絮叨两句:
博主是一名数据分析实习生,利用博客记录自己所学的知识,也希望能帮助到正在学习的同学们
人的一生中会遇到各种各样的困难和折磨,逃避是解决不了问题的,唯有以乐观的精神去迎接生活的挑战
少年易老学难成,一寸光阴不可轻。
最喜欢的一句话:今日事,今日毕
机器学习面试题
- 为什么需要对数值类型的特征做归一化?
- 类别型特征如何处理的?
- 距离/相似度如何计算?
- 欧几里得距离(Eucledian Distance)
- 曼哈顿距离(Manhattan Distance)
- 明可夫斯基距离(Minkowski distance)
- 余弦相似度(Cosine Similarity)
- 杰卡德相似系数Jaccard Similarity
- 皮尔森相关系数(Pearson Correlation Coefficient)
- K-Means算法的缺陷和优点是什么?
- K-Means算法的应用场景
- K-Means算法如何确定K值?
- 肘部法则
- 轮廓系数--计算量太大
- K-Means算法实现-伪代码
- 还有哪些其他的聚类算法?
- K近邻法(Knn)与k-Means的区别?
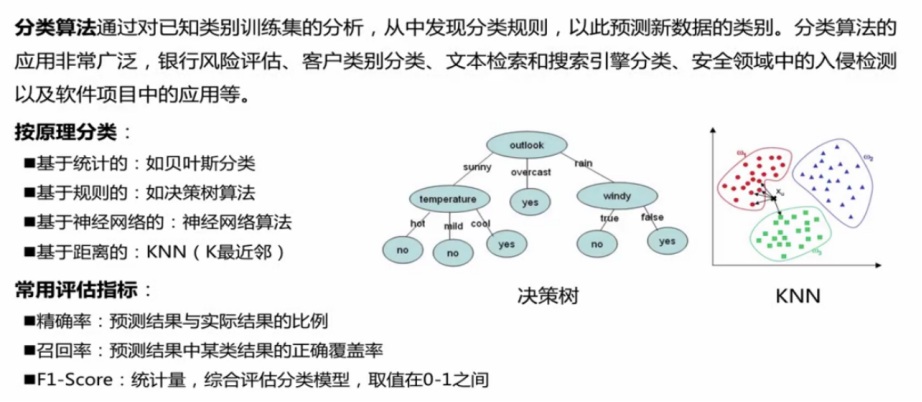
- 有哪些分类算法?
- 信息熵 条件熵 信息增益 信息增益比 GINI系数
- 个人总结
- 数据(Data)
- 信息(Information)
- 信息量(Quantity Of Information)
- 香农公式(Shannon Formula)
- 信息熵(Information Entropy)
- 信息增益(Information Gain)
- 信息增益做特征选择的优缺点
- 信息增益比(Infomation Gain Ratio)
- 基尼系数(Gini Coefficient )
- ID3、C4.5、CART三种决策树的区别
- ID3决策树
- C4.5决策树
- CART决策树
- 前剪枝后减枝
- 决策树和随机森林
- 过拟合与欠拟合
- 分类算法有哪些评估指标?
- ACC、ROC、AUC是什么?
- T、F、P、N、R
- TPR/FPR/ACC
- 案例计算
- 随机算法
- ROC曲线
- AUC
- 最后的结论:
为什么需要对数值类型的特征做归一化?
-
简单理解

-
有哪些归一化方式

-
深入理解为什么要归一化

类别型特征如何处理的?


距离/相似度如何计算?
在数据分析和数据挖掘以及搜索引擎中,我们经常需要知道个体间差异的大小,进而评价个体的相似性和类别。
常见的比如数据分析中比如相关分析,数据挖掘中的分类聚类(K-Means等)算法,搜索引擎进行物品推荐时。
相似度就是比较两个事物的相似性。
一般通过计算事物的特征之间的距离,如果距离小,那么相似度大;
如果距离大,那么相似度小。比如两种水果,将从颜色,大小,维生素含量等特征进行比较相似性。
问题定义:有两个对象X,Y,都包含N维特征,
X=(x1,x2,x3,………,xn)
Y=(y1,y2,y3,………,yn)
计算X和Y的相似性。常用的有五种方法,如下:
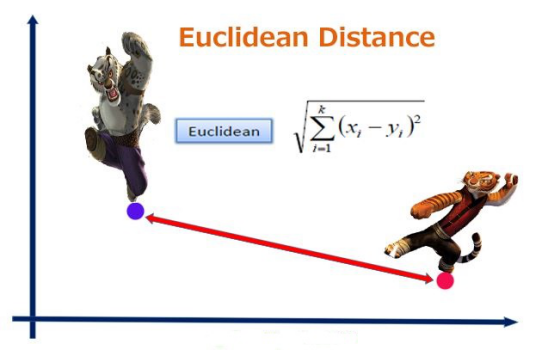
欧几里得距离(Eucledian Distance)
欧氏距离是最常用的距离计算公式,衡量的是多维空间中各个点之间的绝对距离,当数据很稠密并且连续时,这是一种很好的计算方式。
因为计算是基于各维度特征的绝对数值,所以欧氏度量需要保证各维度指标在相同的刻度级别,比如对身高(cm)和体重(kg)两个单位不同的指标使用欧式距离可能使结果失效。
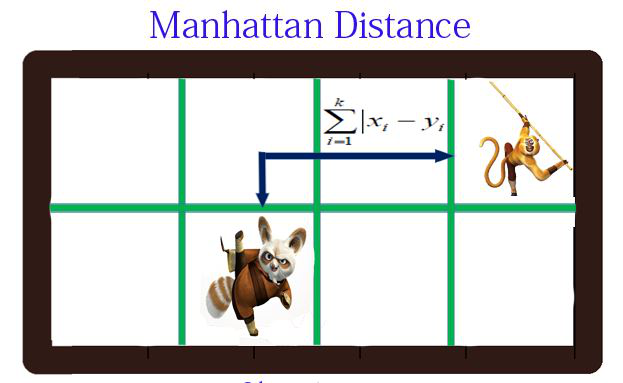
曼哈顿距离(Manhattan Distance)
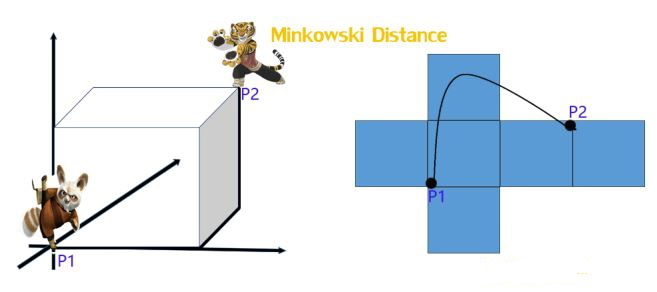
明可夫斯基距离(Minkowski distance)
明氏距离是欧氏距离的推广,是对多个距离度量公式的概括性的表述,看看下图
公式:
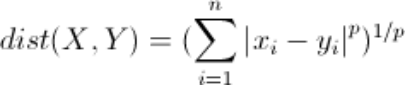
从公式我们可以看出,
- 当p==1,“明可夫斯基距离”变成“曼哈顿距离”
- 当p==2,“明可夫斯基距离”变成“欧几里得距离”
- 当p==∞,“明可夫斯基距离”变成“切比雪夫距离”
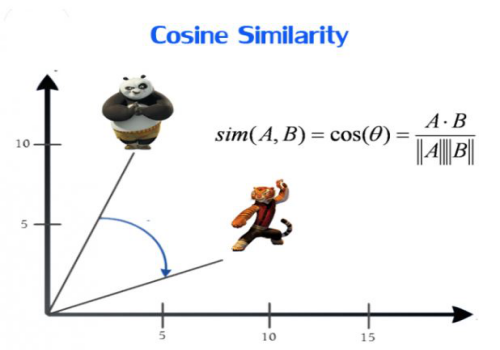
余弦相似度(Cosine Similarity)
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
杰卡德相似系数Jaccard Similarity
Jaccard系数主要用于计算符号度量或布尔值度量的个体间的相似度,因为个体的特征属性都是由符号度量或者布尔值标识,因此无法衡量差异具 体值的大小,只能获得“是否相同”这个结果,所以Jaccard系数只关心个体间共同具有的特征是否一致这个问题。

对于上面两个对象A和B,我们用Jaccard计算它的相似性,公式如下
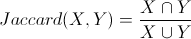
首先计算出A和B的交(A ∩ B),以及A和B的并 (A ∪ B):
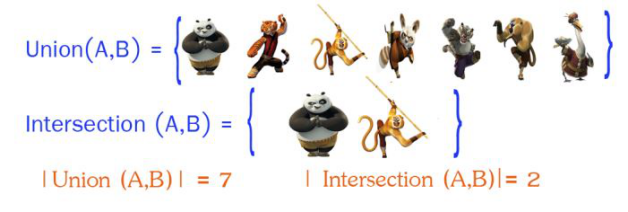
然后利用公式进行计算:

皮尔森相关系数(Pearson Correlation Coefficient)
又称相关相似性,通过Peason相关系数来度量两个用户的相似性。计算时,首先找到两个用户共同评分过的项目集,然后计算这两个向量的相关系数。
公式:
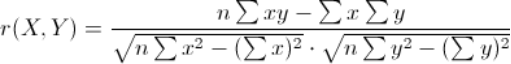
K-Means算法的缺陷和优点是什么?
优点:
- 解决聚类问题的经典算法,简单、快速
- 当处理大数据集时,该算法保持可伸缩性和高效率
- 当簇近似为高斯分布时,它的效果较好
- 时间复杂度近于线性,适合挖掘大规模数据集
缺点: - 必须事先给出k(一般刚开始难以估计)
- 对初值敏感,即对于不同的初值,可能会导致不同结果
- 不适合非凸形状的簇或者大小差别很大的簇
- 对噪声和孤立点敏感
K-Means算法的应用场景

K-means十大应用案例
K-means算法通常可以应用于维数、数值都很小且连续的数据集,比如:从随机分布的事物集合中将相同事物进行分组。
- 文档分类器
根据标签、主题和文档内容将文档分为多个不同的类别。这是一个非常标准且经典的K-means算法分类问题。首先,需要对文档进行初始化处理,将每个文档都用矢量来表示,并使用术语频率来识别常用术语进行文档分类,这一步很有必要。然后对文档向量进行聚类,识别文档组中的相似性。 这里是用于文档分类的K-means算法实现案例。
- 物品传输优化
使用K-means算法的组合找到无人机最佳发射位置和遗传算法来解决旅行商的行车路线问题,优化无人机物品传输过程。这是该项目的白皮书。
- 识别犯罪地点
使用城市中特定地区的相关犯罪数据,分析犯罪类别、犯罪地点以及两者之间的关联,可以对城市或区域中容易犯罪的地区做高质量的勘察。这是基于德里飞行情报区犯罪数据的论文。
- 客户分类
聚类能过帮助营销人员改善他们的客户群(在其目标区域内工作),并根据客户的购买历史、兴趣或活动监控来对客户类别做进一步细分。这是关于电信运营商如何将预付费客户分为充值模式、发送短信和浏览网站几个类别的白皮书。对客户进行分类有助于公司针对特定客户群制定特定的广告。
- 球队状态分析
分析球员的状态一直都是体育界的一个关键要素。随着竞争越来愈激烈,机器学习在这个领域也扮演着至关重要的角色。如果你想创建一个优秀的队伍并且喜欢根据球员状态来识别类似的球员,那么K-means算法是一个很好的选择。具体细节和实现请参照这篇文章。
- 保险欺诈检测
机器学习在欺诈检测中也扮演着一个至关重要的角色,在汽车、医疗保险和保险欺诈检测领域中广泛应用。利用以往欺诈性索赔的历史数据,根据它和欺诈性模式聚类的相似性来识别新的索赔。由于保险欺诈可能会对公司造成数百万美元的损失,因此欺诈检测对公司来说至关重要。这是汽车保险中使用聚类来检测欺诈的白皮书。
- 乘车数据分析
面向大众公开的Uber乘车信息的数据集,为我们提供了大量关于交通、运输时间、高峰乘车地点等有价值的数据集。分析这些数据不仅对Uber大有好处,而且有助于我们对城市的交通模式进行深入的了解,来帮助我们做城市未来规划。这是一篇使用单个样本数据集来分析Uber数据过程的文章。
- 网络分析犯罪分子
网络分析是从个人和团体中收集数据来识别二者之间的重要关系的过程。网络分析源自于犯罪档案,该档案提供了调查部门的信息,以对犯罪现场的罪犯进行分类。这是一篇在学术环境中,如何根据用户数据偏好对网络用户进行 cyber-profile的论文。
- 呼叫记录详细分析
通话详细记录(CDR)是电信公司在对用户的通话、短信和网络活动信息的收集。将通话详细记录与客户个人资料结合在一起,这能够帮助电信公司对客户需求做更多的预测。在这篇文章中,你将了解如何使用无监督K-Means聚类算法对客户一天24小时的活动进行聚类,来了解客户数小时内的使用情况。
- IT警报的自动化聚类
大型企业IT基础架构技术组件(如网络,存储或数据库)会生成大量的警报消息。由于警报消息可以指向具体的操作,因此必须对警报信息进行手动筛选,确保后续过程的优先级。对数据进行聚类可以对警报类别和平均修复时间做深入了解,有助于对未来故障进行预测。
K-Means算法如何确定K值?
肘部法则
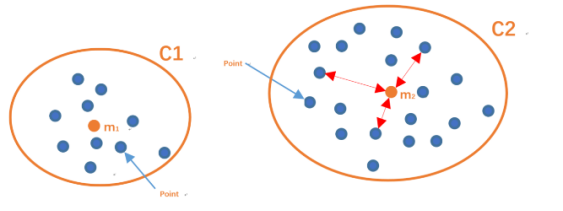
- SSE
手肘法的核心指标是
集合内误差平方和:Within Set Sum of Squared Error, WSSSE
或者叫SSE(sum of the squared errors,误差平方和),公式为
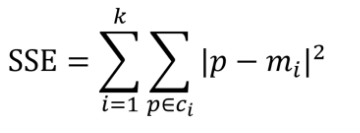
- 解释
Ci是第i个簇
p是Ci中的样本点
mi是Ci的质心(Ci中所有样本的均值)
SSE是所有样本的聚类误差,代表了聚类效果的好坏。 - SSE 变化图
根据 SSE 的变化画图, 找到拐点
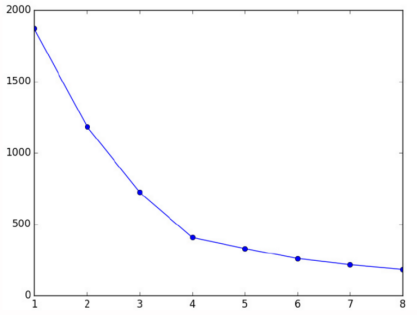
随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。
当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系如图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数
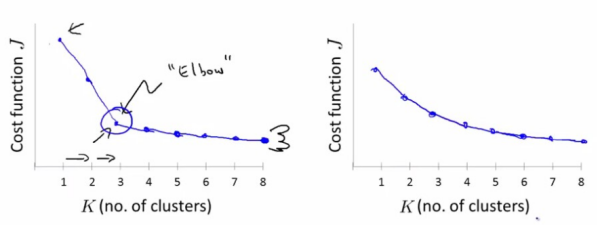
显然,肘部对于的k值为3(曲率最高),故对于这个数据集的聚类而言,最佳聚类数应该选3。
轮廓系数–计算量太大
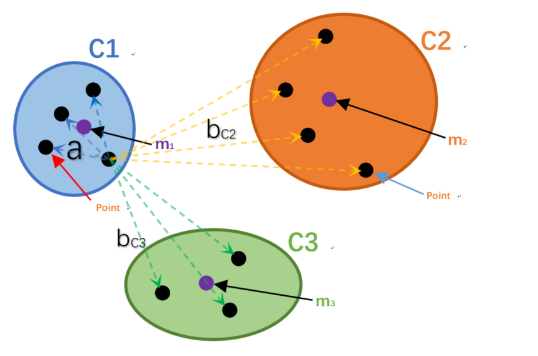
a表示C1簇中的某一个样本点Xi到自身簇中其他样本点的距离总和的平均值。
bC2表示样本点Xi 到C2簇中所有样本点的距离总和的平均值。
bC3表示样本点Xi 到C3簇中所有样本点的距离总和的平均值。
定义b = min(bC2 ,bC3)
-
簇内不相似度:样本和簇内其它样本之间的平均距离
样本i的簇内不相似度a(i)表示C中样本和簇内其它样本之间的平均距离
a(i)越小,说明样本i越应该被聚类到该簇 -
簇外不相似度:样本和簇外其它样本之间的平均距离最小值
样本i的簇外不相似度:b(i) = min { bi1, bi2, bi3 }
bi越大,说明样本i越不属于其他簇 -
计算公式
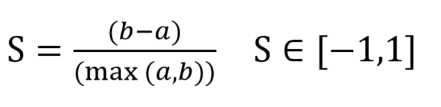
-
解释
a:样本Xi到同一簇内其他点不相似程度的平均值
b:样本Xi到其他簇的平均不相似程度的最小值 -
S范围在[-1,1]之间。该值越大,越合理
-
s(i) 接近 1, 说明样本 i 聚类合理
-
s(i) 接近 -1, 则说明样本 i 更应该分类到另外的簇
-
若 s(i) 近似为 0, 则说明样本 i 在两个簇的边界上
-
轮廓系数
所有样本的s(i)的均值称为聚类结果的轮廓系数,是该聚类是否合理的有效度量。
使用轮廓系数(silhouette coefficient)来确定k,即选择使系数较大所对应的k值
K-Means算法实现-伪代码
基于Java实现K-means算法

还有哪些其他的聚类算法?
除了k-means 算法以外,聚类算法还有很多,其中“层次聚类算法”较为有名。与k-means 算法不同,层次聚类算法不需要事先设定K簇的数量。
在层次聚类算法中,一开始每个数据都自成一类。也就是说,有n 个数据就会形成n 个簇。
然后重复执行“将距离最近的两个簇合并为一个”的操作n -1 次。
每执行1 次,簇就会减少1 个。执行n -1 次后,所有数据就都被分到了一个簇中。在这个过程中,每个阶段的簇的数量都不同,对应的聚类结果也不同。
只要选择其中最为合理的1 个结果就好。
合并簇的时候,为了找出“距离最近的两个簇”,需要先对簇之间的距离进行定义。
根据定义方法不同,会有“最短距离法”“最长距离法”“中间距离法”等多种算法。
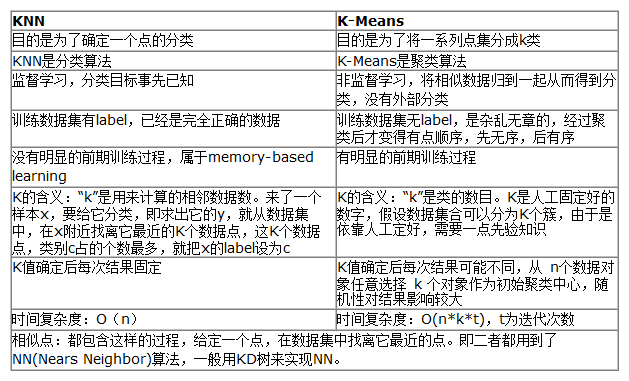
K近邻法(Knn)与k-Means的区别?
初学者会很容易就把K-Means和KNN搞混,其实两者的差别还是很大的
有哪些分类算法?
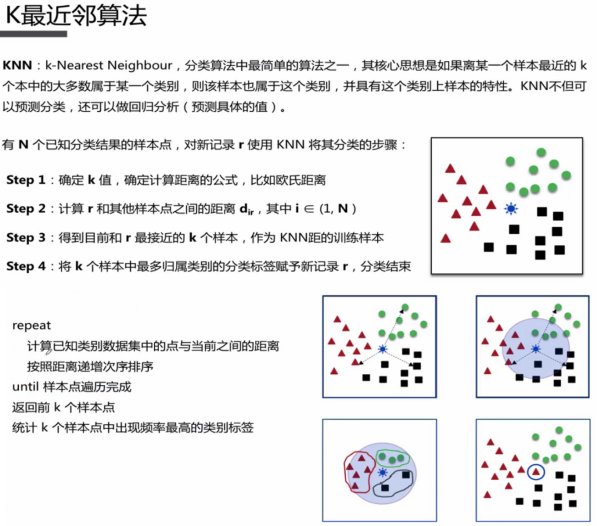

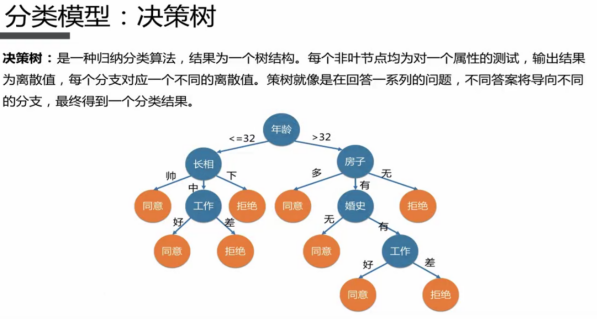


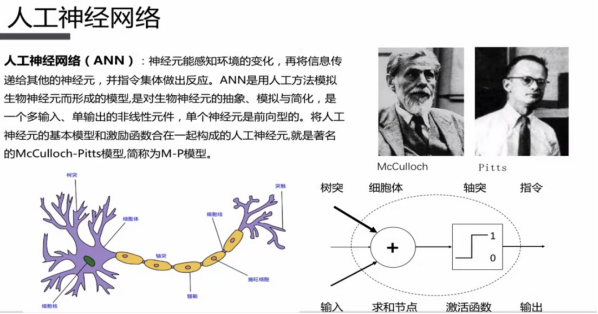


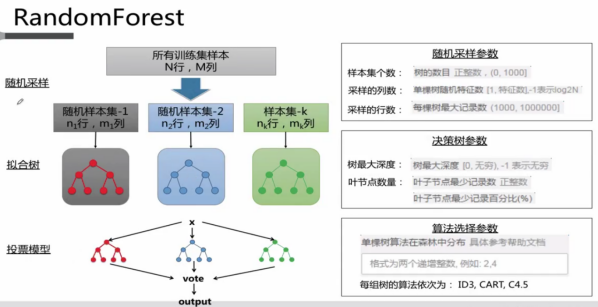
信息熵 条件熵 信息增益 信息增益比 GINI系数
在信息论与概率统计学中,熵(entropy)是一个很重要的概念。在机器学习与特征工程中,熵的概念也用得非常多。
个人总结
以下内容是个人总结看看就行
数据(Data)

信息(Information)


信息量(Quantity Of Information)



香农公式(Shannon Formula)

信息熵(Information Entropy)
熵是什么?信息论的开山祖师爷Shannon 明确告诉我们,信息的不确定性可以用熵来表示,即信息熵是信息杂乱程度的描述:
对于一个取有限个值的随机变量X,如果其概率分布为:
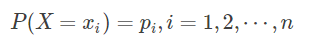
那么随机变量X的熵可以用以下公式描述:
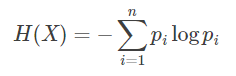
每次看到这个式子,都会从心底里感叹数学的伟大与奇妙。
在这之前,信息这东东对于人们来说,是个看着好像挺清晰实际还是很模糊的概念。Shannon用最简洁美妙的方式,告诉了整个世界信息到底应该怎么去衡量去计算。
今天每个互联网人都知道,这个衡量的标准就是bit。
正是由于bit的出现,才引领了我们今天信息时代的到来。
所以即使把Shannon跟世界上最伟大的那些科学家相提并论,我觉得也丝毫不为过。
举个例子,如果一个分类系统中,类别的标识是cc,取值情况是c1,c2,cn,n为类别的总数。那么此分类系统的熵为:
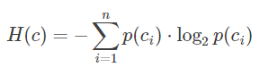
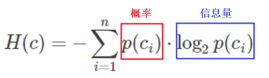
更特别一点,如果是个二分类系统,那么此系统的熵为:
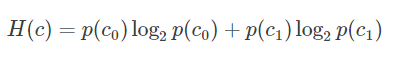
其中p(c0)、p(c1)分别为正负样本出现的概率。





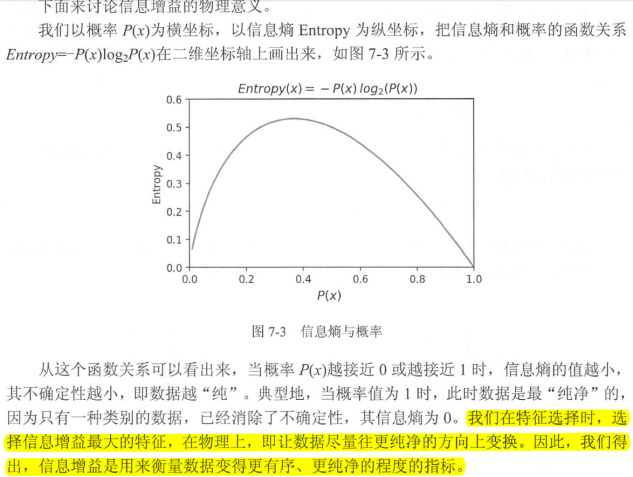
信息增益(Information Gain)
信息增益做特征选择的优缺点
先来说说优点:
- 信息增益考虑了特征出现与不出现的两种情况,比较全面,一般而言效果不错。
- 使用了所有样例的统计属性,减小了对噪声的敏感度。
- 容易理解,计算简单。
主要的缺陷:
- 信息增益考察的是特征对整个系统的贡献,没有到具体的类别上,所以一般只能用来做全局的特征选择,而没法针对单个类别做特征选择。
- 只能处理连续型的属性值,没法处理连续值的特征。
- 算法天生偏向选择分支多的属性,容易导致overfitting。
信息增益比(Infomation Gain Ratio)
前面提到,信息增益的一个大问题就是偏向选择分支多的属性导致overfitting,那么我们能想到的解决办法自然就是对分支过多的情况进行惩罚(penalty)了。
信息增益比主要用在决策树当中,作用是消除多个取值的特征导致的偏差,因为多值特征的信息增益很大,但泛化性能却很差。比如,使用姓名作为特征可以得到较大的信息增益,因为它基本可以把每个人区分开来,但这种区分对于分类显然没什么帮助。这时就可以用信息增益比来一定程度上消除对多值属性的偏向性,但也不能完全消除。
于是我们有了信息增益比,或者说信息增益率:
特征X的熵:
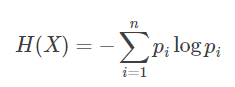
特征X的信息增益 :
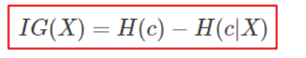
那么信息增益比为:
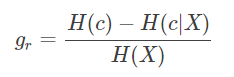
在决策树算法中,ID3使用信息增益,c4.5使用信息增益比。
基尼系数(Gini Coefficient )
https://blog.csdn.net/yeziand01/article/details/80731078

Gini系数是一种与信息熵类似的做特征选择的方式,可以用来衡量数据的不纯度。在CART(Classification and Regression Tree)算法中利用基尼指数构造二叉决策树。
Gini系数的计算方式如下: 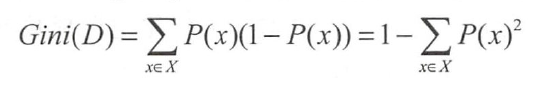
其中,D表示数据集全体样本,pipi表示每种类别出现的概率。取个极端情况,如果数据集中所有的样本都为同一类,那么有p0=1,p0=1,Gini(D)=0,Gini(D)=0,显然此时数据的不纯度最低。 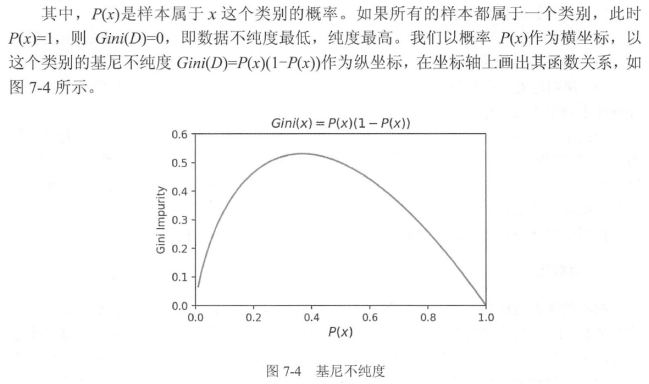
与信息增益类似,我们可以计算如下表达式:
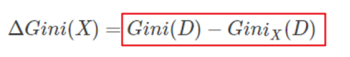
上面式子表述的意思就是,加入特征XX以后,数据不纯度减小的程度。很明显,在做特征选择的时候,我们可以取ΔGini(X),ΔGini(X)最大的那个
ID3、C4.5、CART三种决策树的区别

一棵决策树包含一个根结点、若干个内部结点和若干个叶结点;叶结点对应于决策结果,其他每个结点则对应一个属性测试;每个结点包含的样本结合根据属性测试的结果被划分到子结点中;根结点包含样本全集,从根结点到每个叶结点的每个叶结点的路径对应一个判定测试序列。决策树学习的目的是为了产生一棵泛化能力强,也就是能够处理未见实例的决策树。
ID3决策树
信息熵是度量样本集合纯度最常用的一种指标。假设样本集合D中第k类样本所占的比重为pk,那么信息熵的计算则为下面的计算方式
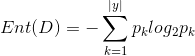
当这个Ent(D)的值越小,说明样本集合D的纯度就越高
有了信息熵,当我选择用样本的某一个属性a来划分样本集合D时,就可以得出用属性a对样本D进行划分所带来的“信息增益”
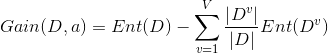
一般来讲,信息增益越大,说明如果用属性a来划分样本集合D,那么纯度会提升,因为我们分别对样本的所有属性计算增益情况,选择最大的来作为决策树的一个结点,或者可以说那些信息增益大的属性往往离根结点越近,因为我们会优先用能区分度大的也就是信息增益大的属性来进行划分。当一个属性已经作为划分的依据,在下面就不在参与竞选了,我们刚才说过根结点代表全部样本,而经过根结点下面属性各个取值后样本又可以按照相应属性值进行划分,并且在当前的样本下利用剩下的属性再次计算信息增益来进一步选择划分的结点,ID3决策树就是这样建立起来的。
C4.5决策树
C4.5决策树的提出完全是为了解决ID3决策树的一个缺点,当一个属性的可取值数目较多时,那么可能在这个属性对应的可取值下的样本只有一个或者是很少个,那么这个时候它的信息增益是非常高的,这个时候纯度很高,ID3决策树会认为这个属性很适合划分,但是较多取值的属性来进行划分带来的问题是它的泛化能力比较弱,不能够对新样本进行有效的预测。
而C4.5决策树则不直接使用信息增益来作为划分样本的主要依据,而提出了另外一个概念,增益率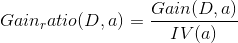
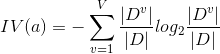
但是同样的这个增益率对可取值数目较少的属性有所偏好,因此C4.5决策树先从候选划分属性中找出信息增益高于平均水平的属性,在从中选择增益率最高的。
CART决策树
CART决策树的全称为Classification and Regression Tree,可以应用于分类和回归。
采用基尼系数来划分属性
基尼值
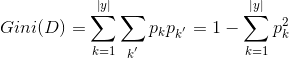
基尼系数
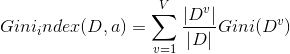
因此在候选属性中选择基尼系数最小的属性作为最优划分属性。
前剪枝后减枝
https://www.cnblogs.com/itboys/p/8312894.html


决策树和随机森林
随机森林在并行处理超大数据集时能提供良好的性能表现.
为了避免决策树的过拟合问题,可以选择了随机森林模型




过拟合与欠拟合

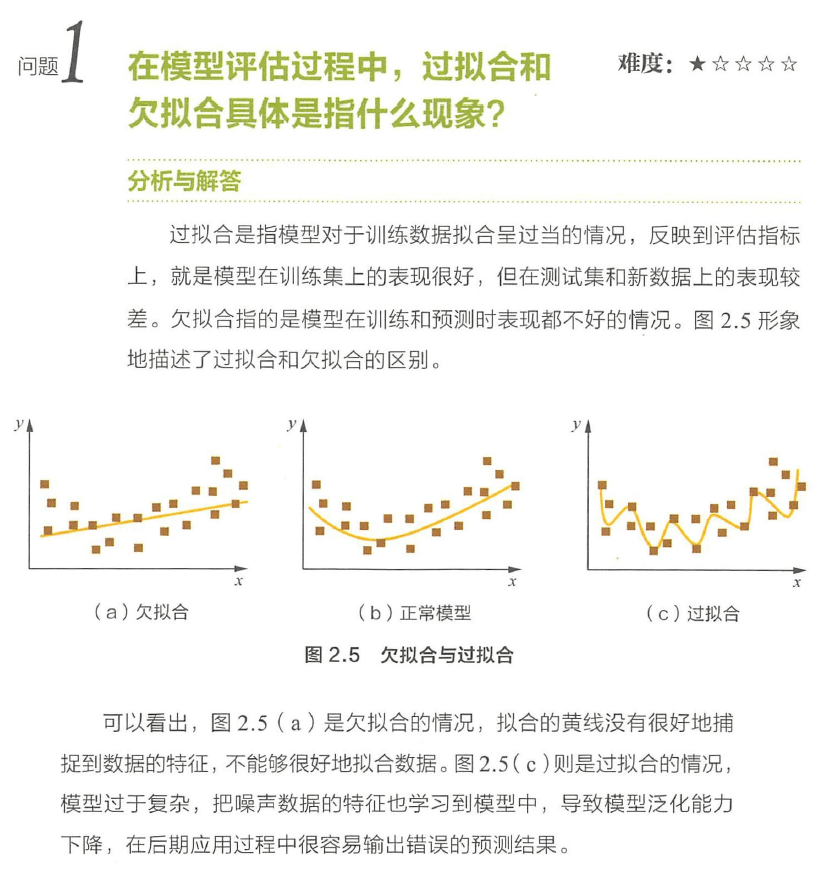

欠拟合(underfitting),也称为高偏差(high bias)
过拟合(overfitting),也称为高方差(high variance)
欠拟合多数情况下是因为选定模型类型太过简单,特征选取不够导致的。而过拟合则相反,可能是模型太过复杂,特征选择不当(过多,或组合不当)造成的。
相应的解法,当然是有针对性的选择更复杂/简单的模型类型;增加/减少特征;或者减小/增大正则项比重等。
分类算法有哪些评估指标?

ACC、ROC、AUC是什么?
https://blog.csdn.net/kMD8d5R/article/details/98552574
https://www.jianshu.com/p/82903edb58dc
https://blog.csdn.net/resourse_sharing/article/details/51496494
T、F、P、N、R
首先我们先了解这四个概念:
T:True,真的
F:False,假的
P:Positive,阳性
N:Negative,阴性
R:Rate,比率,和上面四个没直接关系
比如说看病这个事情:
一个人得病了,但医生检查结果说他没病,那么他是假没病,也叫假阴性(FN)
一个人得病了,医生检查结果也说他有病,那么他是真有病,也叫真阳性(TP)
一个人没得病,医生检查结果却说他有病,那么他是假有病,也叫假阳性(FP)
一个人没得病,医生检查结果也说他没病,那么他是真没病,也叫真阴性(TN)
这四种结局可以画成2 × 2的混淆矩阵: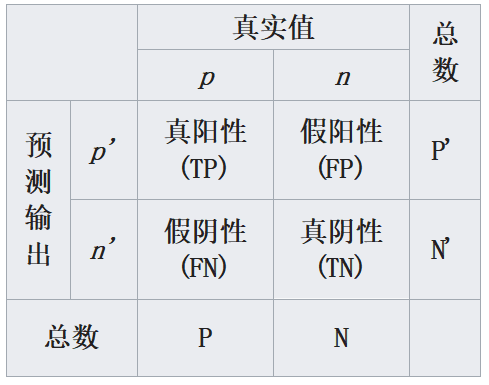
FN、TP、FP、TN可以这样理解:第二个字母(N或P)是医生说的,第一个字母(T或F)是对医生说法的肯定(真没病真阴TN,真有病真阳TP)或否定(假有病假阳FP,假没病假阴FN)。
TPR/FPR/ACC
R是Rate(比率),那么:
查出率/召回率,TPR,真阳率等于真阳数量除以真阳加假阴,就是真的有病并且医生判断也有病的病人数量除以全部真有病的人
(真有病医生也说有病的真阳+真有病医生却说没病的假阴):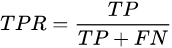
查错率,FPR,假阳率等于假阳数量除以假阳加真阴,就是没病但医生说有病的病人数量除以全部实际没病的人(没病但医生说有病的+没病医生也说没病的):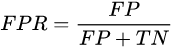
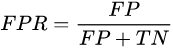
精准度,ACC,Accuracy,精准度,有病被检查出来的TP是检测对了,没病也检测健康的TN也是检测对了,所有检测对的数量除以全部数量就是精准度:
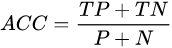
查准率和召回率的定义如下:
由于现在有两个指标一查准率和召回率,如果有一个算法的查准率是0.5 ,召回率是0.4
另外一个算法查准率是0.02 ,召回率是1.0 ; 那么两个算法到底哪个好呢?
为了解决这个问题,我们引入了F1Score 的概念: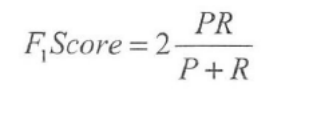
其中P 是查准率, R 是召回率。这样就可以用一个数值直接判断哪个算法性能更好。
典型地,如果查准率或召回率有一个为0 ,那么F1Score 将会为0 。
而理想的情况下,查准率和召回率都为1 , 则算出来的F 1Score 为1
案例计算
假如说我们编写了一个算法M,它能够根据一系列的属性(比如身高、爱好、衣着、饮食习惯等)来预测一个人的性别是男还是女。
然后我们有10个人属性组数据让算法M来预测,这10个人的真实性别和预测结果如下: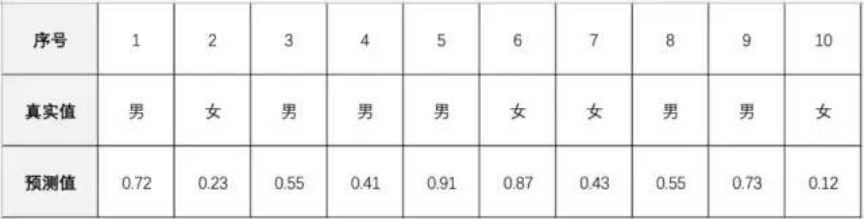
预测值中0代表女性,1代表男性,数字越大越接近男性特征,数字越小越接近女性特征。如果我们设定区分男女的阈值是0.5,那么预测值大于0.5的都是P正向男性,小于0.5都是N负向女性。
那么,真实6个男人中有[1,3,5,8,9]这5个都查出来了,算法M的查出率TPR=5/6=0.833;真实4个女性中6号被查错,所以误检率FPR=1/4=0.25;精度是ACC=(5+3)/10=0.8。
但是注意,如果我们修改阈值等于0.4,那么就会变为6个男人全被检出TPR=1;而女性则被误检2个FPR=0.5;精度仍然是0.8。
得出结论:如果单纯使用ACC评价算法优劣,不靠谱!
还应该结合其他的指标
随机算法

假设我们有一个庸医,根本不懂医术,当病人来检查是否有病的时候,他就随机乱写有病或者没病,结果呢,对于所有真实有病的,庸医也能正确检查出一半,就是TPR=0.5,同样对于没病的也是一半被误检,就是FPR=0.5。这个庸医的“随机诊法”原理上总能得到相等的查出率和误检率,如果我们把FPR当做坐标横轴,TPR当做数轴,那么“随机诊法”对应了[0,0]到[1,1]的那条直线。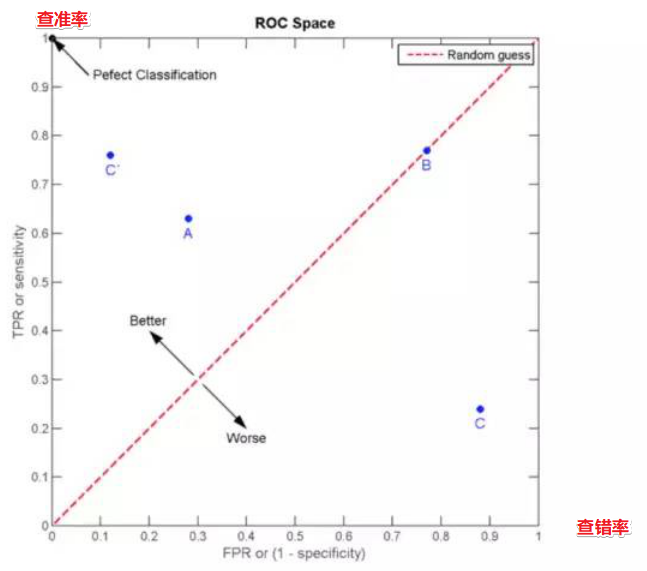
如图所示,越靠近左上角的情况查出率越高,查错率越低,[0,1]点是最完美的状态。而越靠近右下角,算法质量越低。
注意图中右下角C点,这里查错率高,查出率低,属于很糟糕的情况;但是如果我们把C点沿红色斜线对称上去成为C’点,那就很好了。——所以,如果你的算法预测结果总是差的要死,那么可以试试看把它颠倒一下,负负得正,也许就很好了。
ROC曲线
ROC(Receiver Operating Characteristic curve)接受者操作特征曲线。
上面我们都只是把从一组预测样本得到的[FPR,TPR]作为一个点描述,并且我们知道阈值的改变会严重影响FPR和TPR,那么,如果我们把所有可能的阈值都尝试一遍,再把样本集预测结果计算得到的所有[FPR,TPR]点都画在坐标上,就会得到一个曲线: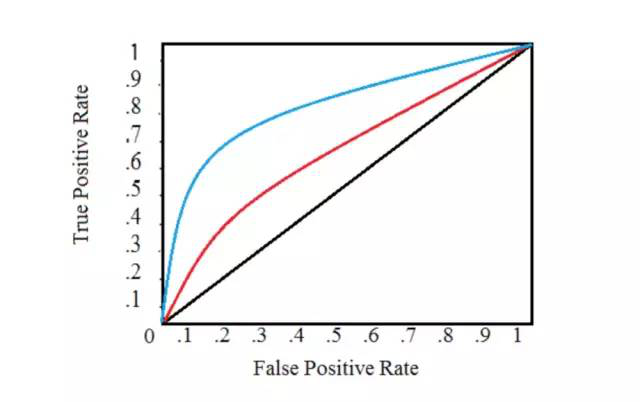
一般阈值范围是在0~1之间,1表示一个分类(男,或者有病),0表示另外一个分类(女,或者无病)。
在这个图中,注意:
横竖都不是阈值坐标轴,这里没有显示阈值。
蓝色线更加靠近左上角,比红色线更好。
ROC曲线上左侧的点好解释,误查率FPR越低,查出率TRP越高,自然是好的;但右上角的怎么解释?误查率和查出率都很高。——想象一下,有个庸医把阈值调的很高比如0.99,那么导致算法推测出来的都是男生,没有女生,这样的情况当然查出率很高(所有男生都查出来了),误查率也很高(所有女#生都被当成男生了)。
AUC
ROC曲线的形状不太好量化比较,于是就有了AUC。
AUC,Area under the Curve of ROC (AUC ROC),就是ROC曲线下面的面积。
如上图,蓝色曲线下面的面积更大,也就是它的AUC更大。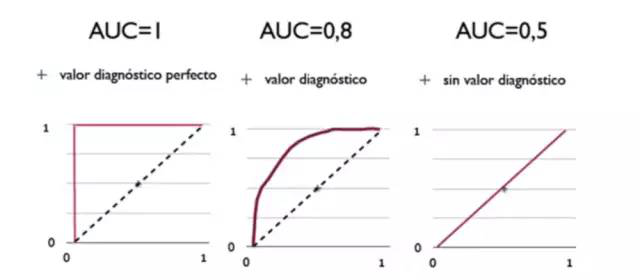
如图,左侧的红色折线覆盖了下面整个方形面积,AUC=1;中间的曲线向左上方凸起,AUC=0.8;右边的是完全随机的结果,占一半面积,AUC=0.5。
AUC面积越大,算法越好。
当我们写好算法之后,可以用一个测试集来让这个算法进行分类预测,然后我们绘制ROC曲线,观察AUC面积,计算ACC精度,用这些来对算法的好坏进行简单评估。
最后的结论:
单纯使用ACC,Accuracy评价分类算法的好坏不靠谱
可以使用F1Score(综合考虑了查准率和召回率)
或者使用ROC(整合考虑了查出率和差错率),但是不好量化,所以使用AUC表示ROC曲线下的面积
所以开发中我们可以F1Score/ROC/AUC
最后
以上就是悦耳天空最近收集整理的关于机器学习相关面试题为什么需要对数值类型的特征做归一化?类别型特征如何处理的?距离/相似度如何计算?K-Means算法的缺陷和优点是什么?K-Means算法的应用场景K-Means算法如何确定K值?K-Means算法实现-伪代码还有哪些其他的聚类算法?K近邻法(Knn)与k-Means的区别?有哪些分类算法?信息熵 条件熵 信息增益 信息增益比 GINI系数ID3、C4.5、CART三种决策树的区别前剪枝后减枝决策树和随机森林过拟合与欠拟合分类算法有哪些评估指标?ACC、ROC、AUC是什么?的全部内容,更多相关机器学习相关面试题为什么需要对数值类型的特征做归一化?类别型特征如何处理的?距离/相似度如何计算?K-Means算法的缺陷和优点是什么?K-Means算法的应用场景K-Means算法如何确定K值?K-Means算法实现-伪代码还有哪些其他的聚类算法?K近邻法(Knn)与k-Means的区别?有哪些分类算法?信息熵内容请搜索靠谱客的其他文章。



![[读书笔记]机器学习:实用案例解析(9)](https://www.shuijiaxian.com/files_image/reation/bcimg4.png)




发表评论 取消回复