一、使用 Druid
Spring Boot 项目中配置数据库连接池为 Druid 并启动项目,Spring 上下文初始化完成后会初始化 DruidDataSource, 如下图:
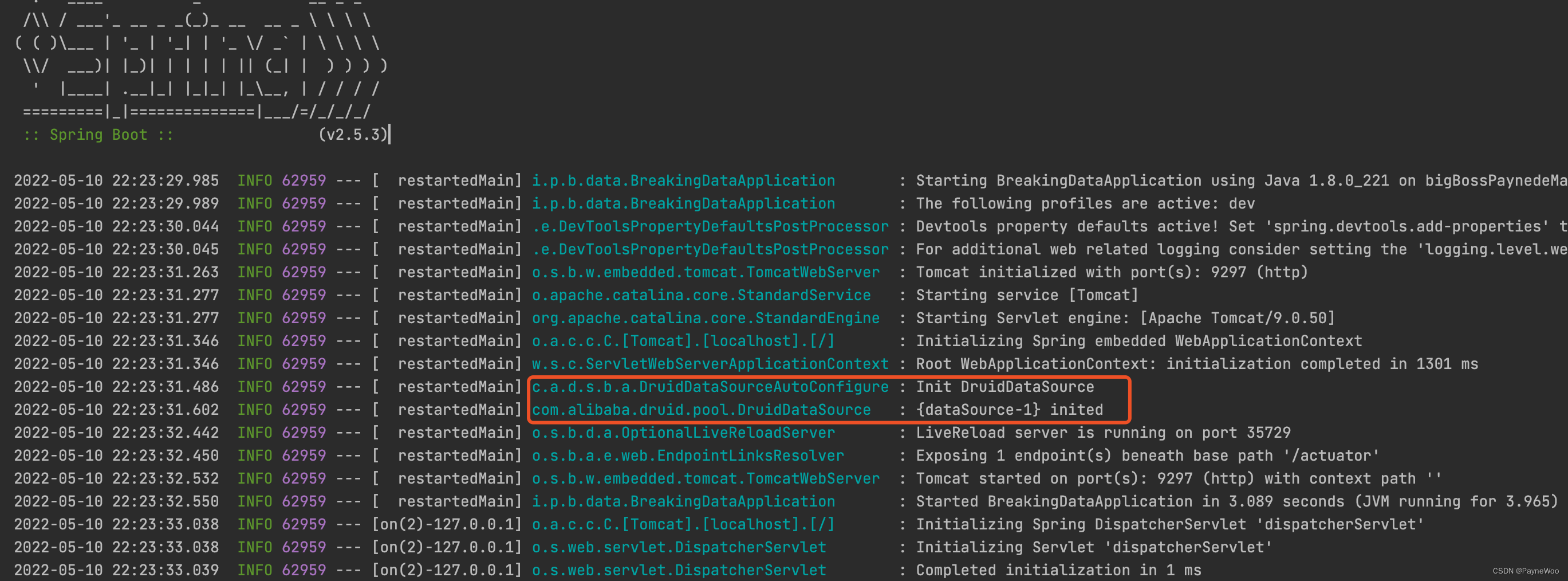
核心类:
DruidDataSourceAutoConfigure负责初始化DruidDataSourcecom.alibaba.druid.pool.DruidDataSource负责创建高效可管理的数据库连接池
二、 druid-spring-boot-starter 源码
DruidDataSourceAutoConfigure 是 druid-spring-boot-starter下的一个配置类。此 starter 中 spring.factories 文件中定义了自动加载 DruidDataSourceAutoConfigure 配置类:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=
com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
DruidDataSourceAutoConfigure 配置类,源码如下,这里初始化了 Bean : DruidDataSourceWrapper(继承了 DruidDataSource类),初始化了DruidDataSourc#init() 方法。
@Configuration
// 判断当前classpath下是否存在 DruidDataSource.class 类,若是则将当前的配置装载入spring 容器
@ConditionalOnClass(DruidDataSource.class)
// DruidDataSourceAutoConfigure 类 在 DataSourceAutoConfiguration 类之前加载
@AutoConfigureBefore(DataSourceAutoConfiguration.class)
// 把使用 @ConfigurationProperties 的类 DruidStatProperties 和 DataSourceProperties 进行了一次注入。
@EnableConfigurationProperties({DruidStatProperties.class, DataSourceProperties.class})
// 把类注入到 IoC 容器
@Import({DruidSpringAopConfiguration.class,
DruidStatViewServletConfiguration.class,
DruidWebStatFilterConfiguration.class,
DruidFilterConfiguration.class})
public class DruidDataSourceAutoConfigure {
private static final Logger LOGGER = LoggerFactory.getLogger(DruidDataSourceAutoConfigure.class);
// 初始化 Bean: DruidDataSourceWrapper
@Bean(initMethod = "init")
@ConditionalOnMissingBean
public DataSource dataSource() {
LOGGER.info("Init DruidDataSource");
return new DruidDataSourceWrapper();
}
}
DruidDataSourceWrapper 类的关系图:
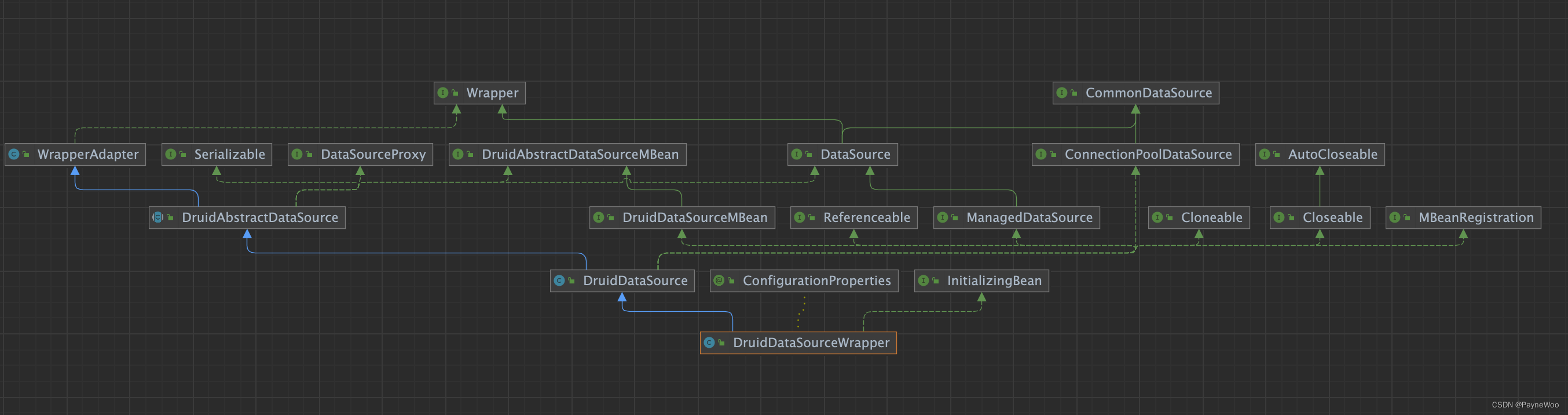
所以,下面重点看DruidDataSource#init() 方法的源码:
三、Druid 如何初始化数据库连接池
DruidDataSourc#init() 方法主要做了这几件事情:
-
初始化 jdbcUrl
-
初始化过滤器:
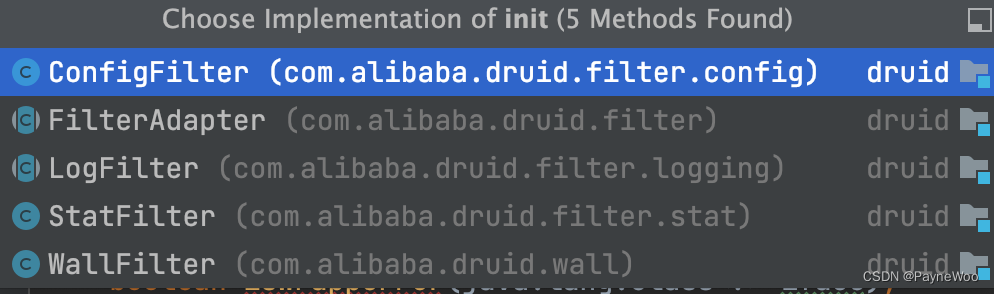
-
根据配置的 jdbcUrl 判断数据库的类型
-
通过 SPI ServiceLoader ,让类加载器加载 过滤器
-
加载数据库驱动
resolveDriver(); -
初始化检查,检查数据库类型和驱动是否支持
-
初始化数据库连接
-
创建线程:连接池日志分析线程、连接池创建线程、连接池销毁线程
-
向线程池提交创建连接的任务:
this.createSchedulerFuture = createScheduler.submit(task);
其中对于并发以及安全的考虑有:
-
整个初始化过程使用可重入锁来保证互斥性:
final ReentrantLock lock = this.lock; -
使用 volatile 变量来保证只会初始化一次
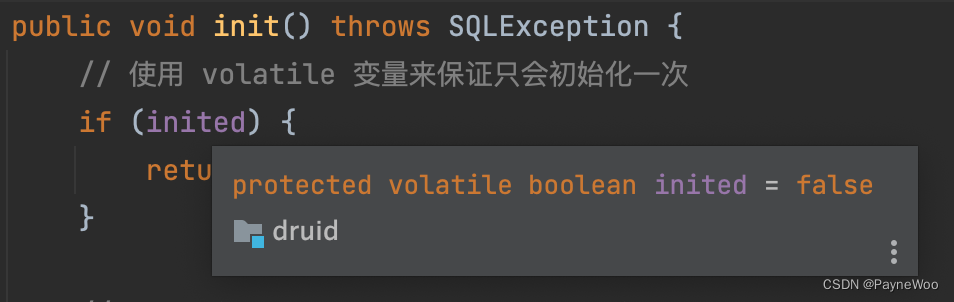
-
DruidDriver 使用静态常量来保证单例
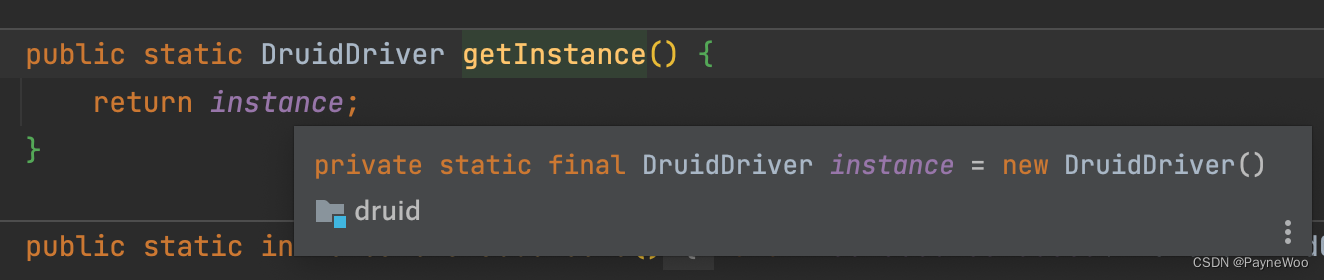
-
使用
AtomicLongFieldUpdater类来原子更新DruidAbstractDataSource中volatile long修饰的变量
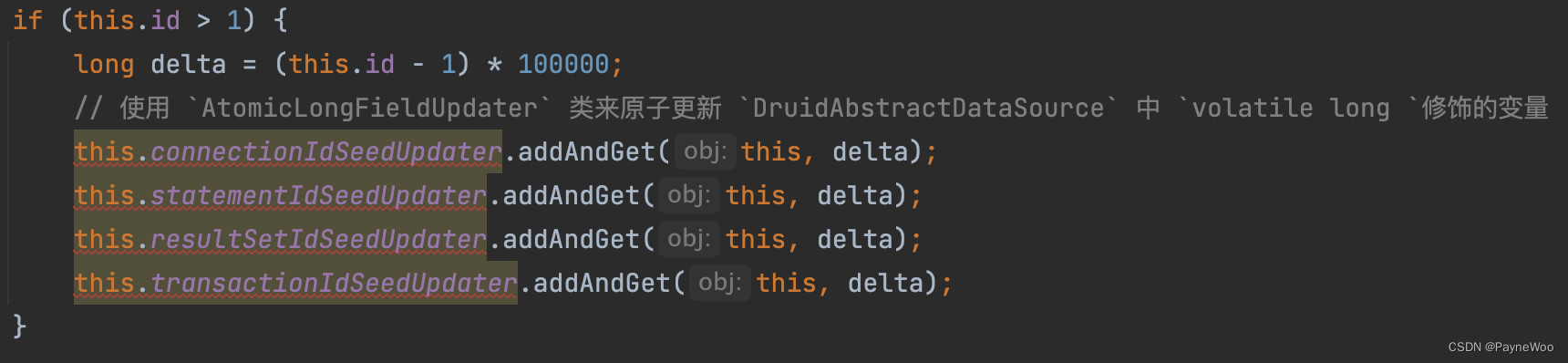
-
使用 CountDownLatch 来确保 「连接池创建线程」、「连接池销毁线程」 一定会创建
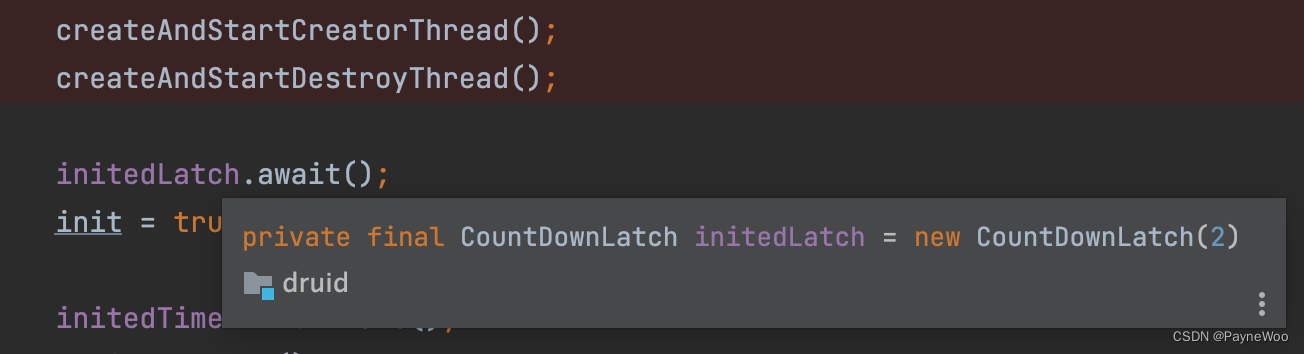
-
使用线程池来优化数据库连接的创建
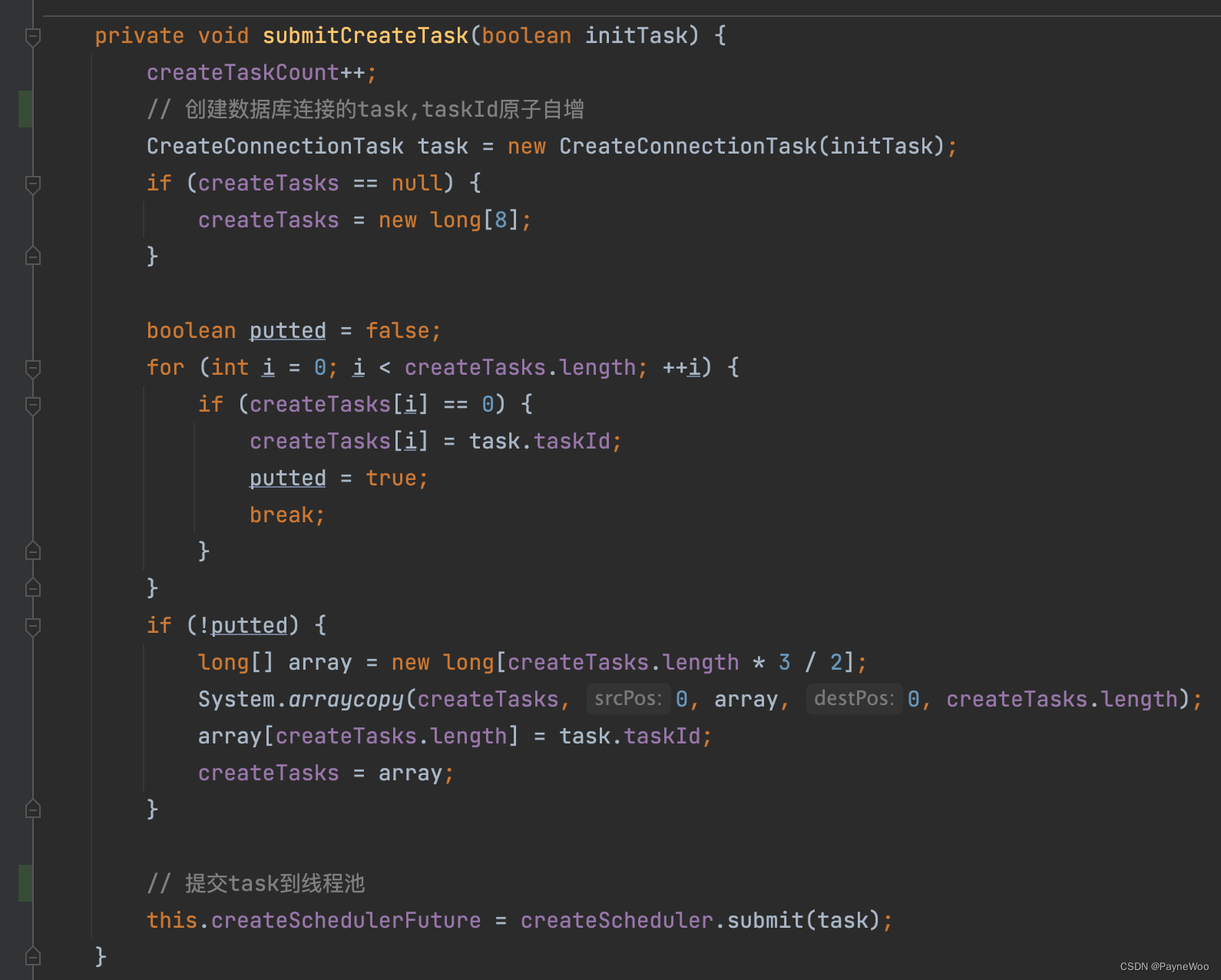
最后
以上就是凶狠花生最近收集整理的关于Spring生态中如何使用 Druid & Druid 如何初始化数据库连接池的全部内容,更多相关Spring生态中如何使用内容请搜索靠谱客的其他文章。








发表评论 取消回复