-boldsymbol mu_{0}right)left(mathbf x-boldsymbol mu_{0}right)^{T}right] simeqfrac{summathbf xmathbf x^T}{N}-boldsymbol mu_0boldsymbol mu_0^T tag{SM.3} Sm=E[(x−μ0)(x−μ0)T]≃N∑xxT−μ0μ0T(SM.3)That is, S m mathbf S_{m} Sm is the covariance matrix of the feature vector with respect to the global mean. It can be shown that (with μ 0 = ∑ i M P i μ i boldsymbol{mu}_{0}=sum_{i}^{M} P_{i} boldsymbol{mu}_{i} μ0=∑iMPiμi)
S m = S w + S b (SM.4) mathbf S_{m}=mathbf S_{w}+mathbf S_{b}tag{SM.4} Sm=Sw+Sb(SM.4)
From these definitions it is straightforward to see that the criterion
J
1
=
trace
{
S
m
}
trace
{
S
w
}
(SM.5)
J_{1}=frac{operatorname{trace}left{mathbf S_{m}right}}{operatorname{trace}left{mathbf S_{w}right}}tag{SM.5}
J1=trace{Sw}trace{Sm}(SM.5)
takes large values when samples in the
l
l
l-dimensional space are well clustered around their mean, within each class, and the clusters of the different classes are well separated. Sometimes
S
b
mathbf S_b
Sb is used in place of
S
m
mathbf S_m
Sm.
An alternative criterion results if determinants are used in the place of traces. This is justified for scatter matrices that are symmetric positive definite, and thus their eigenvalues are positive. The trace is equal to the sum of the eigenvalues, while the determinant is equal to their product. Hence, large values of
J
1
J_1
J1 also correspond to large values of the criterion
J
2
=
∣
S
m
∣
∣
S
w
∣
=
∣
S
w
−
1
S
m
∣
(SM.6)
J_2=frac{|mathbf S_m|}{|mathbf S_w|}=|mathbf S_w^{-1}mathbf S_m|tag{SM.6}
J2=∣Sw∣∣Sm∣=∣Sw−1Sm∣(SM.6)
or
J
3
=
t
r
a
c
e
{
S
w
−
1
S
m
}
(SM.7)
J_3=mathrm{trace}{mathbf S_w^{-1}mathbf S_m}tag{SM.7}
J3=trace{Sw−1Sm}(SM.7)
These criteria take a special form in the one-dimensional, two-class problem. In this case,it is easy to see that for equiprobable classes
∣
S
w
∣
|mathbf S_w|
∣Sw∣ is proportional to
σ
1
2
+
σ
2
2
sigma^2_1+sigma^2_2
σ12+σ22 and
∣
S
b
∣
|mathbf S_b|
∣Sb∣ proportional to
(
μ
1
−
μ
2
)
2
(mu_1-mu_2)^2
(μ1−μ2)2. Using
J
2
J_2
J2 leads to the so-called Fisher’s discriminant ratio (FDR) results
F
D
R
=
(
μ
1
−
μ
2
)
2
σ
1
2
+
σ
2
2
(SM.8)
FDR=frac{(mu_1-mu_2)^2}{sigma^2_1+sigma^2_2}tag{SM.8}
FDR=σ12+σ22(μ1−μ2)2(SM.8)
Feature Selection (5.7)
The object is to select a subset of l l l out of m m m measurements which optimizes chosen criterion. Theoretically, there are C m l = m ! l ! ( m − l ) ! C_m^l=frac{m!}{l!(m-l)!} Cml=l!(m−l)!m! subsets to be compared. Since the computation may not affordable in high dimension, we settle for suboptimal searching techniques.
The simplest way, named scalar feature selection, treats features individually. The value of the criterion C ( k ) C(k) C(k) is computed for each of the features, k = 1 , 2 , . . . , m k=1, 2, . . . ,m k=1,2,...,m. The l l l features corresponding to the l l l best values of C ( k ) C(k) C(k) are then selected to form the feature vector.
However, such approaches do not take into account existing correlations between features. Therefore, we proceed to techniques dealing with vectors, named vector feature selection.
Sequential Backward Selection
Starting from m m m, at each step we drop out one feature from the “best” combination until we obtain a vector of l l l features.
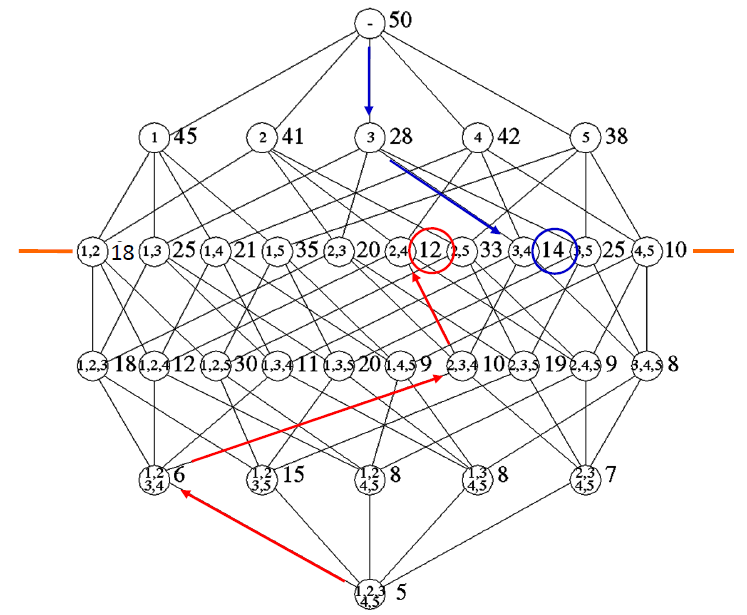
For example, let m = 4 m=4 m=4, and the originally available features are x 1 , x 2 , x 3 , x 4 . x_{1}, x_{2}, x_{3}, x_{4} . x1,x2,x3,x4. We wish to select two of them. The selection procedure consists of the following steps:
- Adopt a class separability criterion, C , C, C, and compute its value for the feature vector [ x 1 , x 2 , x 3 , x 4 ] T left[x_{1}, x_{2}, x_{3}, x_{4}right]^{T} [x1,x2,x3,x4]T
- Eliminate one feature and for each of the possible resulting combinations, that is, [ x 1 , x 2 , x 3 ] T , [ x 1 , x 2 , x 4 ] T , [ x 1 , x 3 , x 4 ] T , [ x 2 , x 3 , x 4 ] T , left[x_{1}, x_{2}, x_{3}right]^{T},left[x_{1}, x_{2}, x_{4}right]^{T},left[x_{1}, x_{3}, x_{4}right]^{T},left[x_{2}, x_{3}, x_{4}right]^{T}, [x1,x2,x3]T,[x1,x2,x4]T,[x1,x3,x4]T,[x2,x3,x4]T, compute the corresponding criterion value. Select the combination with the best value, say [ x 1 , x 2 , x 3 ] T left[x_{1}, x_{2}, x_{3}right]^{T} [x1,x2,x3]T
- From the selected three-dimensional feature vector eliminate one feature and for each of the resulting combinations, [ x 1 , x 2 ] T , [ x 1 , x 3 ] T , [ x 2 , x 3 ] T , left[x_{1}, x_{2}right]^{T},left[x_{1}, x_{3}right]^{T},left[x_{2}, x_{3}right]^{T}, [x1,x2]T,[x1,x3]T,[x2,x3]T, compute the criterion value and select the one with the best value.
Sequential Forward Selection
Here, the reverse to the preceding procedure is followed:
- Compute the criterion value for each of the features. Select the feature with the best value, say x 1 x_{1} x1
- Form all possible two-dimensional vectors that contain the winner from the previous step, that is, [ x 1 , x 2 ] T , [ x 1 , x 3 ] T , [ x 1 , x 4 ] T left[x_{1}, x_{2}right]^{T},left[x_{1}, x_{3}right]^{T},left[x_{1}, x_{4}right]^{T} [x1,x2]T,[x1,x3]T,[x1,x4]T. Compute the criterion value for each of them and select the best one, say [ x 1 , x 3 ] T left[x_{1}, x_{3}right]^{T} [x1,x3]T.
This figure shows how to select 2 out of 5 features using backward selection (red arrows) and forward selection (blue arrows). The black lines show all combinations needed to be computed if we want to find the optimal solution.
Note: Here we choose lower values, but sometimes we choose larger values, depending on the specific criterion.
Floating Search Methods
The k + 1 k+1 k+1 best subset X k + 1 X_{k+1} Xk+1 is formed by “borrowing” an element from Y m − k Y_{m-k} Ym−k. Then, return to the previously selected lower dimension subsets to check whether the inclusion of this new element improves the criterion C C C. If it does,the new element replaces one of the previously selected features.
Feature Extraction
We are going to introduce two classical linear feature extractors: LDA and PCA.
Let our data points, x mathbf x x, be in the m m m-dimensional space and assume that they originate from two classes. Our goal is to generate a feature y mathbf y y as a linear combination of the components of x mathbf x x. In such a way, we expect to “squeeze” the classification related information residing in x mathbf x x in a smaller number of features.
Supervised-Linear Discriminant Analysis-LDA (5.8)
In this section, this goal is achieved by seeking the direction w mathbf w w in the m m m dimensional space, along which the two classes are best separated in some way.
Given an
x
∈
R
m
mathbf xin mathcal R^m
x∈Rm the scalar
y
=
w
T
x
∥
w
∥
(LDA.1)
y=frac{mathbf w^T mathbf x}{|mathbf w|} tag{LDA.1}
y=∥w∥wTx(LDA.1)
is the projection of
x
mathbf x
x along
w
mathbf w
w. Since scaling all our feature vectors by the same factor does not add any classification-related information, we will ignore the scaling factor
∥
w
∥
|mathbf w|
∥w∥.
For one dimensional, two-class problem, we can adopt the [Fisher’s discriminant ratio (FDR)](# Scatter Matrices)
F
D
R
=
(
μ
1
−
μ
2
)
2
σ
1
2
+
σ
2
2
(SM.8)
FDR=frac{(mu_1-mu_2)^2}{sigma^2_1+sigma^2_2}tag{SM.8}
FDR=σ12+σ22(μ1−μ2)2(SM.8)
where
μ
1
,
μ
2
mu_1,mu_2
μ1,μ2 are the mean values and
σ
1
2
,
σ
2
2
sigma_1^2,sigma^2_2
σ12,σ22 the variances of
y
y
y in the two classes
ω
1
omega_1
ω1 and
ω
2
omega_2
ω2, respectively, after the projection along
w
mathbf w
w. Using the definition in
(
L
D
A
.
1
)
(LDA.1)
(LDA.1) and omitting
∥
w
∥
|mathbf w|
∥w∥, it is readily seen that
μ
i
=
w
T
μ
i
(LDA.2)
mu_i=mathbf w^T boldsymbol mu_itag{LDA.2}
μi=wTμi(LDA.2)
where
μ
i
boldsymbol mu_i
μi is the mean value of the data in
ω
i
omega_i
ωi in the
m
m
m-dimensional space. Assuming the classes to be equiprobable and recalling the definition of
S
b
mathbf S_b
Sb and
S
w
mathbf S_w
Sw in [Scatter Matrices](# Scatter Matrices), it is easily shown that
(
μ
1
−
μ
2
)
2
=
w
T
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
w
∝
w
T
S
b
w
(LDA.3)
(mu_1-mu_2)^2=mathbf w^T(boldsymbol mu_1-boldsymbol mu_2)(boldsymbol mu_1-boldsymbol mu_2)^T mathbf w propto mathbf w^Tmathbf S_bmathbf wtag{LDA.3}
(μ1−μ2)2=wT(μ1−μ2)(μ1−μ2)Tw∝wTSbw(LDA.3)
σ i 2 = E [ ( y − μ i ) 2 ] = E [ w T ( x − μ i ) ( x − μ i ) T w ] = w T Σ i w sigma_i^2=E[(y-mu_i)^2]=E[mathbf w^T (mathbf x-boldsymbol mu_i)(mathbf x-boldsymbol mu_i)^Tmathbf w]=mathbf w^T boldsymbol Sigma_imathbf w σi2=E[(y−μi)2]=E[wT(x−μi)(x−μi)Tw]=wTΣiw
σ 1 2 + σ 2 2 ∝ w T S w w (LDA.4) sigma_1^2+sigma_2^2 propto mathbf w^T mathbf S_w mathbf w tag{LDA.4} σ12+σ22∝wTSww(LDA.4)
Combining
(
S
M
.
8
)
(SM.8)
(SM.8),
(
L
D
A
.
3
)
(LDA.3)
(LDA.3), and
(
L
D
A
.
4
)
(LDA.4)
(LDA.4), we end up that the optimal direction is obtained by maximizing Fisher’s criterion
F
D
R
(
w
)
=
w
T
S
b
w
w
T
S
w
w
(LDA.5)
FDR(mathbf w)=frac{mathbf w^Tmathbf S_bmathbf w}{mathbf w^Tmathbf S_wmathbf w} tag{LDA.5}
FDR(w)=wTSwwwTSbw(LDA.5)
w.r.t.
w
mathbf w
w. This is celebrated generalized Rayleigh quotient. Since
S
w
mathbf S_w
Sw is positive definite and symmetric (assuming
S
w
mathbf S_w
Sw is invertible), let
S
w
=
D
D
mathbf S_w=mathbf D mathbf D
Sw=DD and
v
=
D
w
mathbf v=mathbf D mathbf w
v=Dw. Then
F
D
R
(
v
)
=
v
T
D
−
1
S
b
D
−
1
v
v
T
v
FDR(mathbf v)=frac{mathbf v^T mathbf D^{-1} mathbf S_bmathbf D^{-1} mathbf v}{mathbf v^Tmathbf v}
FDR(v)=vTvvTD−1SbD−1v
It is maximized if
v
mathbf v
v is chosen such that
D
−
1
S
b
D
−
1
v
=
λ
v
mathbf D^{-1} mathbf S_bmathbf D^{-1} mathbf v=lambda mathbf v
D−1SbD−1v=λv
or in terms of
w
mathbf w
w,
S
w
−
1
S
b
w
=
λ
w
(LDA.6)
mathbf S_w^{-1}mathbf S_bmathbf w=lambda mathbf wtag{LDA.6}
Sw−1Sbw=λw(LDA.6)
where
λ
lambda
λ is the largest eigenvalue of
S
w
−
1
S
b
mathbf S_w^{-1}mathbf S_b
Sw−1Sb.
However, for our simple case we do not have to worry about any eigen decomposition. By the definition of
S
b
mathbf S_b
Sb we have that
λ
S
w
w
=
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
w
=
α
(
μ
1
−
μ
2
)
lambda mathbf S_wmathbf w=(boldsymbol mu_1-boldsymbol mu_2)(boldsymbol mu_1-boldsymbol mu_2)^Tmathbf w=alpha (boldsymbol mu_1-boldsymbol mu_2)
λSww=(μ1−μ2)(μ1−μ2)Tw=α(μ1−μ2)
where
α
alpha
α is a scalar. Solving the previous equation w.r.t.
w
mathbf w
w, and since we are only interested in the direction of
w
mathbf w
w, we can write
w
=
S
w
−
1
(
μ
1
−
μ
2
)
(LDA.7)
mathbf w=mathbf S_w^{-1}(boldsymbol mu_1-boldsymbol mu_2)tag{LDA.7}
w=Sw−1(μ1−μ2)(LDA.7)
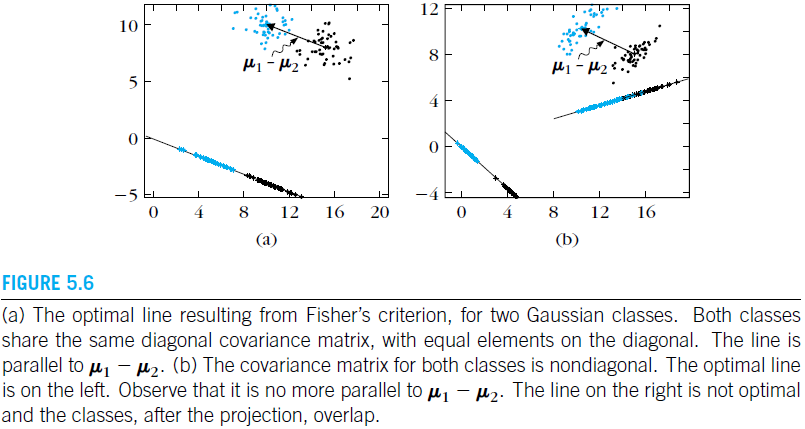
Thus, we have reduced the number of features from
m
m
m to
1
1
1 in an optimal way. Classification can now be performed based on
y
y
y. The resulting classifier is
g
(
x
)
=
y
+
w
0
=
(
μ
1
−
μ
2
)
T
S
w
−
1
x
+
w
0
(LDA.8)
g(mathbf x)=y+w_0=(boldsymbol mu_1-boldsymbol mu_2)^Tmathbf S_w^{-1}mathbf x+w_0tag{LDA.8}
g(x)=y+w0=(μ1−μ2)TSw−1x+w0(LDA.8)
It can be interpreted in two ways. Firstly, after the projection we got a scalar
y
y
y. Compare it to some threshold
w
0
w_0
w0 and decide which class it belongs to. Secondly, we can omit the projection procedure and simply view
g
(
x
)
g(mathbf x)
g(x) as a boundary which is perpendicular to
w
mathbf w
w.
However, the threshold
w
0
w_0
w0 is not provided by Fisher’s condition and has to be determined. For example, for the case of two Gaussian classes with the same covariance matrix the optimal classifier is shown to take the form
g
(
x
)
=
(
μ
1
−
μ
2
)
T
S
w
−
1
(
x
−
1
2
(
μ
1
+
μ
2
)
)
−
ln
P
(
ω
2
)
P
(
ω
1
)
g(boldsymbol{x})=left(boldsymbol{mu}_{1}-boldsymbol{mu}_{2}right)^{T} boldsymbol{S}_{w}^{-1}left(boldsymbol{x}-frac{1}{2}left(boldsymbol{mu}_{1}+boldsymbol{mu}_{2}right)right)-ln frac{Pleft(omega_{2}right)}{Pleft(omega_{1}right)}
g(x)=(μ1−μ2)TSw−1(x−21(μ1+μ2))−lnP(ω1)P(ω2)
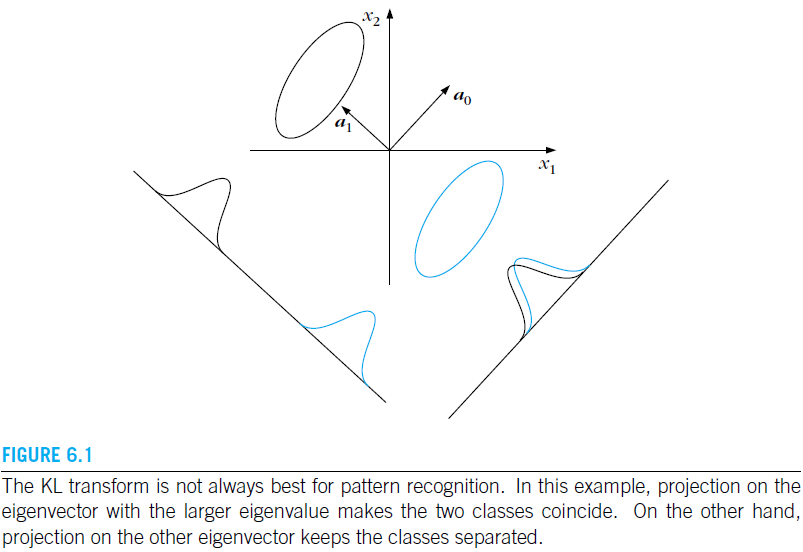
Unsupervised-Principal Component Analysis-PCA (6.3)
In LDA, the class labels of the feature vectors were assumed known, and this information was optimally exploited to compute the transformation matrix. In PCA, however, we do not know the class labels of feature vectors. The transformation matrix will exploit the statistical information describing the data instead.
Karhunen–Loève (KL) transform
We assume that the data samples have zero mean. A desirable property of the generated features is to be mutually uncorrelated in an effort to avoid information redundancies. Therefore, we begin this section by first developing a method that generates mutually uncorrelated features, that is, E [ y ( i ) y ( j ) ] = 0 , i ≠ j E[y(i)y(j)]=0,ine j E[y(i)y(j)]=0,i=j.
Let
y
=
A
T
x
(PCA.1)
mathbf y=mathbf A^T mathbf xtag{PCA.1}
y=ATx(PCA.1)
Since we have assumed that
E
[
x
]
=
0
E[mathbf x]=mathbf 0
E[x]=0, it is readily seen that
E
[
y
]
=
0
E[mathbf y]=0
E[y]=0. From the definition of the correlation matrix we have
R
y
=
E
[
y
y
T
]
=
A
T
R
x
A
(PCA.2)
mathbf R_y=E[mathbf ymathbf y^T]=mathbf A^T mathbf R_x mathbf A tag{PCA.2}
Ry=E[yyT]=ATRxA(PCA.2)
In practice,
R
x
mathbf R_x
Rx is estimated as an average over the given set of training vectors.
Note that
R
x
mathbf R_{x}
Rx is a symmetric matrix, and hence its eigenvectors are mutually orthogonal. Thus, if matrix
A
mathbf A
A is chosen so that its columns are the orthonormal eigenvectors
a
i
,
i
=
0
,
1
,
…
,
N
−
1
,
boldsymbol{a}_{i}, i=0,1, ldots, N-1,
ai,i=0,1,…,N−1, of
R
x
,
mathbf R_{x},
Rx, then
R
y
mathbf R_{y}
Ry is diagonal
R
y
=
A
T
R
x
A
=
Λ
(PCA.3)
mathbf R_{y}=mathbf A^{T}mathbf R_{x} mathbf A=mathbf Lambdatag{PCA.3}
Ry=ATRxA=Λ(PCA.3)
where
Λ
mathbf Lambda
Λ is the diagonal matrix having as elements on its diagonal the respective eigenvalues
λ
i
,
i
=
0
,
1
,
…
,
N
−
1
,
lambda_{i}, i=0,1, ldots, N-1,
λi,i=0,1,…,N−1, of
R
x
mathbf R_{x}
Rx. Furthermore, assuming
R
x
mathbf R_{x}
Rx to be positive definite so the eigenvalues are positive. The resulting transform is known as the Karhunen–Loève (KL) transform, and it achieves our original goal of generating mutually uncorrelated features.
Although our starting point was to generate mutually uncorrelated features, the KL transform turns out to have a number of other important properties, which provide different ways for its interpretation and also the secret for its popularity.
Mean Square Error Approximation
Since
A
mathbf A
A is unitary, from
(
P
C
A
.
1
)
(PCA.1)
(PCA.1) we have
A
y
=
x
mathbf A mathbf y=mathbf x
Ay=x, or
x
=
∑
i
=
0
N
−
1
y
(
i
)
a
i
and
y
(
i
)
=
a
i
T
x
(PCA.4)
mathbf x=sum_{i=0}^{N-1}y(i)mathbf a_iquad text{and} quad y(i)=mathbf a_i^T mathbf xtag{PCA.4}
x=i=0∑N−1y(i)aiandy(i)=aiTx(PCA.4)
To reduce the dimension, let us now define a new vector in the
m
m
m-dimensional subspace
x
^
=
∑
i
=
0
m
−
1
y
(
i
)
a
i
(PCA.5)
hat{mathbf x}=sum_{i=0}^{m-1} y(i) boldsymbol{a}_{i}tag{PCA.5}
x^=i=0∑m−1y(i)ai(PCA.5)
where only
m
m
m of the basis vectors are involved. Obviously, this is nothing but the projection of
x
mathbf x
x onto the subspace spanned by the
m
m
m (orthonormal) eigenvectors involved in the summation. If we try to approximate
x
mathbf x
x by its projection
x
^
,
hat{mathbf x},
x^, the resulting mean square error is given by
E
[
∥
x
−
x
^
∥
2
]
=
E
[
∥
∑
i
=
m
N
−
1
y
(
i
)
a
i
∥
2
]
(PCA.6)
Eleft[|boldsymbol{x}-hat{boldsymbol{x}}|^{2}right]=Eleft[left|sum_{i=m}^{N-1} y(i) boldsymbol{a}_{i}right|^{2}right]tag{PCA.6}
E[∥x−x^∥2]=E⎣⎡∥∥∥∥∥i=m∑N−1y(i)ai∥∥∥∥∥2⎦⎤(PCA.6)
Our goal now is to choose the eigenvectors that result in the minimum MSE. From
(
P
C
A
.
6
)
(PCA.6)
(PCA.6) and taking into account the orthonormality property of the eigenvectors, we have
E
[
∥
∑
i
=
m
N
−
1
y
(
i
)
a
i
∥
2
]
=
E
[
∑
i
∑
j
(
y
(
i
)
a
i
T
)
(
y
(
j
)
a
j
)
]
=
∑
i
=
m
N
−
1
E
[
y
2
(
i
)
]
=
∑
i
=
m
N
−
1
a
i
T
E
[
x
x
T
]
a
i
(PCA.7)
begin{aligned} Eleft[left|sum_{i=m}^{N-1} y(i) boldsymbol{a}_{i}right|^{2}right] &=Eleft[sum_{i} sum_{j}left(y(i) boldsymbol{a}_{i}^{T}right)left(y(j) boldsymbol{a}_{j}right)right] \ &=sum_{i=m}^{N-1} Eleft[y^{2}(i)right]=sum_{i=m}^{N-1} boldsymbol{a}_{i}^{T} Eleft[boldsymbol{x} boldsymbol{x}^{T}right] boldsymbol{a}_{i} end{aligned}tag{PCA.7}
E⎣⎡∥∥∥∥∥i=m∑N−1y(i)ai∥∥∥∥∥2⎦⎤=E[i∑j∑(y(i)aiT)(y(j)aj)]=i=m∑N−1E[y2(i)]=i=m∑N−1aiTE[xxT]ai(PCA.7)
Using the eigenvector definition, we finally get
E
[
∥
x
−
x
^
∥
2
]
=
∑
i
=
m
N
−
1
a
i
T
λ
i
a
i
=
∑
i
=
m
N
−
1
λ
i
(PCA.8)
Eleft[|boldsymbol{x}-hat{boldsymbol{x}}|^{2}right]=sum_{i=m}^{N-1} boldsymbol{a}_{i}^{T} lambda_{i} boldsymbol{a}_{i}=sum_{i=m}^{N-1} lambda_{i}tag{PCA.8}
E[∥x−x^∥2]=i=m∑N−1aiTλiai=i=m∑N−1λi(PCA.8)
Thus, if we choose in
(
P
C
A
.
5
)
(PCA.5)
(PCA.5) the eigenvectors corresponding to the
m
m
m largest eigenvalues of the correlation matrix, then the error in
(
P
C
A
.
8
)
(PCA.8)
(PCA.8) is minimized, being the sum of the
N
−
m
N-m
N−m smallest eigenvalues.
Total Variance
Since
∑
i
=
m
N
−
1
σ
y
(
i
)
2
=
∑
i
=
m
N
−
1
E
[
y
2
(
i
)
]
=
∑
i
=
m
N
−
1
a
i
T
E
[
x
x
T
]
a
i
=
∑
i
=
m
N
−
1
a
i
T
λ
i
a
i
=
∑
i
=
m
N
−
1
λ
i
(PCA.9)
sum_{i=m}^{N-1} sigma _{y(i)}^2=sum_{i=m}^{N-1} Eleft[y^{2}(i)right]=sum_{i=m}^{N-1} boldsymbol{a}_{i}^{T} Eleft[boldsymbol{x} boldsymbol{x}^{T}right] boldsymbol{a}_{i}=sum_{i=m}^{N-1} boldsymbol{a}_{i}^{T} lambda_{i} boldsymbol{a}_{i}=sum_{i=m}^{N-1} lambda_{i}tag{PCA.9}
i=m∑N−1σy(i)2=i=m∑N−1E[y2(i)]=i=m∑N−1aiTE[xxT]ai=i=m∑N−1aiTλiai=i=m∑N−1λi(PCA.9)
we can see that the selected
m
m
m features retain most of the total variance associated with the original random variables
x
(
i
)
x(i)
x(i).
Nonlinear-Kernel PCA (6.7.1)
As its name suggests, this is a kernelized version of the classical PCA. Given the data set
X
mathbf X
X, we make an implicit mapping into a reproducing kernel Hilbert space
H
H
H,
x
∈
X
↦
ϕ
(
x
)
∈
H
mathbf xin mathbf X mapsto boldsymbol phi(mathbf x)in H
x∈X↦ϕ(x)∈H
Let
x
i
,
i
=
1
,
2.
⋯
,
n
mathbf x_i,i=1,2.cdots,n
xi,i=1,2.⋯,n, be the available training points. We will work with an estimate of the correlation matrix in
H
H
H obtained as an average over the known sample points
R
=
1
n
∑
i
=
1
n
ϕ
(
x
i
)
ϕ
(
x
i
)
T
(KPCA.1)
mathbf R=frac{1}{n}sum_{i=1}^n boldsymbol phi(mathbf x_i) boldsymbol phi(mathbf x_i)^Ttag{KPCA.1}
R=n1i=1∑nϕ(xi)ϕ(xi)T(KPCA.1)
As in PCA, performing the eigendecomposition of
R
mathbf R
R, that is
R
v
=
λ
v
(KPCA.2)
mathbf Rmathbf v=lambda mathbf vtag{KPCA.2}
Rv=λv(KPCA.2)
By the definition of
R
mathbf R
R, it can be shown that
v
mathbf v
v lies in the span of
{
ϕ
(
x
1
)
,
ϕ
(
x
2
)
,
⋯
,
ϕ
(
x
n
)
}
{ boldsymbol phi(mathbf x_1), boldsymbol phi(mathbf x_2),cdots, boldsymbol phi(mathbf x_n)}
{ϕ(x1),ϕ(x2),⋯,ϕ(xn)}. Indeed,
λ
v
=
(
1
n
∑
i
=
1
n
ϕ
(
x
i
)
ϕ
(
x
i
)
T
)
v
=
1
n
∑
i
=
1
n
(
ϕ
(
x
i
)
T
v
)
ϕ
(
x
i
)
lambda mathbf v=left(frac{1}{n}sum_{i=1}^n boldsymbol phi(mathbf x_i) boldsymbol phi(mathbf x_i)^Tright)mathbf v=frac{1}{n}sum_{i=1}^n left(boldsymbol phi(mathbf x_i)^Tmathbf vright)boldsymbol phi(mathbf x_i)
λv=(n1i=1∑nϕ(xi)ϕ(xi)T)v=n1i=1∑n(ϕ(xi)Tv)ϕ(xi)
and for
λ
≠
0
lambdane 0
λ=0 we can write
v
=
∑
i
=
1
n
a
(
i
)
ϕ
(
x
i
)
(KPCA.3)
mathbf v=sum_{i=1}^n a(i)boldsymbol phi(mathbf x_i) tag{KPCA.3}
v=i=1∑na(i)ϕ(xi)(KPCA.3)
Denote
K
(
i
,
j
)
=
K
(
x
i
,
x
j
)
=
ϕ
(
x
i
)
T
ϕ
(
x
j
)
(KPCA.4)
mathcal K(i,j)=K(mathbf x_i,mathbf x_j)=boldsymbol phi(mathbf x_i)^T boldsymbol phi(mathbf x_j)tag{KPCA.4}
K(i,j)=K(xi,xj)=ϕ(xi)Tϕ(xj)(KPCA.4)
where
K
(
⋅
,
⋅
)
K(cdot,cdot)
K(⋅,⋅) being the adopted kernel function, and
K
mathcal K
K is the Gram matrix.
From
(
K
P
C
A
.
1
)
,
(
K
P
C
A
.
2
)
(KPCA.1),(KPCA.2)
(KPCA.1),(KPCA.2) and
(
K
P
C
A
.
3
)
(KPCA.3)
(KPCA.3), we have
1
n
[
ϕ
(
x
1
)
⋯
ϕ
(
x
n
)
]
[
ϕ
(
x
1
)
T
⋮
ϕ
(
x
n
)
T
]
[
ϕ
(
x
1
)
⋯
ϕ
(
x
n
)
]
a
=
λ
[
ϕ
(
x
1
)
⋯
ϕ
(
x
n
)
]
a
frac{1}{n}[boldsymbol phi(mathbf x_1)~cdots~boldsymbol phi(mathbf x_n)]left[begin{matrix}boldsymbol phi(mathbf x_1)^T\vdots\ boldsymbol phi(mathbf x_n)^T end{matrix}right][boldsymbol phi(mathbf x_1)~cdots~boldsymbol phi(mathbf x_n)]mathbf a=lambda [boldsymbol phi(mathbf x_1)~cdots~boldsymbol phi(mathbf x_n)] mathbf a
n1[ϕ(x1) ⋯ ϕ(xn)]⎣⎢⎡ϕ(x1)T⋮ϕ(xn)T⎦⎥⎤[ϕ(x1) ⋯ ϕ(xn)]a=λ[ϕ(x1) ⋯ ϕ(xn)]a
which can be satisfied if
K
a
=
n
λ
a
(KPCA.5)
mathcal Kmathbf a=nlambdamathbf atag{KPCA.5}
Ka=nλa(KPCA.5)
Thus, the
k
k
k-th eigenvector of
R
mathbf R
R, corresponding to the
k
k
k-th (nonzero) eigenvector of
K
mathcal{K}
K is expressed as
v
k
=
∑
i
=
1
n
a
k
(
i
)
ϕ
(
x
i
)
,
k
=
1
,
2
,
…
,
p
(KPCA.6)
boldsymbol{v}_{k}=sum_{i=1}^{n} a_{k}(i) boldsymbolphileft(boldsymbol{x}_{i}right), {k}=1,2, ldots, ptag{KPCA.6}
vk=i=1∑nak(i)ϕ(xi),k=1,2,…,p(KPCA.6)
where
λ
1
≥
λ
2
≥
…
≥
λ
p
lambda_{1} geq lambda_{2} geq ldots geq lambda_{p}
λ1≥λ2≥…≥λp denote the respective eigenvalues in descending order and
λ
p
lambda_{p}
λp is the smallest nonzero one and
a
k
T
≡
[
a
k
(
1
)
,
…
,
a
k
(
n
)
]
mathbf a_{k}^{T} equivleft[a_{k}(1), ldots, a_{k}(n)right]
akT≡[ak(1),…,ak(n)] is the
k
k
k-th eigenvector of the Gram matrix. The latter is assumed to be normalized so that
⟨
v
k
,
v
k
⟩
=
1
,
k
=
1
,
2
,
…
,
p
,
leftlanglemathbf v_{k}, mathbf v_{k}rightrangle=1, k=1,2, ldots, p,
⟨vk,vk⟩=1,k=1,2,…,p, where
⟨
⋅
,
⋅
⟩
langlecdot, cdotrangle
⟨⋅,⋅⟩ is the dot product in the Hilbert space
H
.
H .
H. This imposes an equivalent normalization on the respective
a
k
mathbf a_{k}
ak 's, resulting from
1
=
⟨
v
k
,
v
k
⟩
=
⟨
∑
i
=
1
n
a
k
(
i
)
ϕ
(
x
i
)
,
∑
j
=
1
n
a
k
(
j
)
ϕ
(
x
j
)
⟩
=
∑
i
=
1
n
∑
j
=
1
n
a
k
(
i
)
a
k
(
j
)
K
(
i
,
j
)
=
a
k
T
K
a
k
=
n
λ
k
a
k
T
a
k
,
k
=
1
,
2
,
…
,
p
(KPCA.7)
begin{aligned} 1=leftlangle mathbf v_{k}, mathbf v_{k}rightrangle &=leftlanglesum_{i=1}^{n} mathbf a_{k}(i)boldsymbol phileft(x_{i}right), sum_{j=1}^{n}mathbf a_{k}(j) boldsymbolphileft(x_{j}right)rightrangle \ &=sum_{i=1}^{n} sum_{j=1}^{n}mathbf a_{k}(i) mathbf a_{k}(j) mathcal{K}(i, j) \ &=mathbf a_{k}^{T} mathcal{K} mathbf a_{k}=n lambda_{k}mathbf a_{k}^{T}mathbf a_{k}, quad k=1,2, ldots, p end{aligned}tag{KPCA.7}
1=⟨vk,vk⟩=⟨i=1∑nak(i)ϕ(xi),j=1∑nak(j)ϕ(xj)⟩=i=1∑nj=1∑nak(i)ak(j)K(i,j)=akTKak=nλkakTak,k=1,2,…,p(KPCA.7)
We are now ready to summarize the basic steps for performing a kernel PCA. Given a vector
x
∈
R
N
mathbf x in mathcal{R}^{N}
x∈RN and a kernel function
K
(
⋅
,
⋅
)
K(cdot, cdot)
K(⋅,⋅):
- Compute the Gram matrix K ( i , j ) = K ( x i , x j ) , i , j = 1 , 2 , … , n mathcal{K}(i, j)=Kleft(boldsymbol{x}_{i}, boldsymbol{x}_{j}right), i, j=1,2, ldots, n K(i,j)=K(xi,xj),i,j=1,2,…,n
- Compute the m m m dominant eigenvalues/eigenvectors λ k , a k , k = 1 , 2 , … , m lambda_{k}, boldsymbol{a}_{k}, k=1,2, ldots, m λk,ak,k=1,2,…,m of K mathcal{K} K (Eq. ( K P C A . 5 ) (KPCA.5) (KPCA.5)).
- Perform the required normalization (Eq. ( K P C A . 7 ) (KPCA.7) (KPCA.7)).
- Compute the m m m projections onto each one of the dominant eigenvectors,
y ( k ) ≡ ⟨ v k , ϕ ( x ) ⟩ = ∑ i = 1 n a k ( i ) K ( x i , x ) , k = 1 , 2 , … , m (KPCA.8) mathbf y(k) equivleftlanglemathbf v_{k}, boldsymbolphi(mathbf x)rightrangle=sum_{i=1}^{n} mathbf a_{k}(i) Kleft(mathbf x_{i}, mathbf xright), k=1,2, ldots, mtag{KPCA.8} y(k)≡⟨vk,ϕ(x)⟩=i=1∑nak(i)K(xi,x),k=1,2,…,m(KPCA.8)
The operations given in ( K P C A . 8 ) (KPCA.8) (KPCA.8) correspond to a nonlinear mapping in the input space. Note that, in contrast to the linear PCA, the dominant eigenvectors v k , k = 1 , 2 , … , m v_{k}, k=1,2, ldots, m vk,k=1,2,…,m, are not computed explicitly.
最后
以上就是鳗鱼小懒猪最近收集整理的关于Feature Selection and Extraction的全部内容,更多相关Feature内容请搜索靠谱客的其他文章。








发表评论 取消回复