准备工作
安装NLTK(Nutural language ToolKit)
pip install -i https://pypi.doubanio.com/simple nltk
进入python交换模式
import nltk
nltk.download('stopwords')
nltk.download('punkt')
新建NewsSummary1.py
from nltk.tokenize import sent_tokenize,word_tokenize
//nltk.tokenize是NLTK提供的分词工具.sent_tokenize是分段为句,word_tokenize是分句为词
from nltk.corpus import stopwords
//stopwords是一个列表包含英文中那些频繁出现的词,如am,is,are
from collections import defaultdict
//defaultdict是一个带有默认值的字典容器
from string import punctuation
//punctuation是一个包含了英文标点和符号的列表
from heapq import nlargest
//nlarges函数可以很快的求出一个容器中最大的n个数
思路解析
基本思想:拥有关键词最多的句子就是最重要的句子.把句子按照关键词数量的多少排序,取前n句,即可汇总成我们的摘要
所有工作可以分为如下步骤:
给文章中出现的单词按照算法计算除重要性
按照句子中单词的重要性算出句子的总分
按照句子的总分给文章中的每个句子排序
取出前n个句子作为摘要
词频统计
首先先统计除每个词在文章中出现的次数,在统计出次数知乎,我们可以知道次数最多的词的出现次数m,我们把每个词出现的次数mi除以m,算出每个词的"重要系数".
//去除常用词,标点,以及频率过高和过低的词
stopwords(set(stopwords.words('english')+list(punctuation)))
max_cut = 0.9
min_cut = 0.1
"""
计算出每个词出现的频率
word_sent 是一个已经分好词的列表
返回一个词典freq[],
freq[w]代表了w出现的频率
"""
def compute_frequencies(word_sent):
"""
defaultdict和普通的dict的区别是他可以设置default值参数是int默认值是0
"""
freq = defaultdict(int)
#统计每个词出现的频率
for s in word_sent:
for word in s:
#注意stopwords
if word not in stopwords:
freq[word]+=1
#得出最高出现频次m
m = float(max(freq.values()))
#所有单词的频次除以m
for w in list(freq.keys()):
freq[w]=freq[w]/m
if freq[w]>=max_cut or freq[w]<=min_cut:
del freq[w]
#最后返回的是
#{key:单词,value:重要性}
return freq
"""
现在单词有了重要性这样一个量化描述的值,我们现在需要统计的是一个句子中单词的重要性,只需要吧句子中每个单词的重要性叠加就行了.
"""
def summarize(text,n):
"""
用来总结的主要函数
text是输入的文本
n是摘要的句子个数
返回包含的摘要列表
"""
#首先把句子分出来
sents = sent_tokenize(text)
assert n <= len(sents)
#然后分词
word_sent = [word_tokenize(s.lower()) for s in sents]
freq = compute_frequencies(word_sent)
#ranking则是句子和句子重要性的词典
ranking = defaultdict(int)
for i,word in enumerate(word_sent):
for w in word:
if w in freq:
ranking[i] +=freq[w]
sents_idx = rank(ranking,n)
return [sents[j] for j in sents_idx]
"""
考虑到句子比较多的情况,用便利的方式找最大的n个数比较慢,我们这里调用headq中的函数,来创建一个最小堆来完成这个功能,返回的是最小的n个数所在的位置
"""
def rank(ranking,n):
return nlargest(n,ranking,key=ranking.get)
if name == 'main':
with open("news.txt","r") as myfile:
text= myfile.read().replace('n')
res = summarize(text,2)
for i in range(len(res)):
print(res[i])
```
结果运行
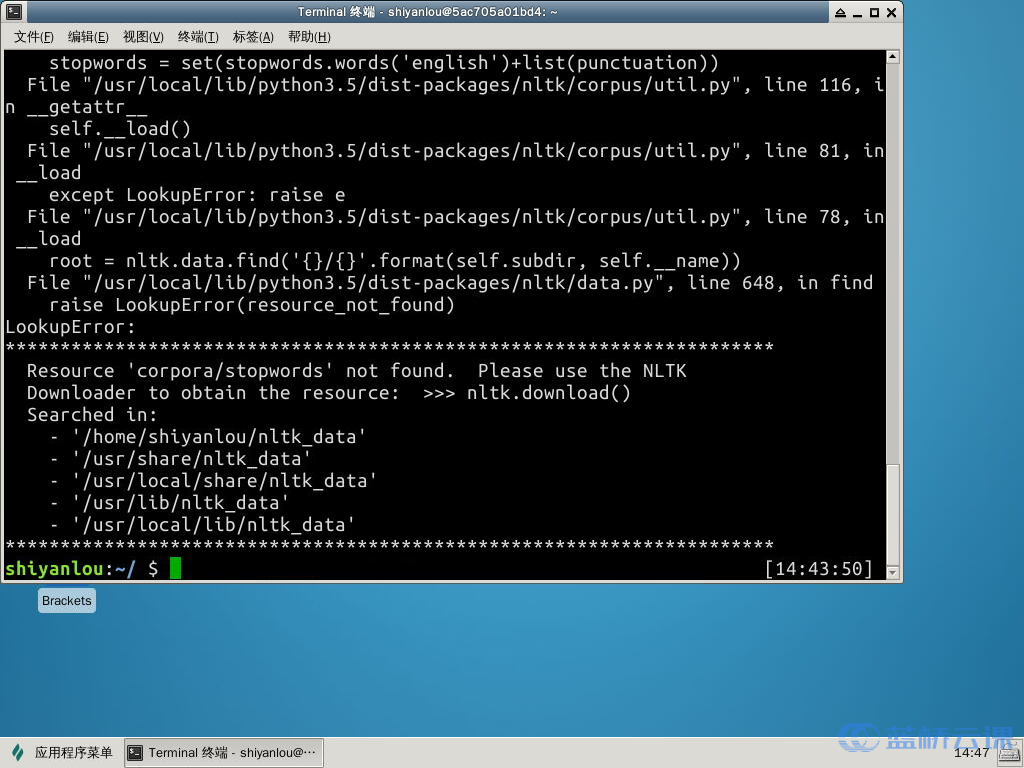
最后
以上就是无心大地最近收集整理的关于python实现英文新闻摘要自动提取_“关键字”法完成新闻摘要提取的全部内容,更多相关python实现英文新闻摘要自动提取_“关键字”法完成新闻摘要提取内容请搜索靠谱客的其他文章。








发表评论 取消回复