
微服务进阶
前面我们了解了微服务的一套解决方案,但是它是基于Netflix的解决方案,实际上我们发现,很多框架都已经停止维护了,来看看目前我们所认识到的SpringCloud各大组件的维护情况:
- **注册中心:**Eureka(属于Netflix,2.x版本不再开源,1.x版本仍在更新)
- **服务调用:**Ribbon(属于Netflix,停止更新,已经彻底被移除)、SpringCloud Loadbalancer(属于SpringCloud官方,目前的默认方案)
- **服务降级:**Hystrix(属于Netflix,停止更新,已经彻底被移除)
- **路由网关:**Zuul(属于Netflix,停止更新,已经彻底被移除)、Gateway(属于SpringCloud官方,推荐方案)
- **配置中心:**Config(属于SpringCloud官方)
可见,我们之前使用的整套解决方案中,超过半数的组件都已经处于不可用状态,并且部分组件都是SpringCloud官方出手提供框架进行解决,因此,寻找一套更好的解决方案势在必行,也就引出了我们本章的主角:SpringCloud Alibaba
阿里巴巴作为业界的互联网大厂,给出了一套全新的解决方案,官方网站(中文):https://spring-cloud-alibaba-group.github.io/github-pages/2021/zh-cn/index.html
Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。
依托 Spring Cloud Alibaba,您只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里分布式应用解决方案,通过阿里中间件来迅速搭建分布式应用系统。
目前 Spring Cloud Alibaba 提供了如下功能:
- 服务限流降级:支持 WebServlet、WebFlux, OpenFeign、RestTemplate、Dubbo 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控。
- 服务注册与发现:适配 Spring Cloud 服务注册与发现标准,默认集成了 Ribbon 的支持。
- 分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新。
- Rpc服务:扩展 Spring Cloud 客户端 RestTemplate 和 OpenFeign,支持调用 Dubbo RPC 服务
- 消息驱动能力:基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。
- 分布式事务:使用 @GlobalTransactional 注解, 高效并且对业务零侵入地解决分布式事务问题。
- 阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
- 分布式任务调度:提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker(schedulerx-client)上执行。
- 阿里云短信服务:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
可以看到,SpringCloudAlibaba实际上是对我们的SpringCloud组件增强功能,是SpringCloud的增强框架,可以兼容SpringCloud原生组件和SpringCloudAlibaba的组件。
开始学习之前,把我们之前打包好的拆分项目解压,我们将基于它进行讲解。

Nacos 更加全能的注册中心
Nacos(Naming Configuration Service)是一款阿里巴巴开源的服务注册与发现、配置管理的组件,相当于是Eureka+Config的组合形态。
安装与部署
Nacos服务器是独立安装部署的,因此我们需要下载最新的Nacos服务端程序,下载地址:https://github.com/alibaba/nacos,连不上可以到视频下方云盘中下载。
可以看到目前最新的版本是1.4.3版本(2022年2月27日发布的),我们直接下载zip文件即可。
接着我们将文件进行解压,得到以下内容:
我们直接将其拖入到项目文件夹下,便于我们一会在IDEA内部启动,接着添加运行配置:
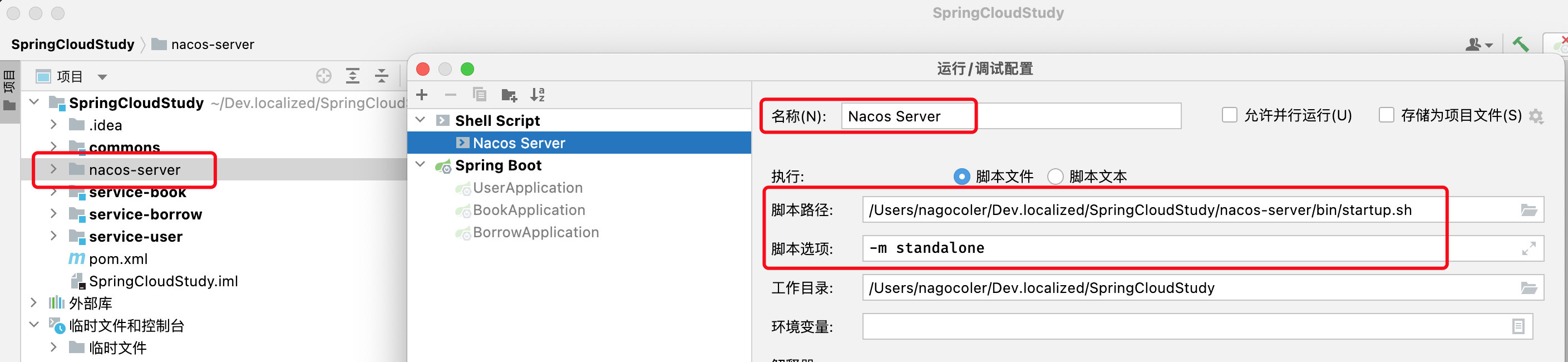
其中-m standalone表示单节点模式,Mac和Linux下记得将解释器设定为/bin/bash,由于Nacos在Mac/Linux默认是后台启动模式,我们修改一下它的bash文件,让它变成前台启动,这样IDEA关闭了Nacos就自动关闭了,否则开发环境下很容易忘记关:
# 注释掉 nohup $JAVA ${JAVA_OPT} nacos.nacos >> ${BASE_DIR}/logs/start.out 2>&1 &
# 替换成下面的
$JAVA ${JAVA_OPT} nacos.nacos
接着我们点击启动:

OK,启动成功,可以看到它的管理页面地址也是给我们贴出来了: http://localhost:8848/nacos/index.html,访问这个地址:
默认的用户名和管理员密码都是nacos,直接登陆即可,可以看到进入管理页面之后功能也是相当丰富:
至此,Nacos的安装与部署完成。
服务注册与发现
现在我们要实现基于Nacos的服务注册与发现,那么就需要导入SpringCloudAlibaba相关的依赖,我们在父工程将依赖进行管理:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.0</version>
</dependency>
<!-- 这里引入最新的SpringCloud依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- 这里引入最新的SpringCloudAlibaba依赖,2021.0.1.0版本支持SpringBoot2.6.X -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2021.0.1.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
接着我们就可以在子项目中添加服务发现依赖了,比如我们以图书服务为例:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
和注册到Eureka一样,我们也需要在配置文件中配置Nacos注册中心的地址:
server:
# 之后所有的图书服务节点就81XX端口
port: 8101
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://cloudstudy.mysql.cn-chengdu.rds.aliyuncs.com:3306/cloudstudy
username: test
password: 123456
# 应用名称 bookservice
application:
name: bookservice
cloud:
nacos:
discovery:
# 配置Nacos注册中心地址
server-addr: localhost:8848
接着启动我们的图书服务,可以在Nacos的服务列表中找到:

按照同样的方法,我们接着将另外两个服务也注册到Nacos中:

接着我们使用OpenFeign,实现服务发现远程调用以及负载均衡,导入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!-- 这里需要单独导入LoadBalancer依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
编写接口:
@FeignClient("userservice")
public interface UserClient {
@RequestMapping("/user/{uid}")
User getUserById(@PathVariable("uid") int uid);
}
@FeignClient("bookservice")
public interface BookClient {
@RequestMapping("/book/{bid}")
Book getBookById(@PathVariable("bid") int bid);
}
@Service
public class BorrowServiceImpl implements BorrowService{
@Resource
BorrowMapper mapper;
@Resource
UserClient userClient;
@Resource
BookClient bookClient;
@Override
public UserBorrowDetail getUserBorrowDetailByUid(int uid) {
List<Borrow> borrow = mapper.getBorrowsByUid(uid);
User user = userClient.getUserById(uid);
List<Book> bookList = borrow
.stream()
.map(b -> bookClient.getBookById(b.getBid()))
.collect(Collectors.toList());
return new UserBorrowDetail(user, bookList);
}
}
@EnableFeignClients
@SpringBootApplication
public class BorrowApplication {
public static void main(String[] args) {
SpringApplication.run(BorrowApplication.class, args);
}
}
接着我们进行测试:

测试正常,可以自动发现服务,接着我们来多配置几个实例,去掉图书服务和用户服务的端口配置:
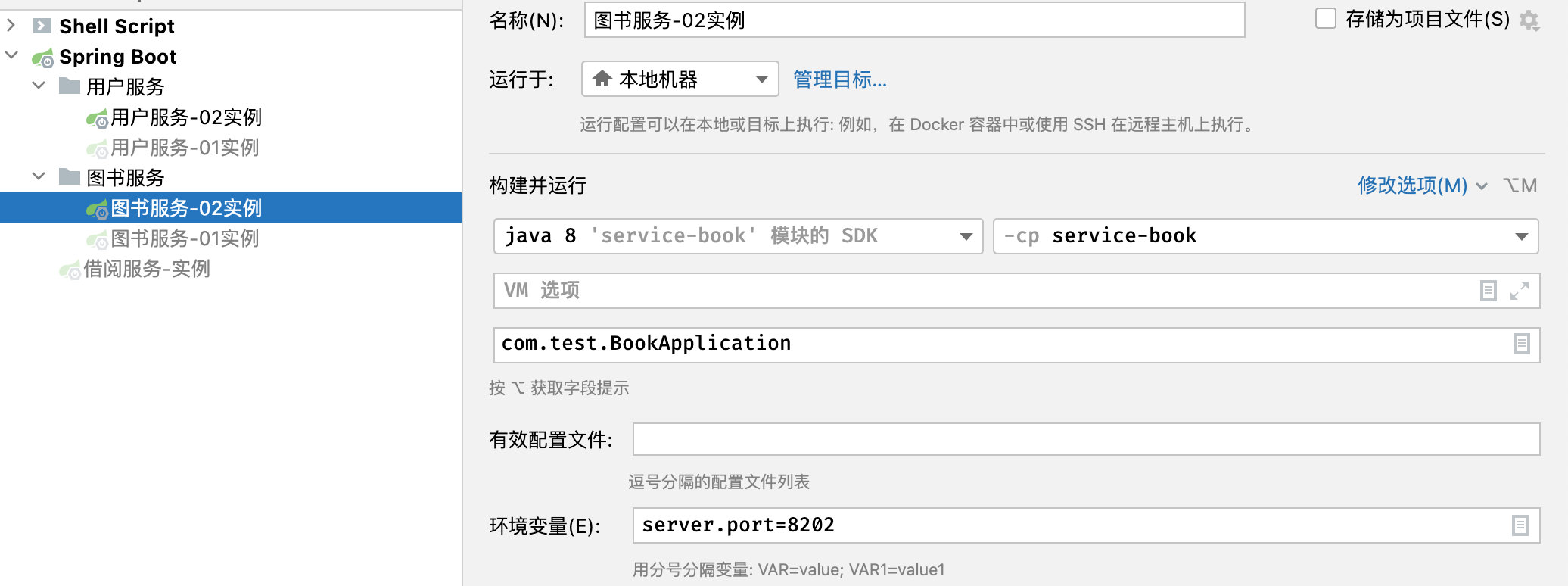
然后我们在图书服务和用户服务中添加一句打印方便之后查看:
@RequestMapping("/user/{uid}")
public User findUserById(@PathVariable("uid") int uid){
System.out.println("调用用户服务");
return service.getUserById(uid);
}
现在将全部服务启动:

可以看到Nacos中的实例数量已经显示为2:

接着我们调用借阅服务,看看能否负载均衡远程调用:

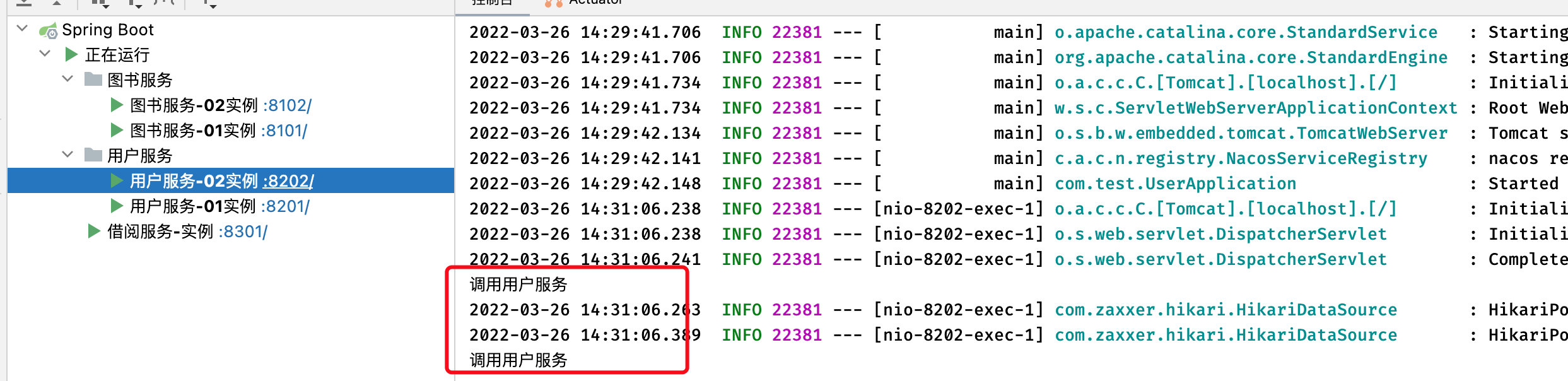
OK,负载均衡远程调用没有问题,这样我们就实现了基于Nacos的服务的注册与发现,实际上大致流程与Eureka一致。
值得注意的是,Nacos区分了临时实例和非临时实例:

那么临时和非临时有什么区别呢?
- 临时实例:和Eureka一样,采用心跳机制向Nacos发送请求保持在线状态,一旦心跳停止,代表实例下线,不保留实例信息。
- 非临时实例:由Nacos主动进行联系,如果连接失败,那么不会移除实例信息,而是将健康状态设定为false,相当于会对某个实例状态持续地进行监控。
我们可以通过配置文件进行修改临时实例:
spring:
application:
name: borrowservice
cloud:
nacos:
discovery:
server-addr: localhost:8848
# 将ephemeral修改为false,表示非临时实例
ephemeral: false
接着我们在Nacos中查看,可以发现实例已经不是临时的了:

如果这时我们关闭此实例,那么会变成这样:

只是将健康状态变为false,而不会删除实例的信息。
集群分区
实际上集群分区概念在之前的Eureka中也有出现,比如:
eureka:
client:
fetch-registry: false
register-with-eureka: false
service-url:
defaultZone: http://localhost:8888/eureka
# 这个defaultZone是个啥玩意,为什么要用这个名称?为什么要要用这样的形式来声明注册中心?
在一个分布式应用中,相同服务的实例可能会在不同的机器、位置上启动,比如我们的用户管理服务,可能在成都有1台服务器部署、重庆有一台服务器部署,而这时,我们在成都的服务器上启动了借阅服务,那么如果我们的借阅服务现在要调用用户服务,就应该优先选择同一个区域的用户服务进行调用,这样会使得响应速度更快。
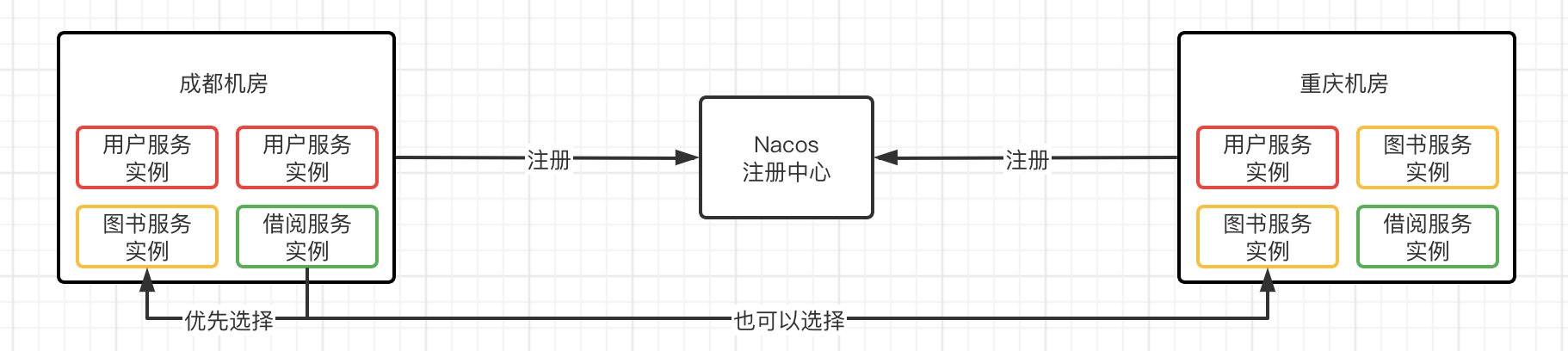
因此,我们可以对部署在不同机房的服务进行分区,可以看到实例的分区是默认:
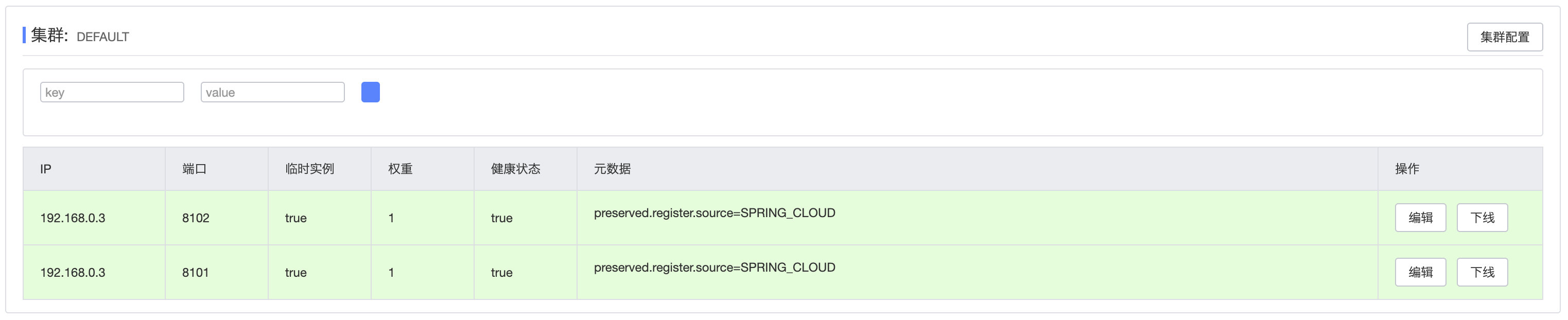
我们可以直接在配置文件中进行修改:
spring:
application:
name: borrowservice
cloud:
nacos:
discovery:
server-addr: localhost:8848
# 修改为重庆地区的集群
cluster-name: Chongqing
当然由于我们这里使用的是不同的启动配置,直接在启动配置中添加环境变量spring.cloud.nacos.discovery.cluster-name也行,这里我们将用户服务和图书服务两个区域都分配一个,借阅服务就配置为成都地区:
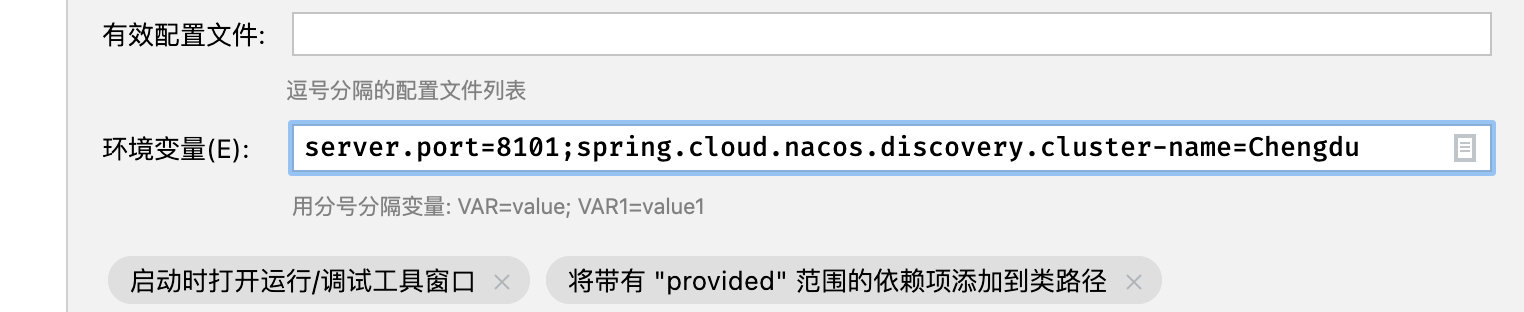
修改完成之后,我们来尝试重新启动一下(Nacos也要重启),观察Nacos中集群分布情况:
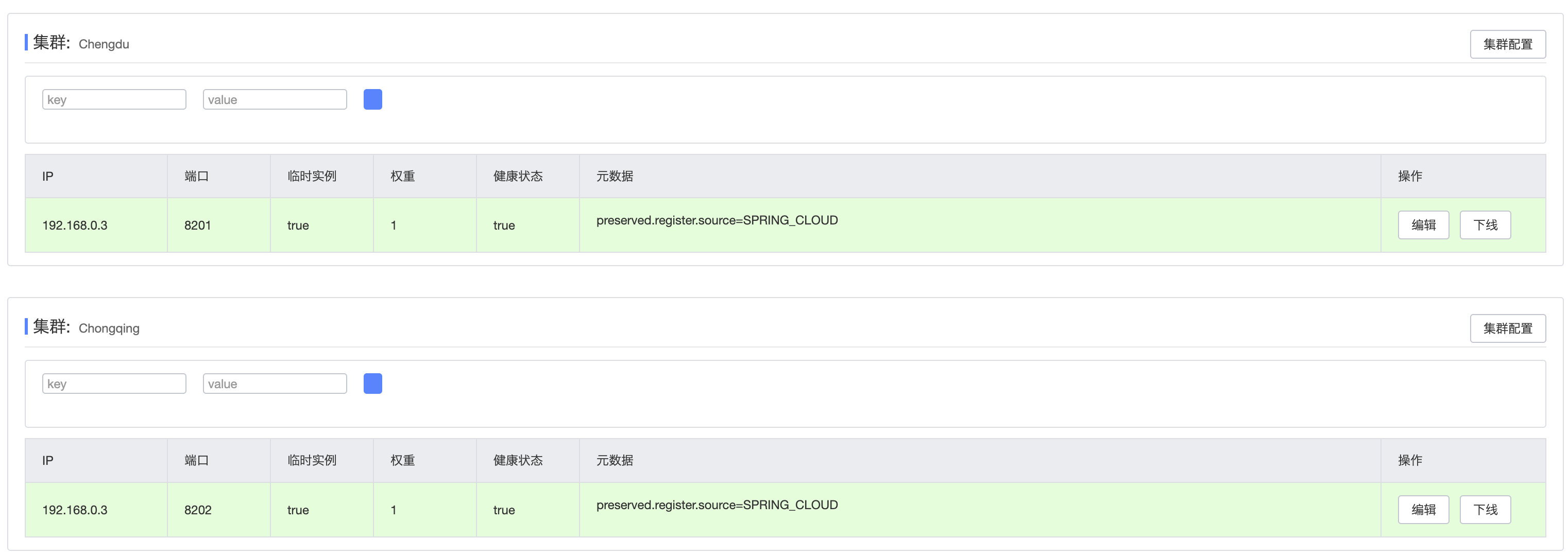
可以看到现在有两个集群,并且都有一个实例正在运行。我们接着去调用借阅服务,但是发现并没有按照区域进行优先调用,而依然使用的是轮询模式的负载均衡调用。
我们必须要提供Nacos的负载均衡实现才能开启区域优先调用机制,只需要在配制文件中进行修改即可:
spring:
application:
name: borrowservice
cloud:
nacos:
discovery:
server-addr: localhost:8848
cluster-name: Chengdu
# 将loadbalancer的nacos支持开启,集成Nacos负载均衡
loadbalancer:
nacos:
enabled: true
现在我们重启借阅服务,会发现优先调用的是同区域的用户和图书服务,现在我们可以将成都地区的服务下线:

可以看到,在下线之后,由于本区域内没有可用服务了,借阅服务将会调用重庆区域的用户服务。
除了根据区域优先调用之外,同一个区域内的实例也可以单独设置权重,Nacos会优先选择权重更大的实例进行调用,我们可以直接在管理页面中进行配置:
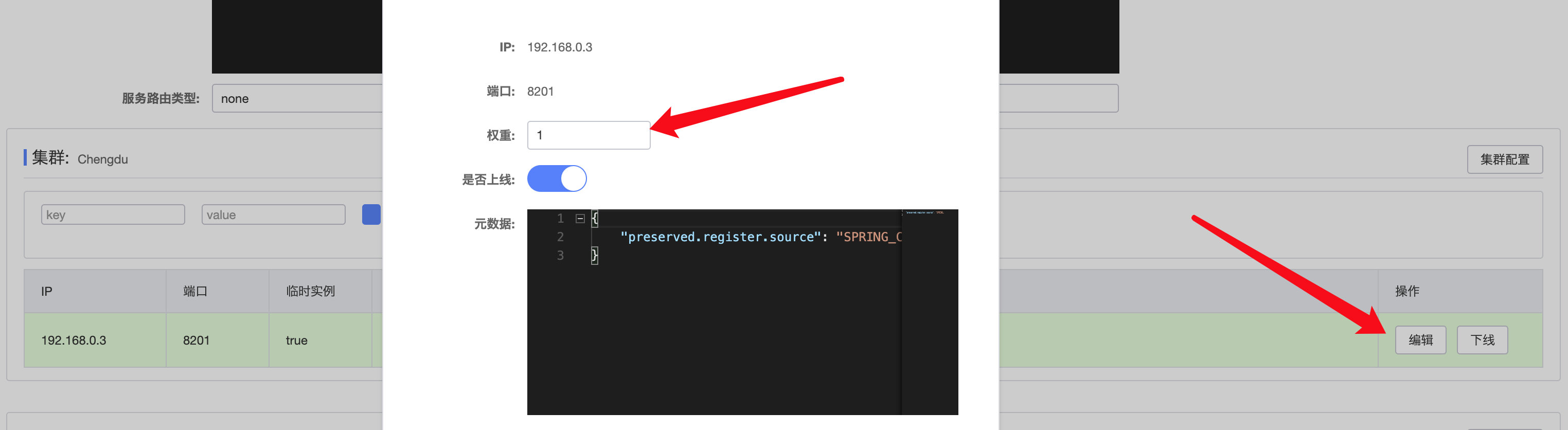
或是在配置文件中进行配置:
spring:
application:
name: borrowservice
cloud:
nacos:
discovery:
server-addr: localhost:8848
cluster-name: Chengdu
# 权重大小,越大越优先调用,默认为1
weight: 0.5
通过配置权重,某些性能不太好的机器就能够更少地被使用,而更多的使用那些网络良好性能更高的主机上的实例。
配置中心
前面我们学习了SpringCloud Config,我们可以通过配置服务来加载远程配置,这样我们就可以在远端集中管理配置文件。
实际上我们可以在bootstrap.yml中配置远程配置文件获取,然后再进入到配置文件加载环节,而Nacos也支持这样的操作,使用方式也比较类似,比如我们现在想要将借阅服务的配置文件放到Nacos进行管理,那么这个时候就需要在Nacos中创建配置文件:

将借阅服务的配置文件全部(当然正常情况下是不会全部CV的,只会复制那些需要经常修改的部分,这里为了省事就直接全部CV了)复制过来,注意Data ID的格式跟我们之前一样,应用名称-环境.yml,如果只编写应用名称,那么代表此配置文件无论在什么环境下都会使用,然后每个配置文件都可以进行分组,也算是一种分类方式:
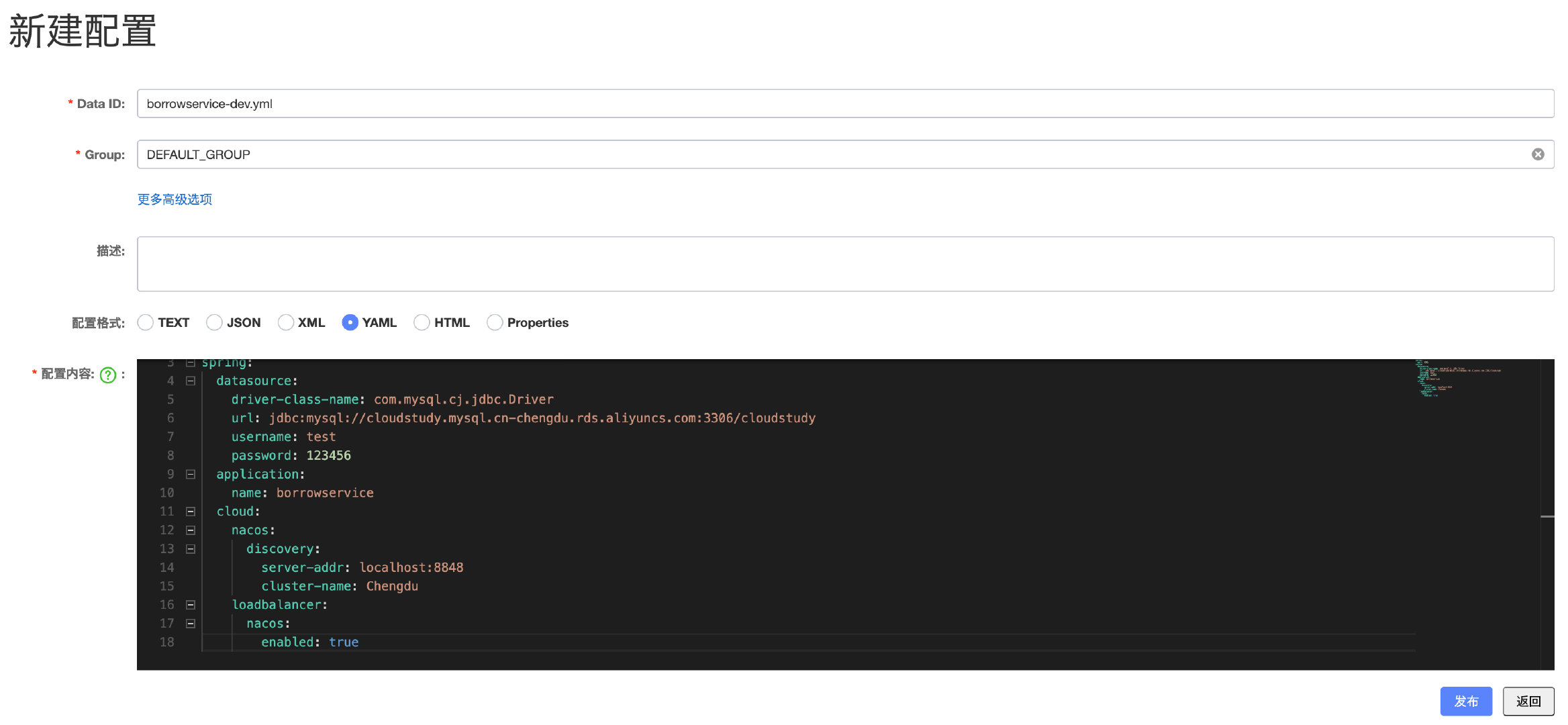
完成之后点击发布即可:

然后在项目中导入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
接着我们在借阅服务中添加bootstrap.yml文件:
spring:
application:
# 服务名称和配置文件保持一致
name: borrowservice
profiles:
# 环境也是和配置文件保持一致
active: dev
cloud:
nacos:
config:
# 配置文件后缀名
file-extension: yml
# 配置中心服务器地址,也就是Nacos地址
server-addr: localhost:8848
现在我们启动服务试试看:

可以看到成功读取配置文件并启动了,实际上使用上来说跟之前的Config是基本一致的。
Nacos还支持配置文件的热更新,比如我们在配置文件中添加了一个属性,而这个时候可能需要实时修改,并在后端实时更新,那么这种该怎么实现呢?我们创建一个新的Controller:
@RestController
public class TestController {
@Value("${test.txt}")
//我们从配置文件中读取test.txt的字符串值,作为test接口的返回值
String txt;
@RequestMapping("/test")
public String test(){
return txt;
}
}
我们修改一下配置文件,然后重启服务器:
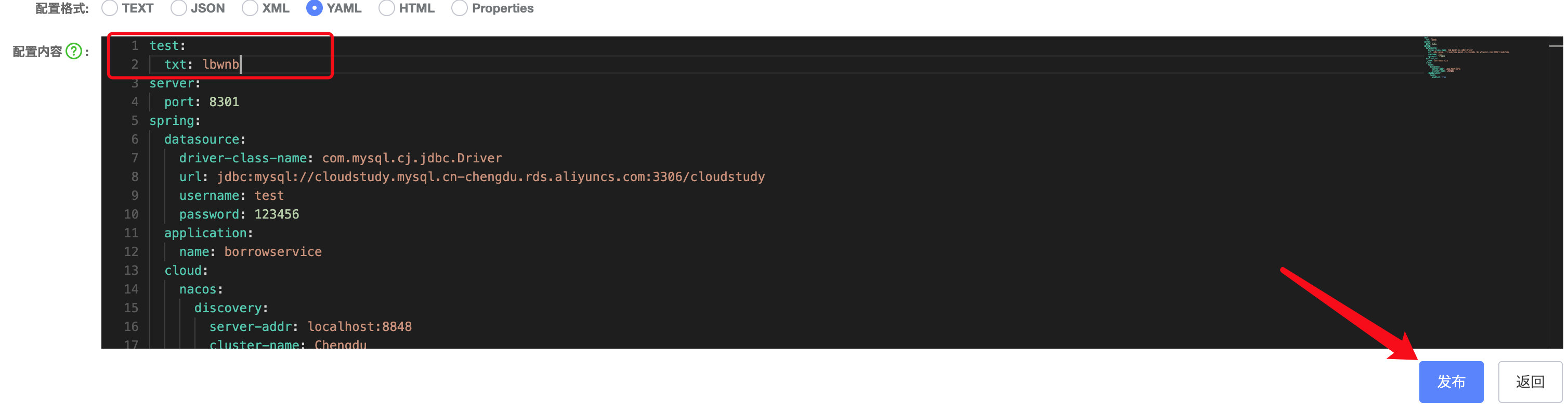
可以看到已经可以正常读取了:

现在我们将配置文件的值进行修改:

再次访问接口,会发现没有发生变化:

但是后台是成功检测到值更新了,但是值却没改变:

那么如何才能实现配置热更新呢?我们可以像下面这样:
@RestController
@RefreshScope
//添加此注解就能实现自动刷新了
public class TestController {
@Value("${test.txt}")
String txt;
@RequestMapping("/test")
public String test(){
return txt;
}
}
重启服务器,再次重复上述实验,成功。
命名空间
我们还可以将配置文件或是服务实例划分到不同的命名空间中,其实就是区分开发、生产环境或是引用归属之类的:

这里我们创建一个新的命名空间:
可以看到在dev命名空间下,没有任何配置文件和服务:
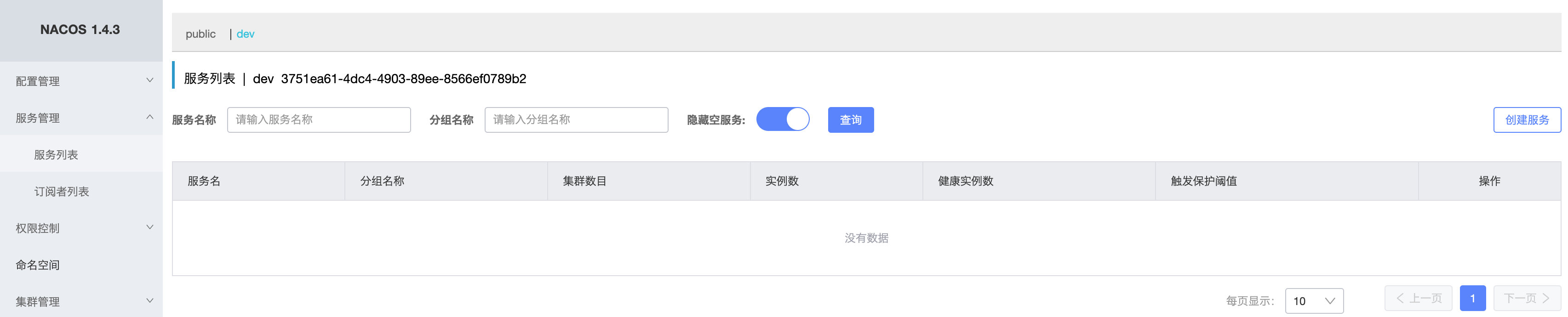
我们在不同的命名空间下,实例和配置都是相互之间隔离的,我们也可以在配置文件中指定当前的命名空间。
实现高可用
由于Nacos暂不支持Arm架构芯片的Mac集群搭建,本小节用Linxu云主机(Nacos比较吃内存,2个Nacos服务器集群,至少2G内存)环境演示。
通过前面的学习,我们已经了解了如何使用Nacos以及Nacos的功能等,最后我们来看看,如果像之前Eureka一样,搭建Nacos集群,实现高可用。
官方方案:https://nacos.io/zh-cn/docs/cluster-mode-quick-start.html
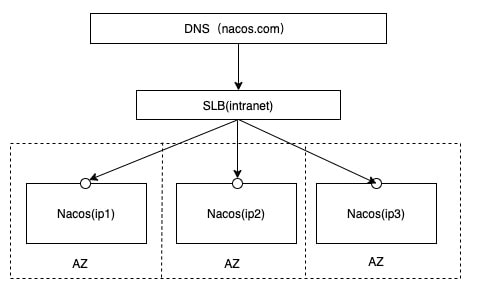
http://ip1:port/openAPI 直连ip模式,机器挂则需要修改ip才可以使用。
http://SLB:port/openAPI 挂载SLB模式(内网SLB,不可暴露到公网,以免带来安全风险),直连SLB即可,下面挂server真实ip,可读性不好。
http://nacos.com:port/openAPI 域名 + SLB模式(内网SLB,不可暴露到公网,以免带来安全风险),可读性好,而且换ip方便,推荐模式
我们来看看它的架构设计,它推荐我们在所有的Nacos服务端之前建立一个负载均衡,我们通过访问负载均衡服务器来间接访问到各个Nacos服务器。实际上就,是比如有三个Nacos服务器做集群,但是每个服务不可能把每个Nacos都去访问一次进行注册,实际上只需要在任意一台Nacos服务器上注册即可,Nacos服务器之间会自动同步信息,但是如果我们随便指定一台Nacos服务器进行注册,如果这台Nacos服务器挂了,但是其他Nacos服务器没挂,这样就没办法完成注册了,但是实际上整个集群还是可用的状态。
所以这里就需要在所有Nacos服务器之前搭建一个SLB(服务器负载均衡),这样就可以避免上面的问题了。但是我们知道,如果要实现外界对服务访问的负载均衡,我们就得用比如之前说到的Gateway来实现,而这里实际上我们可以用一个更加方便的工具:Nginx,来实现(之前我们没讲过,但是使用起来很简单,放心后面会带着大家使用)
关于SLB最上方还有一个DNS(我们在计算机网络这门课程中学习过),这个是因为SLB是裸IP,如果SLB服务器修改了地址,那么所有微服务注册的地址也得改,所以这里是通过加域名,通过域名来访问,让DNS去解析真实IP,这样就算改变IP,只需要修改域名解析记录即可,域名地址是不会变化的。
最后就是Nacos的数据存储模式,在单节点的情况下,Nacos实际上是将数据存放在自带的一个嵌入式数据库中:
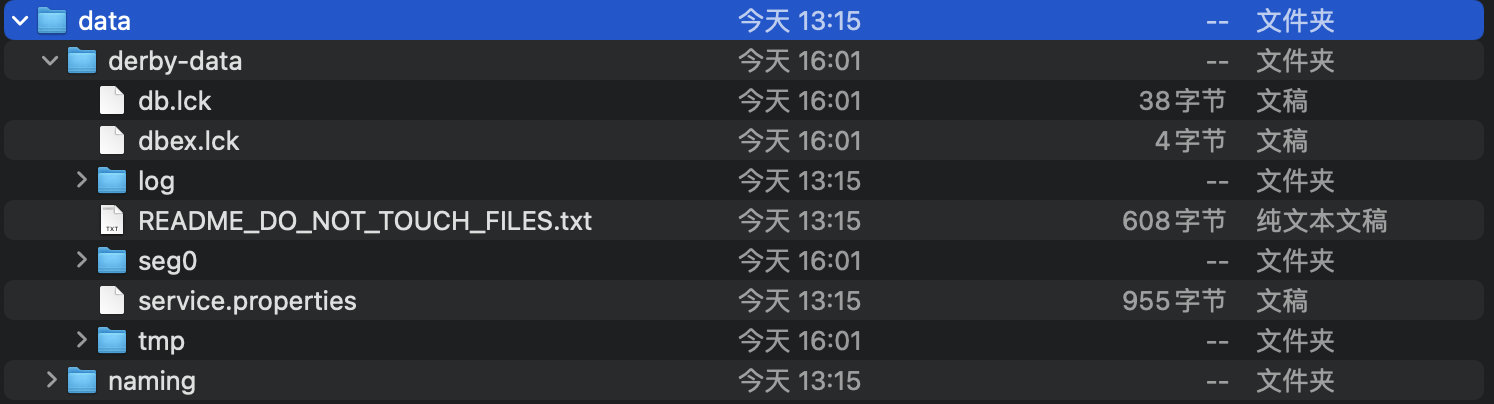
而这种模式只适用于单节点,在多节点集群模式下,肯定是不能各存各的,所以,Nacos提供了MySQL统一存储支持,我们只需要让所有的Nacos服务器连接MySQL进行数据存储即可,官方也提供好了SQL文件。
现在就可以开始了,第一步,我们直接导入数据库即可,文件在conf目录中:
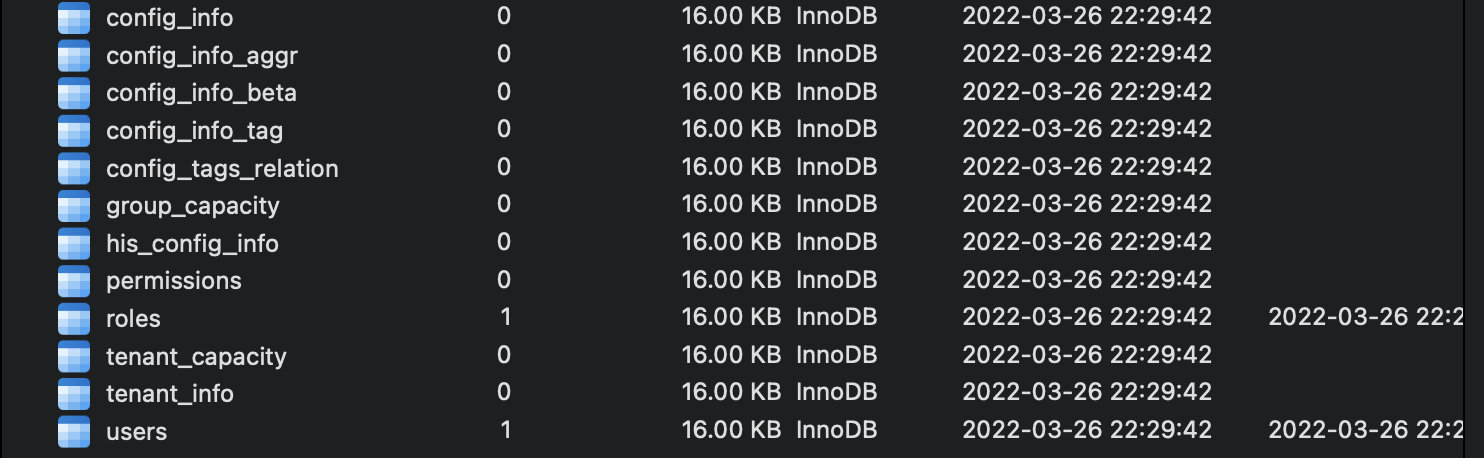
我们来将其导入到数据库,可以看到生成了很多的表:
然后我们来创建两个Nacos服务器,做一个迷你的集群,这里使用scp命令将nacos服务端上传到Linux服务器(注意需要提前安装好JRE 8或更高版本的环境):

解压之后,我们对其配置文件进行修改,首先是application.properties配置文件,修改以下内容,包括MySQL服务器的信息:
### Default web server port:
server.port=8801
#*************** Config Module Related Configurations ***************#
### If use MySQL as datasource:
spring.datasource.platform=mysql
### Count of DB:
db.num=1
### Connect URL of DB:
db.url.0=jdbc:mysql://cloudstudy.mysql.cn-chengdu.rds.aliyuncs.com:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=nacos
db.password.0=nacos
然后修改集群配置,这里需要重命名一下:

端口记得使用内网IP地址:

最后我们修改一下Nacos的内存分配以及前台启动,直接修改startup.sh文件(内存有限,玩不起高的):
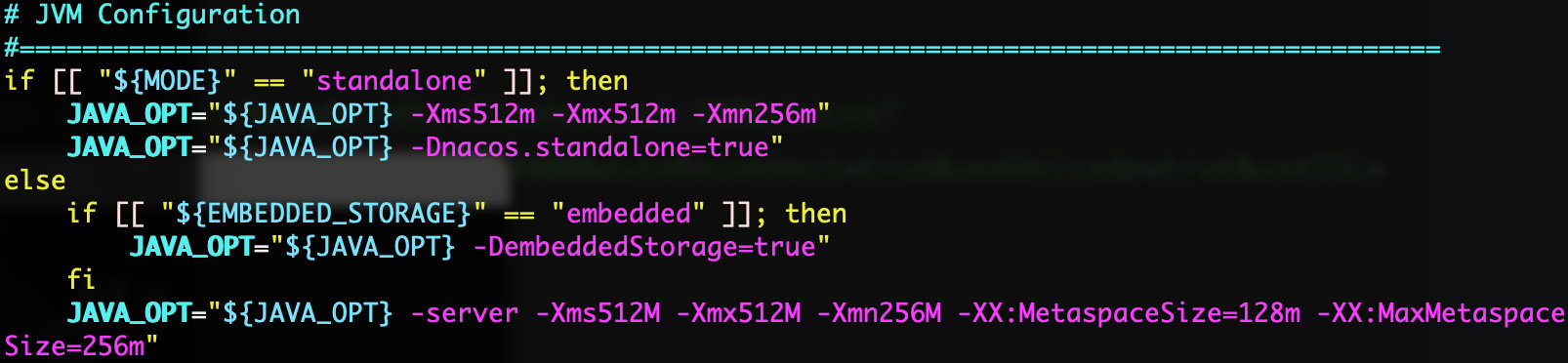
保存之后,将nacos复制一份,并将端口修改为8802,接着启动这两个Nacos服务器。

然后我们打开管理面板,可以看到两个节点都已经启动了:
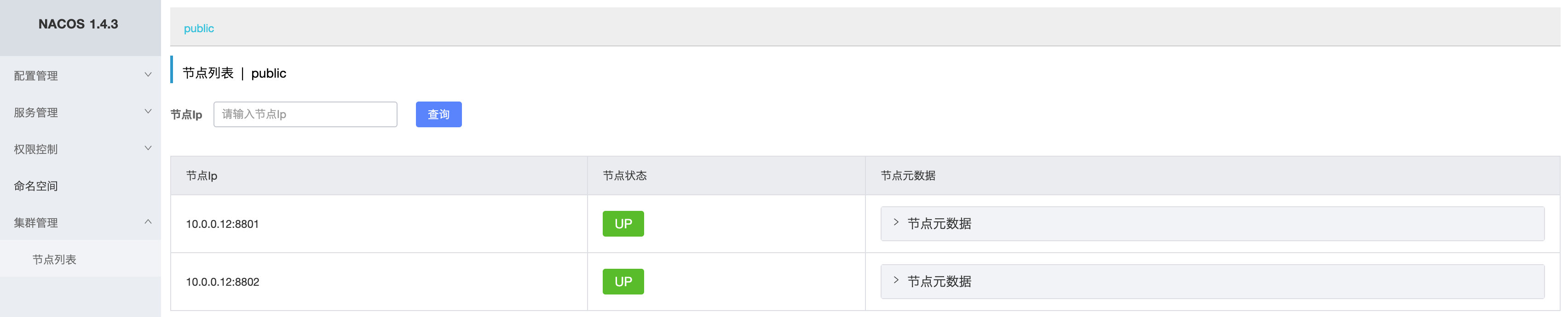
这样,我们第二步就完成了,接着我们需要添加一个SLB,这里我们用Nginx做反向代理:
Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。它相当于在内网与外网之间形成一个网关,所有的请求都可以由Nginx服务器转交给内网的其他服务器。
这里我们直接安装:
sudo apt install nginx
可以看到直接请求80端口之后得到,表示安装成功:

现在我们需要让其代理我们刚刚启动的两个Nacos服务器,我们需要对其进行一些配置。配置文件位于/etc/nginx/nginx.conf,添加以下内容:
#添加我们在上游刚刚创建好的两个nacos服务器
upstream nacos-server {
server 10.0.0.12:8801;
server 10.0.0.12:8802;
}
server {
listen
80;
server_name
1.14.121.107;
location /nacos {
proxy_pass http://nacos-server;
}
}
重启Nginx服务器,成功连接:

然后我们将所有的服务全部修改为云服务器上Nacos的地址,启动试试看。
这样,我们就搭建好了Nacos集群。

Sentinel 流量防卫兵
**注意:**这一章有点小绕,思路理清。
经过之前的学习,我们了解了微服务存在的雪崩问题,也就是说一个微服务出现问题,有可能导致整个链路直接不可用,这种时候我们就需要进行及时的熔断和降级,这些策略,我们之前通过使用Hystrix来实现。
SpringCloud Alibaba也有自己的微服务容错组件,但是它相比Hystrix更加的强大。
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 具有以下特征:
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Apache Dubbo、gRPC、Quarkus 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。同时 Sentinel 提供 Java/Go/C++ 等多语言的原生实现。
- 完善的 SPI 扩展机制:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
安装与部署
和Nacos一样,它是独立安装和部署的,下载地址:https://github.com/alibaba/Sentinel/releases
注意下载下来之后是一个jar文件(其实就是个SpringBoot项目),我们需要在IDEA中添加一些运行配置:

接着就可以直接启动啦,当然默认端口占用8080,如果需要修改,可以添加环境变量:

启动之后,就可以访问到Sentinel的监控页面了,用户名和密码都是sentinel,地址:http://localhost:8858/#/dashboard

这样就成功开启监控页面了,接着我们需要让我们的服务连接到Sentinel控制台,老规矩,导入依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
然后在配置文件中添加Sentinel相关信息(实际上Sentinel是本地在进行管理,但是我们可以连接到监控页面,这样就可以图形化操作了):
spring:
application:
name: userservice
cloud:
nacos:
discovery:
server-addr: localhost:8848
sentinel:
transport:
# 添加监控页面地址即可
dashboard: localhost:8858
现在启动我们的服务,然后访问一次服务,这样Sentinel中就会存在信息了(懒加载机制,不会一上来就加载):

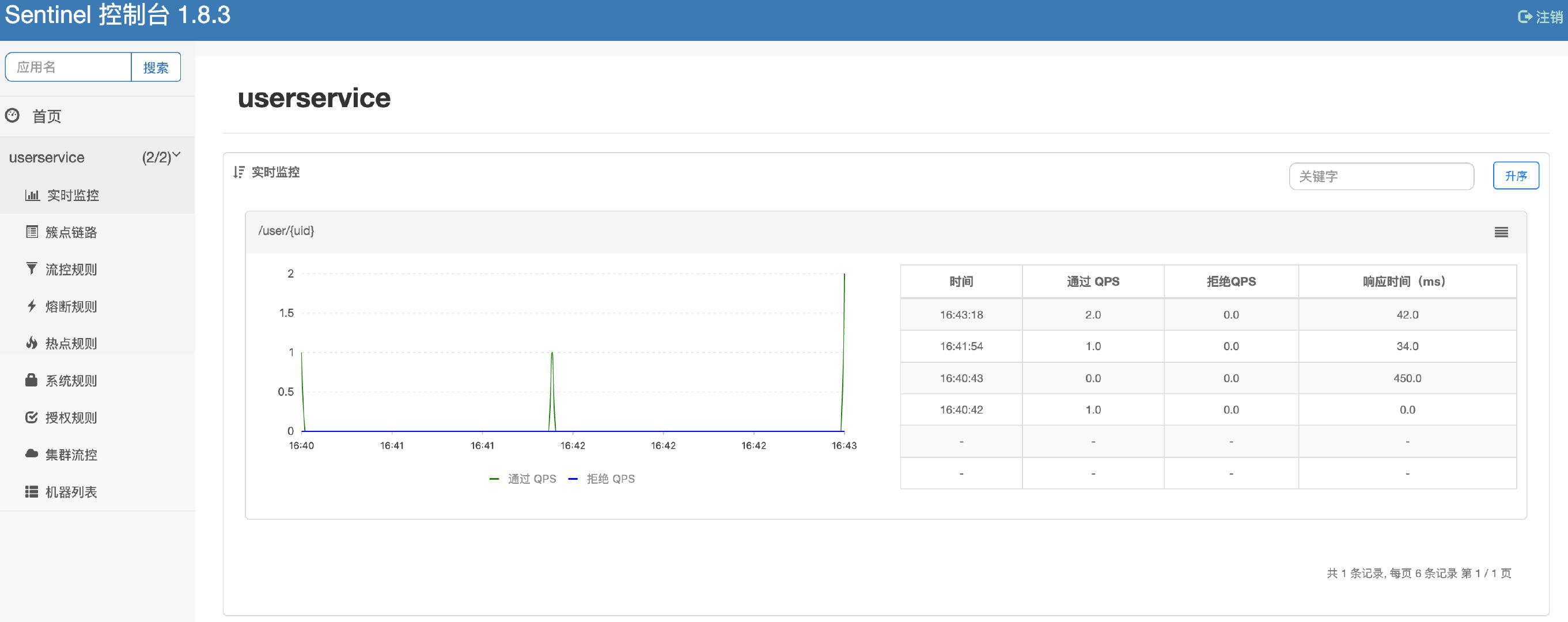
现在我们就可以在Sentinel控制台中对我们的服务运行情况进行实时监控了,可以看到监控的内容非常的多,包括时间点、QPS(每秒查询率)、响应时间等数据。
按照上面的方式,我们将所有的服务全部连接到Sentinel管理面板中。
流量控制
前面我们完成了对Sentinel的搭建与连接,接着我们来看看Sentinel的第一个功能,流量控制。
我们的机器不可能无限制的接受和处理客户端的请求,如果不加以限制,当发生高并发情况时,系统资源将很快被耗尽。为了避免这种情况,我们就可以添加流量控制(也可以说是限流)当一段时间内的流量到达一定的阈值的时候,新的请求将不再进行处理,这样不仅可以合理地应对高并发请求,同时也能在一定程度上保护服务器不受到外界的恶意攻击。
那么要实现限流,正常情况下,我们该采取什么样的策略呢?
- 方案一:快速拒绝,既然不再接受新的请求,那么我们可以直接返回一个拒绝信息,告诉用户访问频率过高。
- 方案二:预热,依然基于方案一,但是由于某些情况下高并发请求是在某一时刻突然到来,我们可以缓慢地将阈值提高到指定阈值,形成一个缓冲保护。
- 方案三:排队等待,不接受新的请求,但是也不直接拒绝,而是进队列先等一下,如果规定时间内能够执行,那么就执行,要是超时就算了。
针对于是否超过流量阈值的判断,这里我们提4种算法:
-
漏桶算法
顾名思义,就像一个桶开了一个小孔,水流进桶中的速度肯定是远大于水流出桶的速度的,这也是最简单的一种限流思路:

我们知道,桶是有容量的,所以当桶的容量已满时,就装不下水了,这时就只有丢弃请求了。
利用这种思想,我们就可以写出一个简单的限流算法。
-
令牌桶算法
只能说有点像信号量机制。现在有一个令牌桶,这个桶是专门存放令牌的,每隔一段时间就向桶中丢入一个令牌(速度由我们指定)当新的请求到达时,将从桶中删除令牌,接着请求就可以通过并给到服务,但是如果桶中的令牌数量不足,那么不会删除令牌,而是让此数据包等待。

可以试想一下,当流量下降时,令牌桶中的令牌会逐渐积累,这样如果突然出现高并发,那么就能在短时间内拿到大量的令牌。
-
固定时间窗口算法
我们可以对某一个时间段内的请求进行统计和计数,比如在
14:15到14:16这一分钟内,请求量不能超过100,也就是一分钟之内不能超过100次请求,那么就可以像下面这样进行划分:
虽然这种模式看似比较合理,但是试想一下这种情况:
- 14:15:59的时候来了100个请求
- 14:16:01的时候又来了100个请求
出现上面这种情况,符合固定时间窗口算法的规则,所以这200个请求都能正常接受,但是,如果你反应比较快,应该发现了,我们其实希望的是60秒内只有100个请求,但是这种情况却是在3秒内出现了200个请求,很明显已经违背了我们的初衷。
因此,当遇到临界点时,固定时间窗口算法存在安全隐患。
-
滑动时间窗口算法
相对于固定窗口算法,滑动时间窗口算法更加灵活,它会动态移动窗口,重新进行计算:
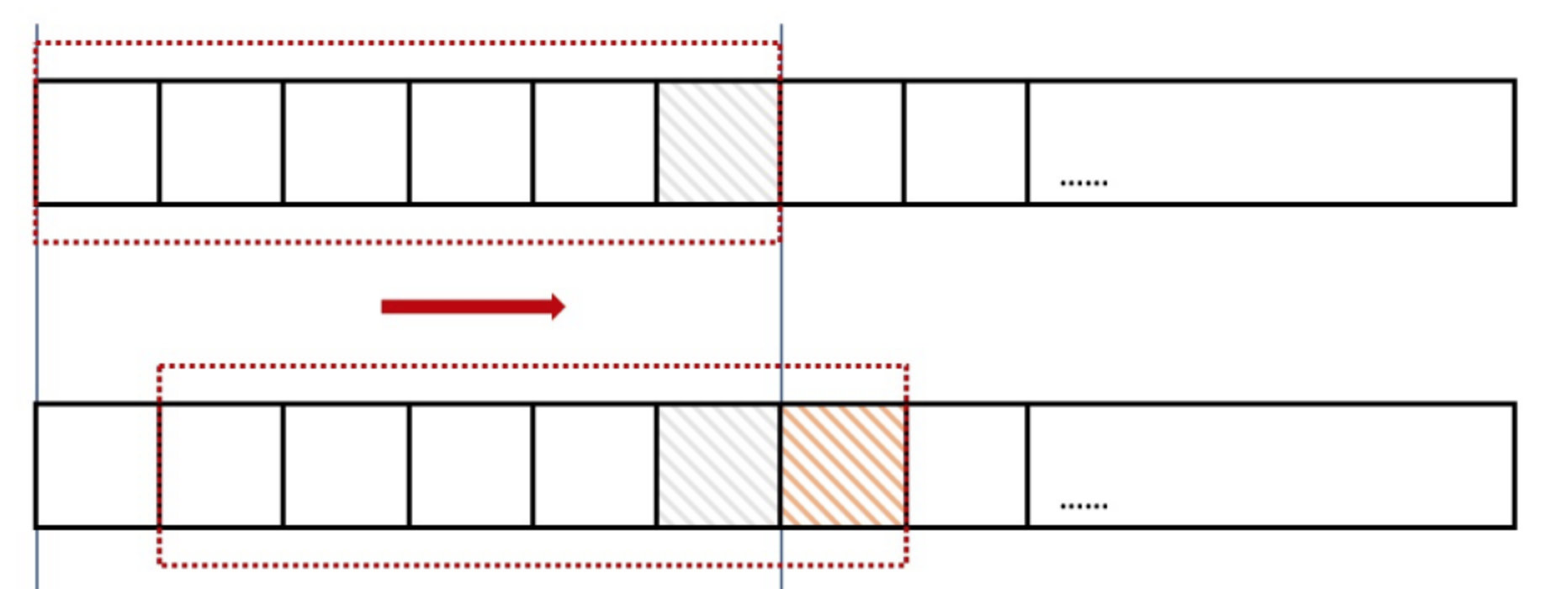
虽然这样能够避免固定时间窗口的临界问题,但是这样显然是比固定窗口更加耗时的。
好了,了解完了我们的限流策略和判定方法之后,我们在Sentinel中进行实际测试一下,打开管理页面的簇点链路模块:
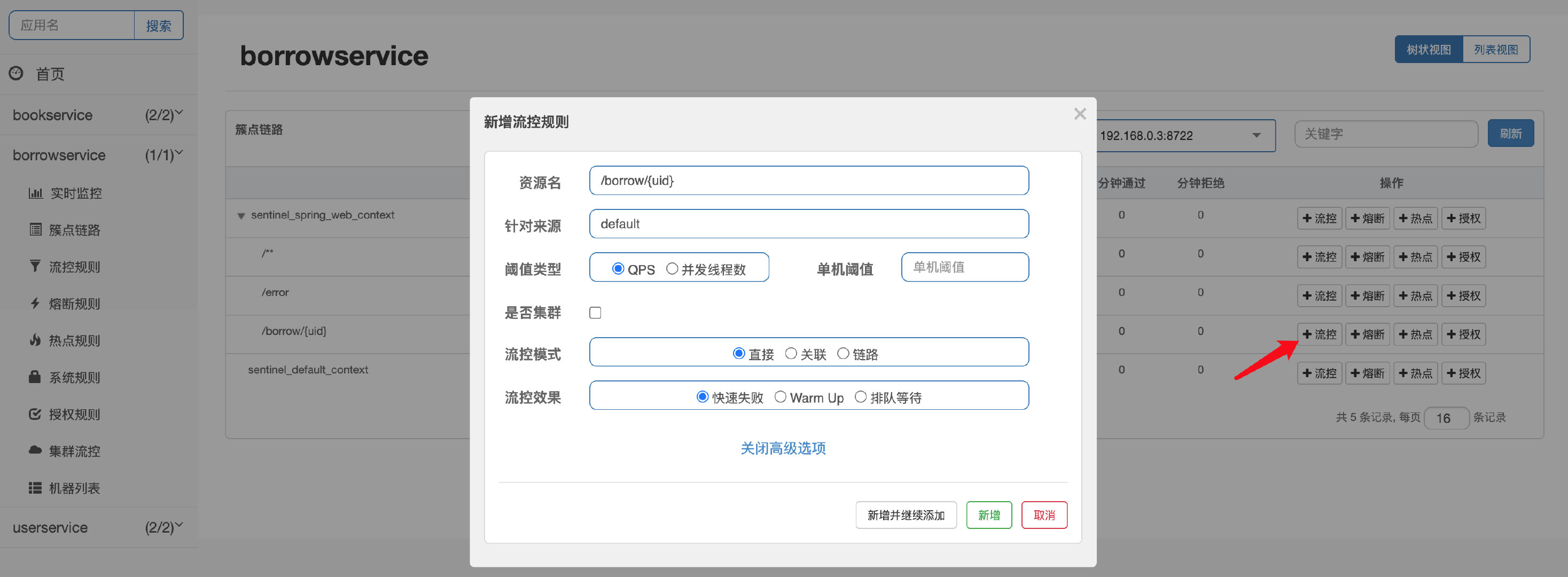
这里演示对我们的借阅接口进行限流,点击流控,会看到让我们添加流控规则:
- 阈值类型:QPS就是每秒钟的请求数量,并发线程数是按服务当前使用的线程数据进行统计的。
- 流控模式:当达到阈值时,流控的对象,这里暂时只用直接。
- 流控效果:就是我们上面所说的三种方案。
这里我们选择QPS、阈值设定为1,流控模式选择直接、流控效果选择快速失败,可以看到,当我们快速地进行请求时,会直接返回失败信息:

这里各位最好自行尝试一下其他的流控效果,熟悉和加深印象。
最后我们来看看这些流控模式有什么区别:
- 直接:只针对于当前接口。
- 关联:当其他接口超过阈值时,会导致当前接口被限流。
- 链路:更细粒度的限流,能精确到具体的方法。
我们首先来看看关联,比如现在我们对自带的/error接口进行限流:
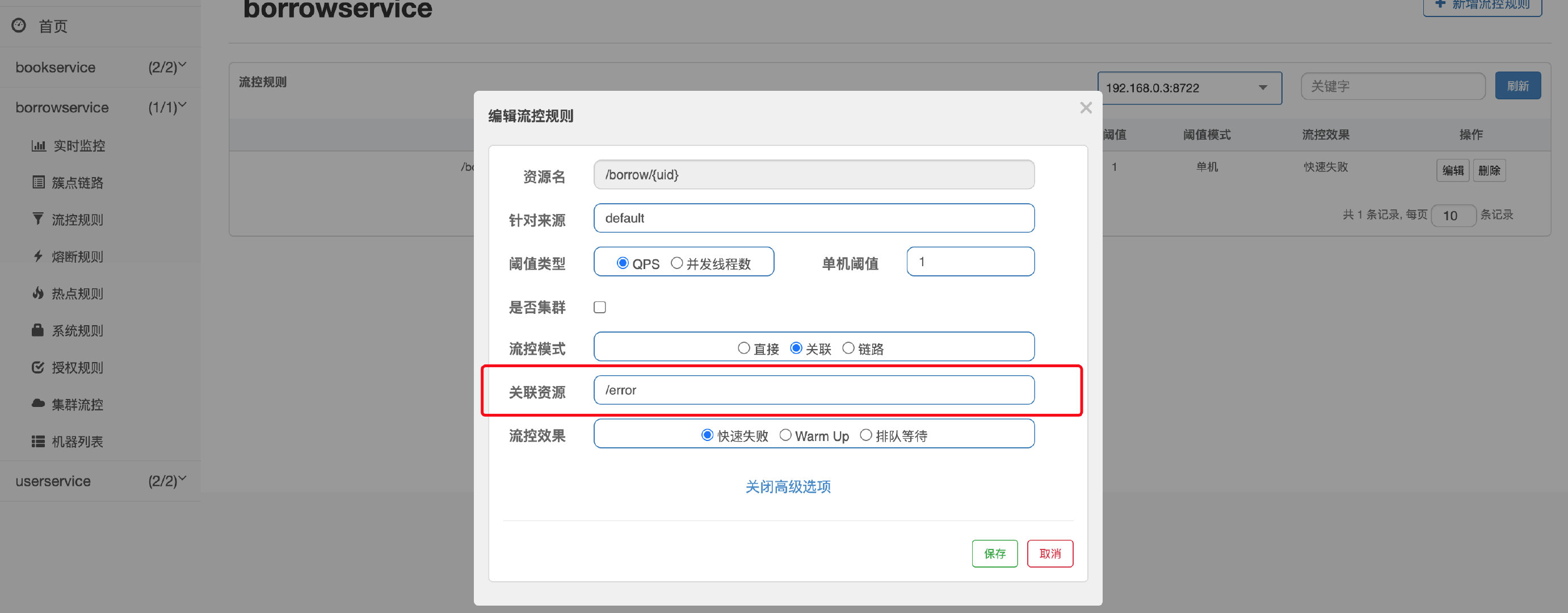
注意限流是作用于关联资源的,一旦发现关联资源超过阈值,那么就会对当前的资源进行限流,我们现在来测试一下,这里使用PostMan的Runner连续对关联资源发起请求:
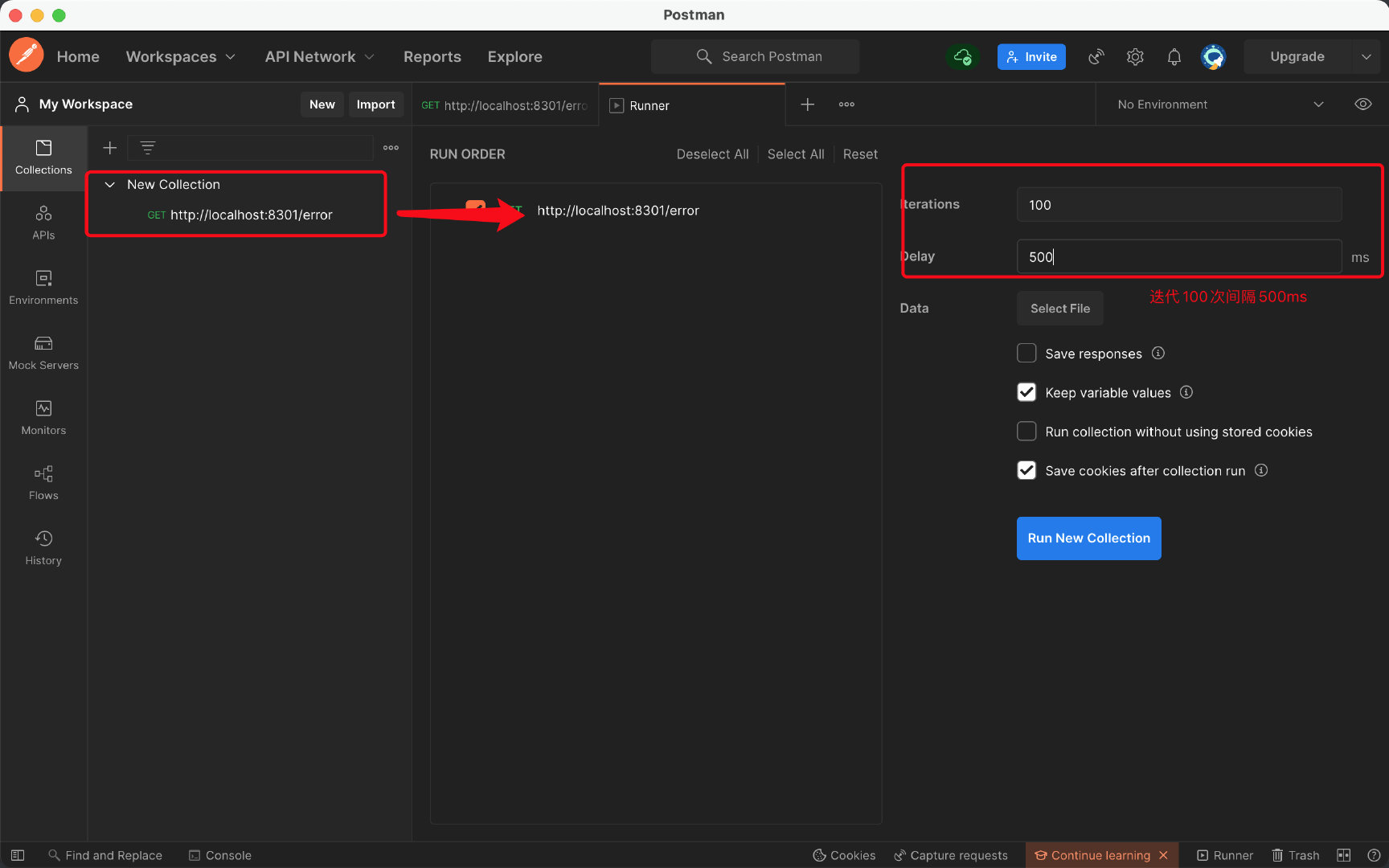
开启Postman,然后我们会发现借阅服务已经凉凉:

当我们关闭掉Postman的任务后,恢复正常。
最后我们来讲解一下链路模式,它能够更加精准的进行流量控制,链路流控模式指的是,当从指定接口过来的资源请求达到限流条件时,开启限流,这里得先讲解一下@SentinelResource的使用。
我们可以对某一个方法进行限流控制,无论是谁在何处调用了它,这里需要使用到@SentinelResource,一旦方法被标注,那么就会进行监控,比如我们这里创建两个请求映射,都来调用Service的被监控方法:
@RestController
public class BorrowController {
@Resource
BorrowService service;
@RequestMapping("/borrow/{uid}")
UserBorrowDetail findUserBorrows(@PathVariable("uid") int uid){
return service.getUserBorrowDetailByUid(uid);
}
@RequestMapping("/borrow2/{uid}")
UserBorrowDetail findUserBorrows2(@PathVariable("uid") int uid){
return service.getUserBorrowDetailByUid(uid);
}
}
@Service
public class BorrowServiceImpl implements BorrowService{
@Resource
BorrowMapper mapper;
@Resource
UserClient userClient;
@Resource
BookClient bookClient;
@Override
@SentinelResource("getBorrow")
//监控此方法,无论被谁执行都在监控范围内,这里给的value是自定义名称,这个注解可以加在任何方法上,包括Controller中的请求映射方法,跟HystrixCommand贼像
public UserBorrowDetail getUserBorrowDetailByUid(int uid) {
List<Borrow> borrow = mapper.getBorrowsByUid(uid);
User user = userClient.getUserById(uid);
List<Book> bookList = borrow
.stream()
.map(b -> bookClient.getBookById(b.getBid()))
.collect(Collectors.toList());
return new UserBorrowDetail(user, bookList);
}
}
接着添加配置:
spring:
application:
name: borrowservice
cloud:
sentinel:
transport:
dashboard: localhost:8858
# 关闭Context收敛,这样被监控方法可以进行不同链路的单独控制
web-context-unify: false
然后我们在Sentinel控制台中添加流控规则,注意是针对此方法,可以看到已经自动识别到borrow接口下调用了这个方法:
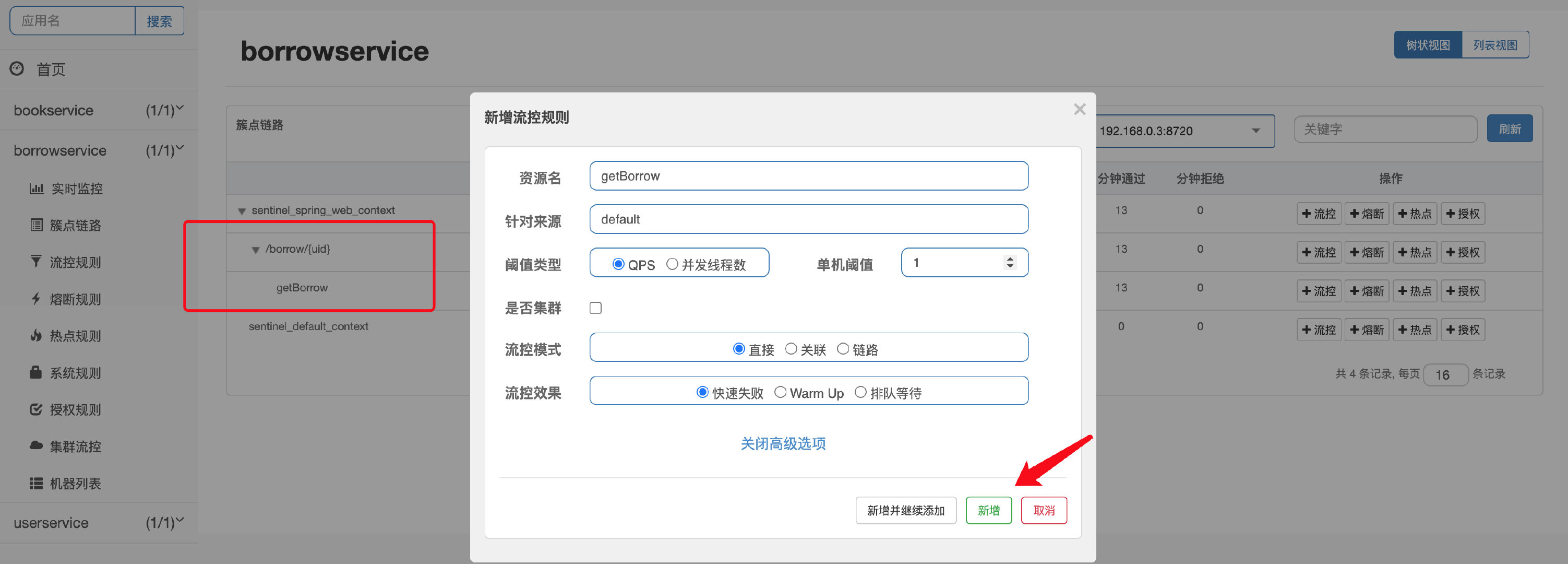
最后我们在浏览器中对这两个接口都进行测试,会发现,无论请求哪个接口,只要调用了Service中的getUserBorrowDetailByUid这个方法,都会被限流。注意限流的形式是后台直接抛出异常,至于怎么处理我们后面再说。
那么这个链路选项实际上就是决定只限流从哪个方向来的调用,比如我们只对borrow2这个接口对getUserBorrowDetailByUid方法的调用进行限流,那么我们就可以为其指定链路:

然后我们会发现,限流效果只对我们配置的链路接口有效,而其他链路是不会被限流的。
除了直接对接口进行限流规则控制之外,我们也可以根据当前系统的资源使用情况,决定是否进行限流:
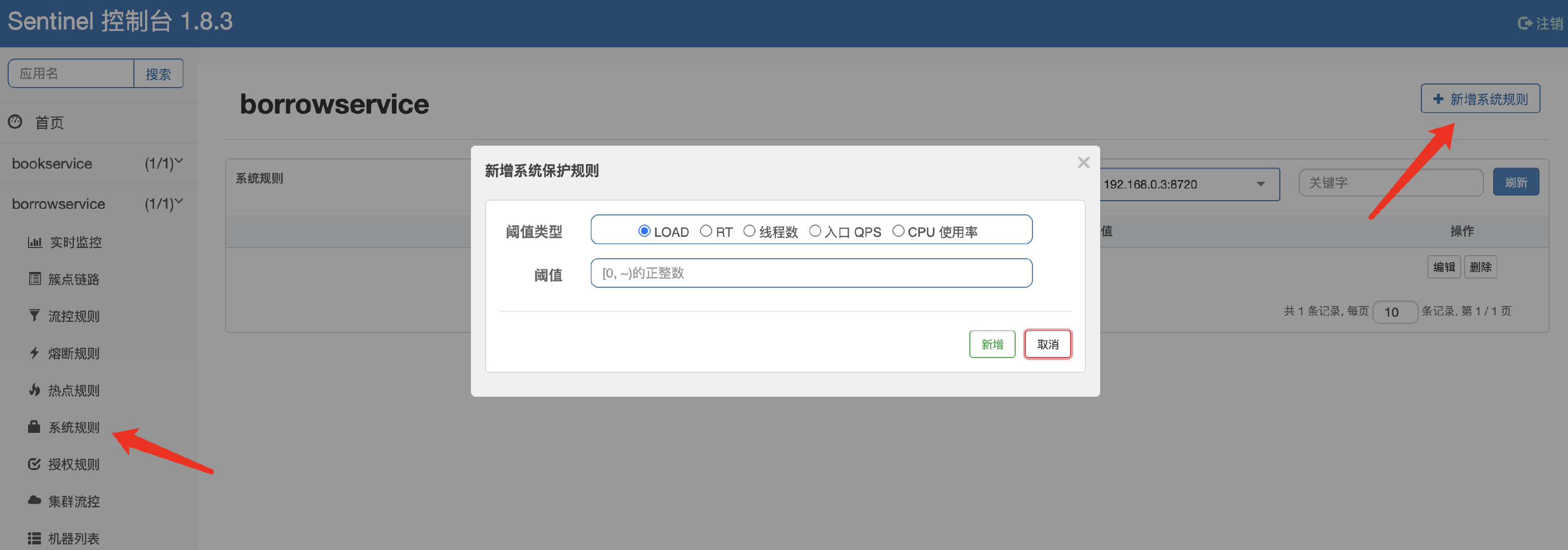
系统规则支持以下的模式:
- Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的
maxQps * minRt估算得出。设定参考值一般是CPU cores * 2.5。 - CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
这里就不进行演示了。
限流和异常处理
现在我们已经了解了如何进行限流操作,那么限流状态下的返回结果该怎么修改呢,我们看到被限流之后返回的是Sentinel默认的数据,现在我们希望自定义改如何操作?
这里我们先创建好被限流状态下需要返回的内容,定义一个请求映射:
@RequestMapping("/blocked")
JSONObject blocked(){
JSONObject object = new JSONObject();
object.put("code", 403);
object.put("success", false);
object.put("massage", "您的请求频率过快,请稍后再试!");
return object;
}
接着我们在配置文件中将此页面设定为限流页面:
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8858
# 将刚刚编写的请求映射设定为限流页面
block-page: /blocked
这样,当被限流时,就会被重定向到指定页面:

那么,对于方法级别的限流呢?经过前面的学习我们知道,当某个方法被限流时,会直接在后台抛出异常,那么这种情况我们该怎么处理呢,比如我们之前在Hystrix中可以直接添加一个替代方案,这样当出现异常时会直接执行我们的替代方法并返回,Sentinel也可以。
比如我们还是在getUserBorrowDetailByUid方法上进行配置:
@Override
@SentinelResource(value = "getBorrow", blockHandler = "blocked")
//指定blockHandler,也就是被限流之后的替代解决方案,这样就不会使用默认的抛出异常的形式了
public UserBorrowDetail getUserBorrowDetailByUid(int uid) {
List<Borrow> borrow = mapper.getBorrowsByUid(uid);
User user = userClient.getUserById(uid);
List<Book> bookList = borrow
.stream()
.map(b -> bookClient.getBookById(b.getBid()))
.collect(Collectors.toList());
return new UserBorrowDetail(user, bookList);
}
//替代方案,注意参数和返回值需要保持一致,并且参数最后还需要额外添加一个BlockException
public UserBorrowDetail blocked(int uid, BlockException e) {
return new UserBorrowDetail(null, Collections.emptyList());
}
可以看到,一旦被限流将执行替代方案,最后返回的结果就是:

注意blockHandler只能处理限流情况下抛出的异常,包括下面即将要介绍的热点参数限流也是同理,如果是方法本身抛出的其他类型异常,不在管控范围内,但是可以通过其他参数进行处理:
@RequestMapping("/test")
@SentinelResource(value = "test",
fallback = "except",
//fallback指定出现异常时的替代方案
exceptionsToIgnore = IOException.class)
//忽略那些异常,也就是说这些异常出现时不使用替代方案
String test(){
throw new RuntimeException("HelloWorld!");
}
//替代方法必须和原方法返回值和参数一致,最后可以添加一个Throwable作为参数接受异常
String except(Throwable t){
return t.getMessage();
}
这样,其他的异常也可以有替代方案了:

特别注意这种方式会在没有配置blockHandler的情况下,将Sentinel机制内(也就是限流的异常)的异常也一并处理了,如果配置了blockHandler,那么在出现限流时,依然只会执行blockHandler指定的替代方案(因为限流是在方法执行之前进行的)
热点参数限流
我们还可以对某一热点数据进行精准限流,比如在某一时刻,不同参数被携带访问的频率是不一样的:
- http://localhost:8301/test?a=10 访问100次
- http://localhost:8301/test?b=10 访问0次
- http://localhost:8301/test?c=10 访问3次
由于携带参数a的请求比较多,我们就可以只对携带参数a的请求进行限流。
这里我们创建一个新的测试请求映射:
@RequestMapping("/test")
@SentinelResource("test")
//注意这里需要添加@SentinelResource才可以,用户资源名称就使用这里定义的资源名称
String findUserBorrows2(@RequestParam(value = "a", required = false) int a,
@RequestParam(value = "b", required = false) int b,
@RequestParam(value = "c",required = false) int c) {
return "请求成功!a = "+a+", b = "+b+", c = "+c;
}
启动之后,我们在Sentinel里面进行热点配置:
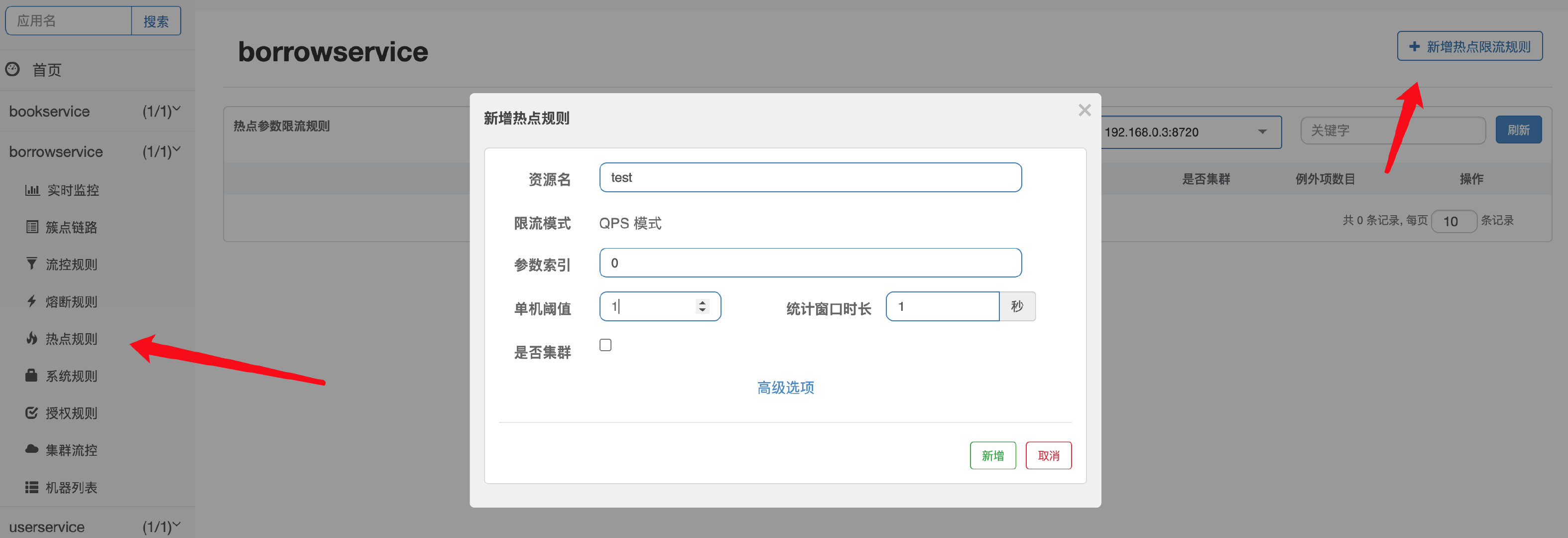
然后开始访问我们的测试接口,可以看到在携带参数a时,当访问频率超过设定值,就会直接被限流,这里是直接在后台抛出异常:

而我们使用其他参数或是不带a参数,那么就不会出现这种问题了:

除了直接对某个参数精准限流外,我们还可以对参数携带的指定值单独设定阈值,比如我们现在不仅希望对参数a限流,而且还希望当参数a的值为10时,QPS达到5再进行限流,那么就可以设定例外:
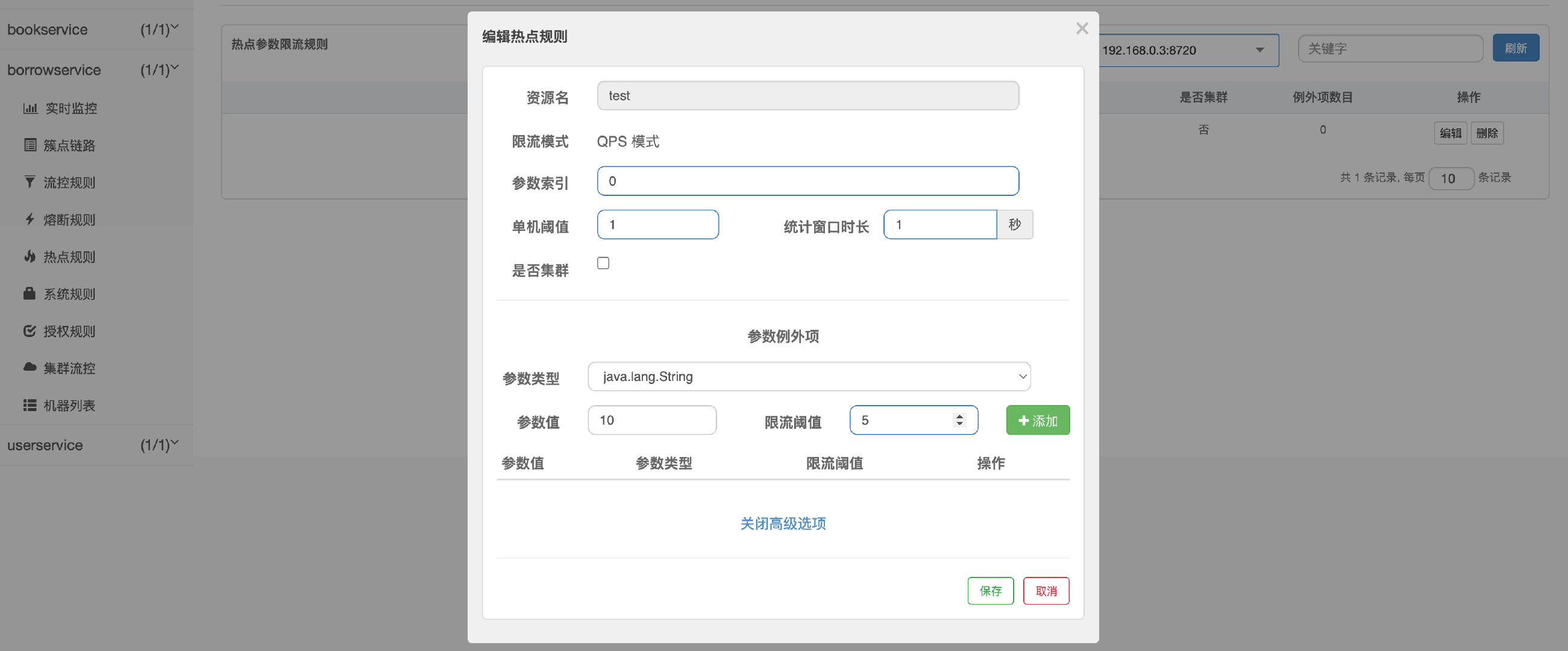
这样,当请求携带参数a,且参数a的值为10时,阈值将按照我们指定的特例进行计算。
服务熔断和降级
还记得我们前所说的服务降级吗,也就是说我们需要在整个微服务调用链路出现问题的时候,及时对服务进行降级,以防止问题进一步恶化。

那么,各位是否有思考过,如果在某一时刻,服务B出现故障(可能就卡在那里了),而这时服务A依然有大量的请求,在调用服务B,那么,由于服务A没办法再短时间内完成处理,新来的请求就会导致线程数不断地增加,这样,CPU的资源很快就会被耗尽。
那么要防止这种情况,就只能进行隔离了,这里我们提两种隔离方案:
-
线程池隔离
线程池隔离实际上就是对每个服务的远程调用单独开放线程池,比如服务A要调用服务B,那么只基于固定数量的线程池,这样即使在短时间内出现大量请求,由于没有线程可以分配,所以就不会导致资源耗尽了。

-
信号量隔离
信号量隔离是使用
Semaphore类实现的(如果不了解,可以观看本系列 并发编程篇 视频教程),思想基本上与上面是相同的,也是限定指定的线程数量能够同时进行服务调用,但是它相对于线程池隔离,开销会更小一些,使用效果同样优秀,也支持超时等。Sentinel也正是采用的这种方案实现隔离的。
好了,说回我们的熔断和降级,当下游服务因为某种原因变得不可用或响应过慢时,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务而是快速返回或是执行自己的替代方案,这便是服务降级。
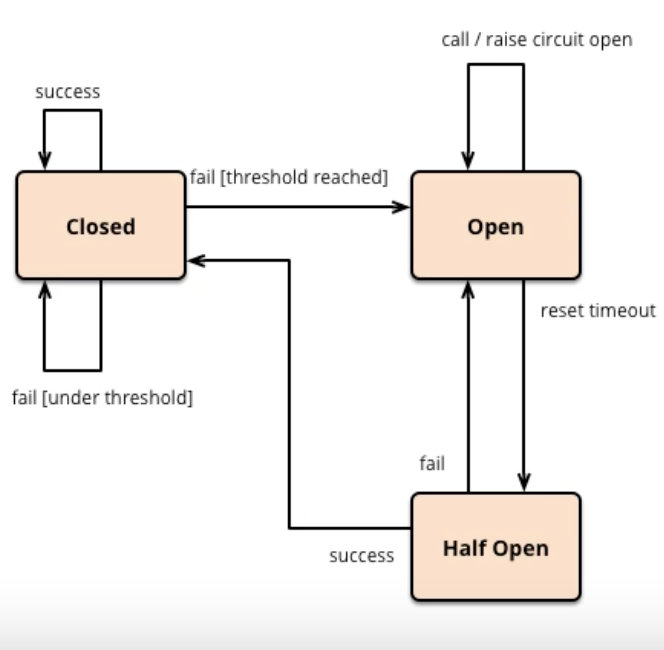
整个过程分为三个状态:
- 关闭:熔断器不工作,所有请求全部该干嘛干嘛。
- 打开:熔断器工作,所有请求一律降级处理。
- 半开:尝试进行一下下正常流程,要是还不行继续保持打开状态,否则关闭。
那么我们来看看Sentinel中如何进行熔断和降级操作,打开管理页面,我们可以自由新增熔断规则:
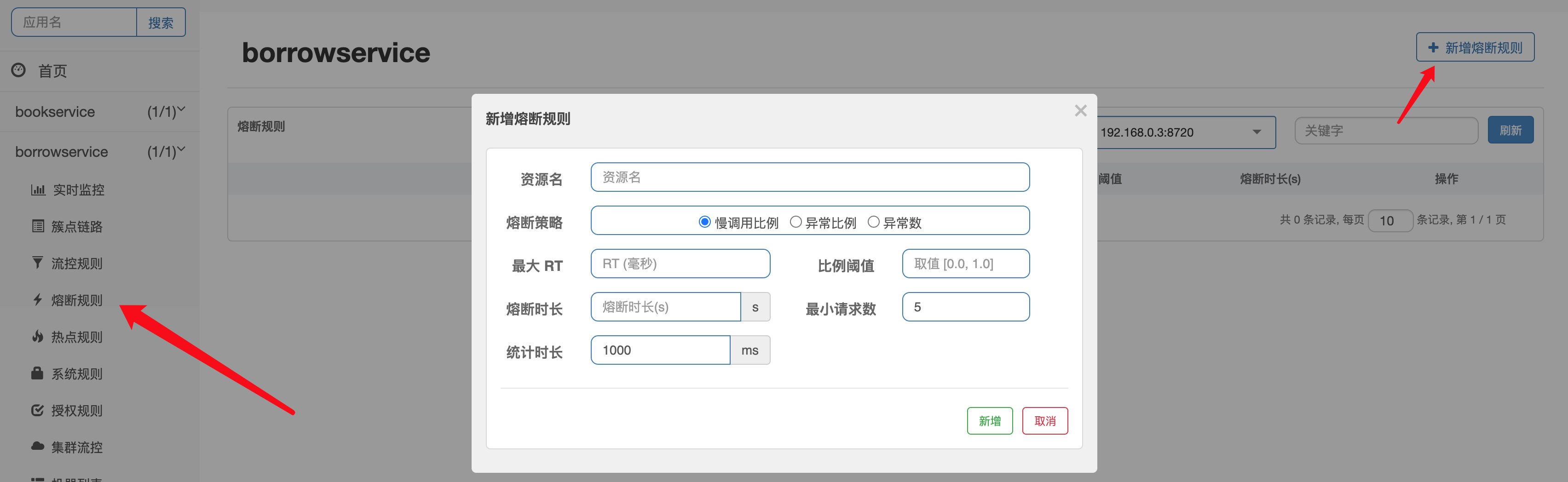
其中,熔断策略有三种模式:
-
**慢调用比例:**如果出现那种半天都处理不完的调用,有可能就是服务出现故障,导致卡顿,这个选项是按照最大响应时间(RT)进行判定,如果一次请求的处理时间超过了指定的RT,那么就被判定为
慢调用,在一个统计时长内,如果请求数目大于最小请求数目,并且被判定为慢调用的请求比例已经超过阈值,将触发熔断。经过熔断时长之后,将会进入到半开状态进行试探(这里和Hystrix一致)然后修改一下接口的执行,我们模拟一下慢调用:
@RequestMapping("/borrow2/{uid}") UserBorrowDetail findUserBorrows2(@PathVariable("uid") int uid) throws InterruptedException { Thread.sleep(1000); return null; }重启,然后我们创建一个新的熔断规则:
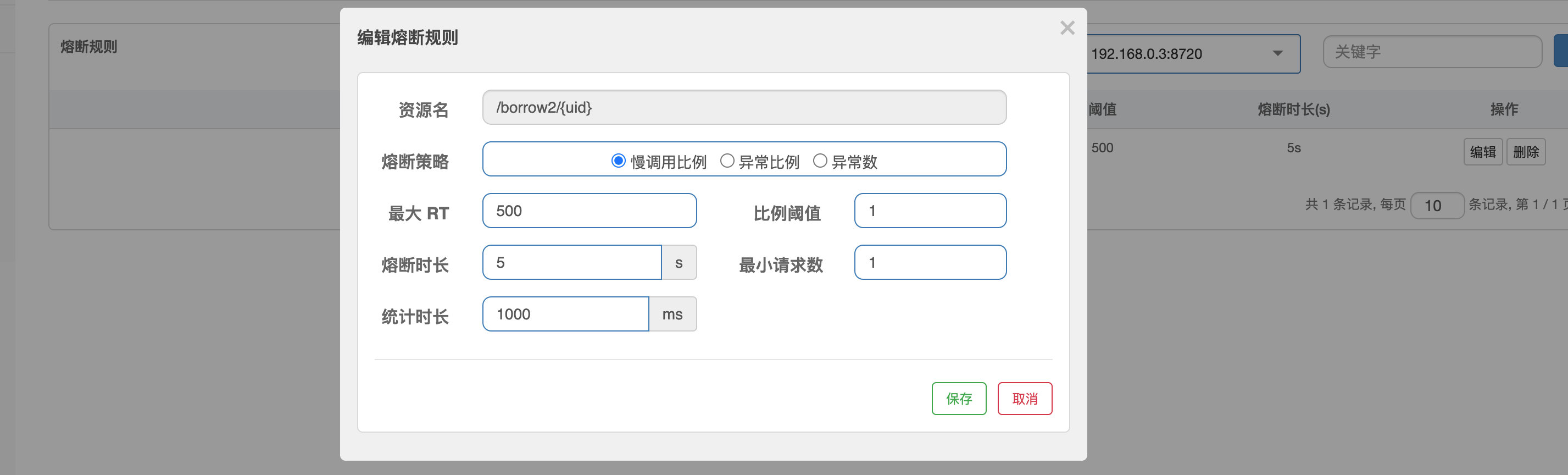
可以看到,超时直接触发了熔断,进入到阻止页面:

-
**异常比例:**这个与慢调用比例类似,不过这里判断的是出现异常的次数,与上面一样,我们也来进行一些小测试:
@RequestMapping("/borrow2/{uid}") UserBorrowDetail findUserBorrows2(@PathVariable("uid") int uid) { throw new RuntimeException(); }启动服务器,接着添加我们的熔断规则:
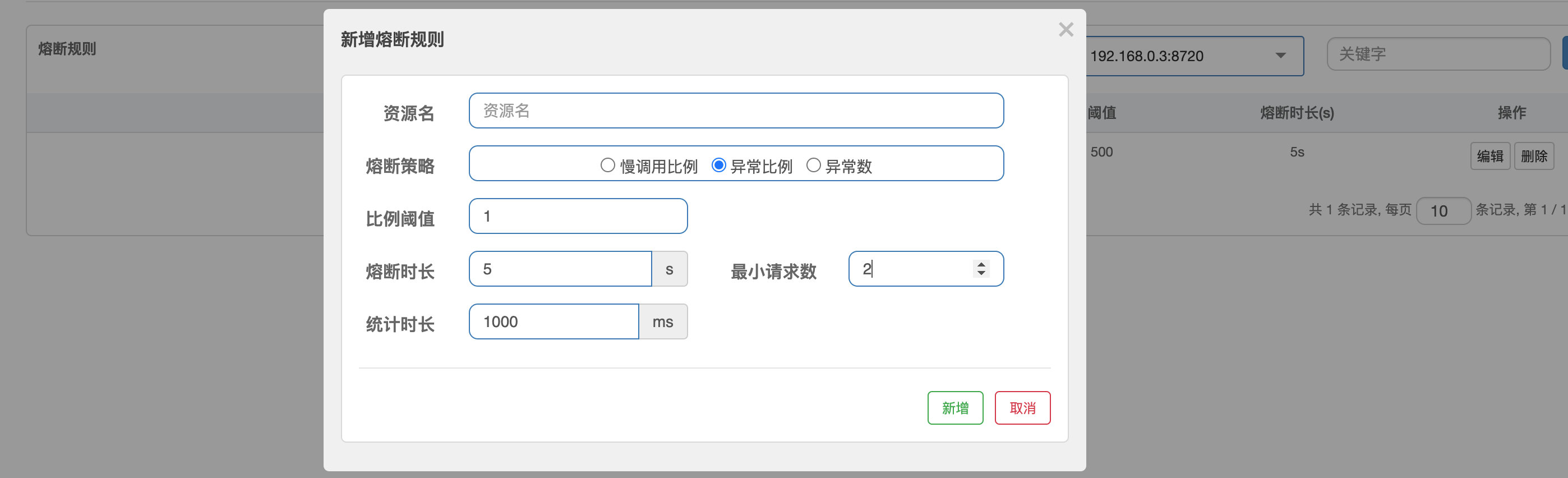
现在我们进行访问,会发现后台疯狂报错,然后就熔断了:


-
**异常数:**这个和上面的唯一区别就是,只要达到指定的异常数量,就熔断,这里我们修改一下熔断规则:
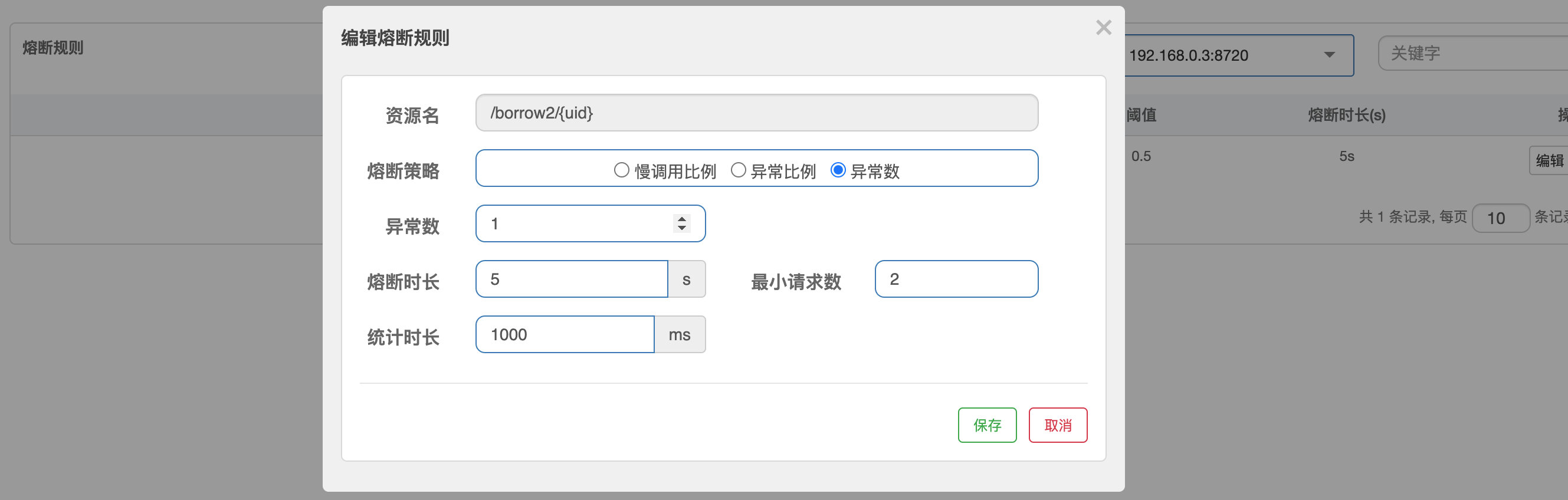
现在我们再次不断访问此接口,可以发现,效果跟之前其实是差不多的,只是判断的策略稍微不同罢了:

那么熔断规则如何设定我们了解了,那么,如何自定义服务降级呢?之前在使用Hystrix的时候,如果出现异常,可以执行我们的替代方案,Sentinel也是可以的。
同样的,我们只需要在@SentinelResource中配置blockHandler参数(那这里跟前面那个方法限流的配置不是一毛一样吗?没错,因为如果添加了@SentinelResource注解,那么这里会进行方法级别细粒度的限制,和之前方法级别限流一样,会在降级之后直接抛出异常,如果不添加则返回默认的限流页面,blockHandler的目的就是处理这种Sentinel机制上的异常,所以这里其实和之前的限流配置是一个道理,因此下面熔断配置也应该对value自定义名称的资源进行配置,才能作用到此方法上):
@RequestMapping("/borrow2/{uid}")
@SentinelResource(value = "findUserBorrows2", blockHandler = "test")
UserBorrowDetail findUserBorrows2(@PathVariable("uid") int uid) {
throw new RuntimeException();
}
UserBorrowDetail test(int uid, BlockException e){
return new UserBorrowDetail(new User(), Collections.emptyList());
}
接着我们对进行熔断配置,注意是对我们添加的@SentinelResource中指定名称的findUserBorrows2进行配置:
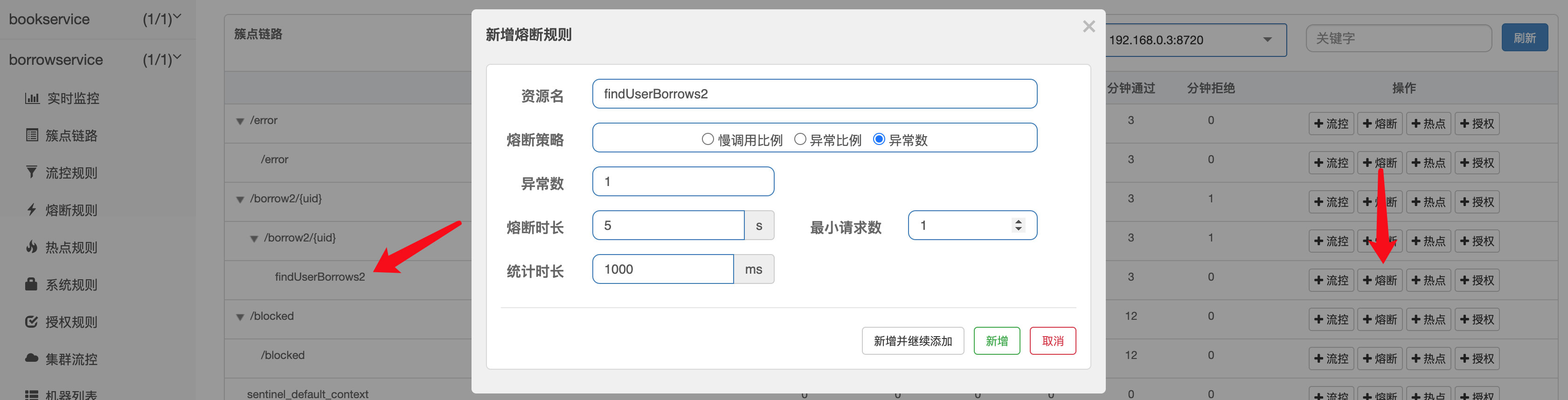
OK,可以看到熔断之后,服务降级之后的效果:

最后我们来看一下如何让Feign的也支持Sentinel,前面我们使用Hystrix的时候,就可以直接对Feign的每个接口调用单独进行服务降级,而使用Sentinel,也是可以的,首先我们需要在配置文件中开启支持:
feign:
sentinel:
enabled: true
之后的步骤其实和之前是一模一样的,首先创建实现类:
@Component
public class UserClientFallback implements UserClient{
@Override
public User getUserById(int uid) {
User user = new User();
user.setName("我是替代方案");
return user;
}
}
然后直接启动就可以了,中途的时候我们吧用户服务全部下掉,可以看到正常使用替代方案:

这样Feign的配置就OK了,那么传统的RestTemplate呢?我们可以使用@SentinelRestTemplate注解实现:
@Bean
@LoadBalanced
@SentinelRestTemplate(blockHandler = "handleException", blockHandlerClass = ExceptionUtil.class,
fallback = "fallback", fallbackClass = ExceptionUtil.class) //这里同样可以设定fallback等参数
public RestTemplate restTemplate() {
return new RestTemplate();
}
这里就不多做赘述了。

Seata与分布式事务
重难点内容,坑也多得离谱,最好保持跟UP一样的版本,**官方文档:**https://seata.io/zh-cn/docs/overview/what-is-seata.html
在前面的阶段中,我们学习过事务,还记得我们之前谈到的数据库事务的特性吗?
- **原子性:**一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- **一致性:**在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- **隔离性:**数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读已提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- **持久性:**事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
那么各位试想一下,在分布式环境下,有可能出现这样一个问题,比如我们下单购物,那么整个流程可能是这样的:先调用库存服务对库存进行减扣 -> 然后订单服务开始下单 -> 最后用户账户服务进行扣款,虽然看似是一个很简单的一个流程,但是如果没有事务的加持,很有可能会由于中途出错,比如整个流程中订单服务出现问题,那么就会导致库存扣了,但是实际上这个订单并没有生成,用户也没有付款。

上面这种情况时间就是一种多服务多数据源的分布式事务模型(比较常见),因此,为了解决这种情况,我们就得实现分布式事务,让这整个流程保证原子性。
SpringCloud Alibaba为我们提供了用于处理分布式事务的组件Seata。

Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
实际上,就是多了一个中间人来协调所有服务的事务。
项目环境搭建
这里我们对我们之前的图书管理系统进行升级:
- 每个用户最多只能同时借阅2本不同的书。
- 图书馆中所有的书都有3本。
- 用户借书流程:先调用图书服务书籍数量-1 -> 添加借阅记录 -> 调用用户服务用户可借阅数量-1
那么首先我们对数据库进行修改,这里为了简便,就直接在用户表中添加一个字段用于存储用户能够借阅的书籍数量:

然后修改书籍信息,也是直接添加一个字段用于记录剩余数量:

接着我们去编写一下对应的服务吧,首先是用户服务:
@Mapper
public interface UserMapper {
@Select("select * from DB_USER where uid = #{uid}")
User getUserById(int uid);
@Select("select book_count from DB_USER where uid = #{uid}")
int getUserBookRemain(int uid);
@Update("update DB_USER set book_count = #{count} where uid = #{uid}")
int updateBookCount(int uid, int count);
}
@Service
public class UserServiceImpl implements UserService {
@Resource
UserMapper mapper;
@Override
public User getUserById(int uid) {
return mapper.getUserById(uid);
}
@Override
public int getRemain(int uid) {
return mapper.getUserBookRemain(uid);
}
@Override
public boolean setRemain(int uid, int count) {
return mapper.updateBookCount(uid, count) > 0;
}
}
@RestController
public class UserController {
@Resource
UserService service;
@RequestMapping("/user/{uid}")
public User findUserById(@PathVariable("uid") int uid){
return service.getUserById(uid);
}
@RequestMapping("/user/remain/{uid}")
public int userRemain(@PathVariable("uid") int uid){
return service.getRemain(uid);
}
@RequestMapping("/user/borrow/{uid}")
public boolean userBorrow(@PathVariable("uid") int uid){
int remain = service.getRemain(uid);
return service.setRemain(uid, remain - 1);
}
}
然后是图书服务,其实跟用户服务差不多:
@Mapper
public interface BookMapper {
@Select("select * from DB_BOOK where bid = #{bid}")
Book getBookById(int bid);
@Select("select count from DB_BOOK
where bid = #{bid}")
int getRemain(int bid);
@Update("update DB_BOOK set count = #{count}
where bid = #{bid}")
int setRemain(int bid, int count);
}
@Service
public class BookServiceImpl implements BookService {
@Resource
BookMapper mapper;
@Override
public Book getBookById(int bid) {
return mapper.getBookById(bid);
}
@Override
public boolean setRemain(int bid, int count) {
return mapper.setRemain(bid, count) > 0;
}
@Override
public int getRemain(int bid) {
return mapper.getRemain(bid);
}
}
@RestController
public class BookController {
@Resource
BookService service;
@RequestMapping("/book/{bid}")
Book findBookById(@PathVariable("bid") int bid){
return service.getBookById(bid);
}
@RequestMapping("/book/remain/{bid}")
public int bookRemain(@PathVariable("bid") int uid){
return service.getRemain(uid);
}
@RequestMapping("/book/borrow/{bid}")
public boolean bookBorrow(@PathVariable("bid") int uid){
int remain = service.getRemain(uid);
return service.setRemain(uid, remain - 1);
}
}
最后完善我们的借阅服务:
@FeignClient(value = "userservice")
public interface UserClient {
@RequestMapping("/user/{uid}")
User getUserById(@PathVariable("uid") int uid);
@RequestMapping("/user/borrow/{uid}")
boolean userBorrow(@PathVariable("uid") int uid);
@RequestMapping("/user/remain/{uid}")
int userRemain(@PathVariable("uid") int uid);
}
@FeignClient("bookservice")
public interface BookClient {
@RequestMapping("/book/{bid}")
Book getBookById(@PathVariable("bid") int bid);
@RequestMapping("/book/borrow/{bid}")
boolean bookBorrow(@PathVariable("bid") int bid);
@RequestMapping("/book/remain/{bid}")
int bookRemain(@PathVariable("bid") int bid);
}
@RestController
public class BorrowController {
@Resource
BorrowService service;
@RequestMapping("/borrow/{uid}")
UserBorrowDetail findUserBorrows(@PathVariable("uid") int uid){
return service.getUserBorrowDetailByUid(uid);
}
@RequestMapping("/borrow/take/{uid}/{bid}")
JSONObject borrow(@PathVariable("uid") int uid,
@PathVariable("bid") int bid){
service.doBorrow(uid, bid);
JSONObject object = new JSONObject();
object.put("code", "200");
object.put("success", false);
object.put("message", "借阅成功!");
return object;
}
}
@Service
public class BorrowServiceImpl implements BorrowService{
@Resource
BorrowMapper mapper;
@Resource
UserClient userClient;
@Resource
BookClient bookClient;
@Override
public UserBorrowDetail getUserBorrowDetailByUid(int uid) {
List<Borrow> borrow = mapper.getBorrowsByUid(uid);
User user = userClient.getUserById(uid);
List<Book> bookList = borrow
.stream()
.map(b -> bookClient.getBookById(b.getBid()))
.collect(Collectors.toList());
return new UserBorrowDetail(user, bookList);
}
@Override
public boolean doBorrow(int uid, int bid) {
//1. 判断图书和用户是否都支持借阅
if(bookClient.bookRemain(bid) < 1)
throw new RuntimeException("图书数量不足");
if(userClient.userRemain(uid) < 1)
throw new RuntimeException("用户借阅量不足");
//2. 首先将图书的数量-1
if(!bookClient.bookBorrow(bid))
throw new RuntimeException("在借阅图书时出现错误!");
//3. 添加借阅信息
if(mapper.getBorrow(uid, bid) != null)
throw new RuntimeException("此书籍已经被此用户借阅了!");
if(mapper.addBorrow(uid, bid) <= 0)
throw new RuntimeException("在录入借阅信息时出现错误!");
//4. 用户可借阅-1
if(!userClient.userBorrow(uid))
throw new RuntimeException("在借阅时出现错误!");
//完成
return true;
}
}
这样,只要我们的图书借阅过程中任何一步出现问题,都会抛出异常。
我们来测试一下:

再次尝试借阅,后台会直接报错:

抛出异常,但是我们发现一个问题,借阅信息添加失败了,但是图书的数量依然被-1,也就是说正常情况下,我们是希望中途出现异常之后,之前的操作全部回滚的:

而这里由于是在另一个服务中进行的数据库操作,所以传统的@Transactional注解无效,这时就得借助Seata提供分布式事务了。
分布式事务解决方案
要开始实现分布式事务,我们得先从理论上开始下手,我们来了解一下常用的分布式事务解决方案。
-
XA分布式事务协议 - 2PC(两阶段提交实现)
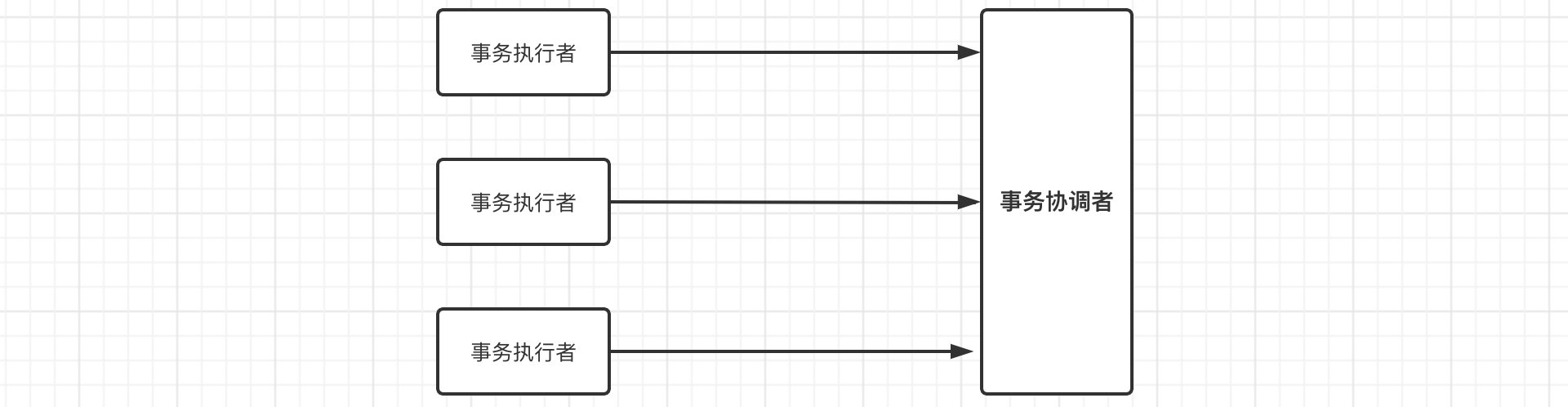
这里的PC实际上指的是Prepare和Commit,也就是说它分为两个阶段,一个是准备一个是提交,整个过程的参与者一共有两个角色,一个是事务的执行者,一个是事务的协调者,实际上整个分布式事务的运作都需要依靠协调者来维持:
在准备和提交阶段,会进行:
-
准备阶段:
一个分布式事务是由协调者来开启的,首先协调者会向所有的事务执行者发送事务内容,等待所有的事务执行者答复。
各个事务执行者开始执行事务操作,但是不进行提交,并将undo和redo信息记录到事务日志中。
如果事务执行者执行事务成功,那么就告诉协调者成功Yes,否则告诉协调者失败No,不能提交事务。
-
提交阶段:
当所有的执行者都反馈完成之后,进入第二阶段。
协调者会检查各个执行者的反馈内容,如果所有的执行者都返回成功,那么就告诉所有的执行者可以提交事务了,最后再释放锁资源。
如果有至少一个执行者返回失败或是超时,那么就让所有的执行者都回滚,分布式事务执行失败。
虽然这种方式看起来比较简单,但是存在以下几个问题:
- 事务协调者是非常核心的角色,一旦出现问题,将导致整个分布式事务不能正常运行。
- 如果提交阶段发生网络问题,导致某些事务执行者没有收到协调者发来的提交命令,将导致某些执行者提交某些执行者没提交,这样肯定是不行的。
-
-
XA分布式事务协议 - 3PC(三阶段提交实现)
三阶段提交是在二阶段提交基础上的改进版本,主要是加入了超时机制,同时在协调者和执行者中都引入了超时机制。
三个阶段分别进行:
-
CanCommit阶段:
协调者向执行者发送CanCommit请求,询问是否可以执行事务提交操作,然后开始等待执行者的响应。
执行者接收到请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态,否则返回No
-
PreCommit阶段:
协调者根据执行者的反应情况来决定是否可以进入第二阶段事务的PreCommit操作。
如果所有的执行者都返回Yes,则协调者向所有执行者发送PreCommit请求,并进入Prepared阶段,执行者接收到请求后,会执行事务操作,并将undo和redo信息记录到事务日志中,如果成功执行,则返回成功响应。
如果所有的执行者至少有一个返回No,则协调者向所有执行者发送abort请求,所有的执行者在收到请求或是超过一段时间没有收到任何请求时,会直接中断事务。
-
DoCommit阶段:
该阶段进行真正的事务提交。
协调者接收到所有执行者发送的成功响应,那么他将从PreCommit状态进入到DoCommit状态,并向所有执行者发送doCommit请求,执行者接收到doCommit请求之后,开始执行事务提交,并在完成事务提交之后释放所有事务资源,并最后向协调者发送确认响应,协调者接收到所有执行者的确认响应之后,完成事务(如果因为网络问题导致执行者没有收到doCommit请求,执行者会在超时之后直接提交事务,虽然执行者只是猜测协调者返回的是doCommit请求,但是因为前面的两个流程都正常执行,所以能够在一定程度上认为本次事务是成功的,因此会直接提交)
协调者没有接收至少一个执行者发送的成功响应(也可能是响应超时),那么就会执行中断事务,协调者会向所有执行者发送abort请求,执行者接收到abort请求之后,利用其在PreCommit阶段记录的undo信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源,执行者完成事务回滚之后,向协调者发送确认消息, 协调者接收到参与者反馈的确认消息之后,执行事务的中断。
相比两阶段提交,三阶段提交的优势是显而易见的,当然也有缺点:
- 3PC在2PC的第一阶段和第二阶段中插入一个准备阶段,保证了在最后提交阶段之前各参与节点的状态是一致的。
- 一旦参与者无法及时收到来自协调者的信息之后,会默认执行Commit,这样就不会因为协调者单方面的故障导致全局出现问题。
- 但是我们知道,实际上超时之后的Commit决策本质上就是一个赌注罢了,如果此时协调者发送的是abort请求但是超时未接收,那么就会直接导致数据一致性问题。
-
-
TCC(补偿事务)
补偿事务TCC就是Try、Confirm、Cancel,它对业务有侵入性,一共分为三个阶段,我们依次来解读一下。
-
Try阶段:
比如我们需要在借书时,将书籍的库存
-1,并且用户的借阅量也-1,但是这个操作,除了直接对库存和借阅量进行修改之外,还需要将减去的值,单独存放到冻结表中,但是此时不会创建借阅信息,也就是说只是预先把关键的东西给处理了,预留业务资源出来。 -
Confirm阶段:
如果Try执行成功无误,那么就进入到Confirm阶段,接着之前,我们就该创建借阅信息了,只能使用Try阶段预留的业务资源,如果创建成功,那么就对Try阶段冻结的值,进行解冻,整个流程就完成了。当然,如果失败了,那么进入到Cancel阶段。
-
Cancel阶段:
不用猜了,那肯定是把冻结的东西还给人家,因为整个借阅操作压根就没成功。就像你付了款买了东西但是网络问题,导致交易失败,钱不可能不还给你吧。
跟XA协议相比,TCC就没有协调者这一角色的参与了,而是自主通过上一阶段的执行情况来确保正常,充分利用了集群的优势,性能也是有很大的提升。但是缺点也很明显,它与业务具有一定的关联性,需要开发者去编写更多的补偿代码,同时并不一定所有的业务流程都适用于这种形式。
-
Seata机制简介
前面我们了解了一些分布式事务的解决方案,那么我们来看一下Seata是如何进行分布式事务的处理的。
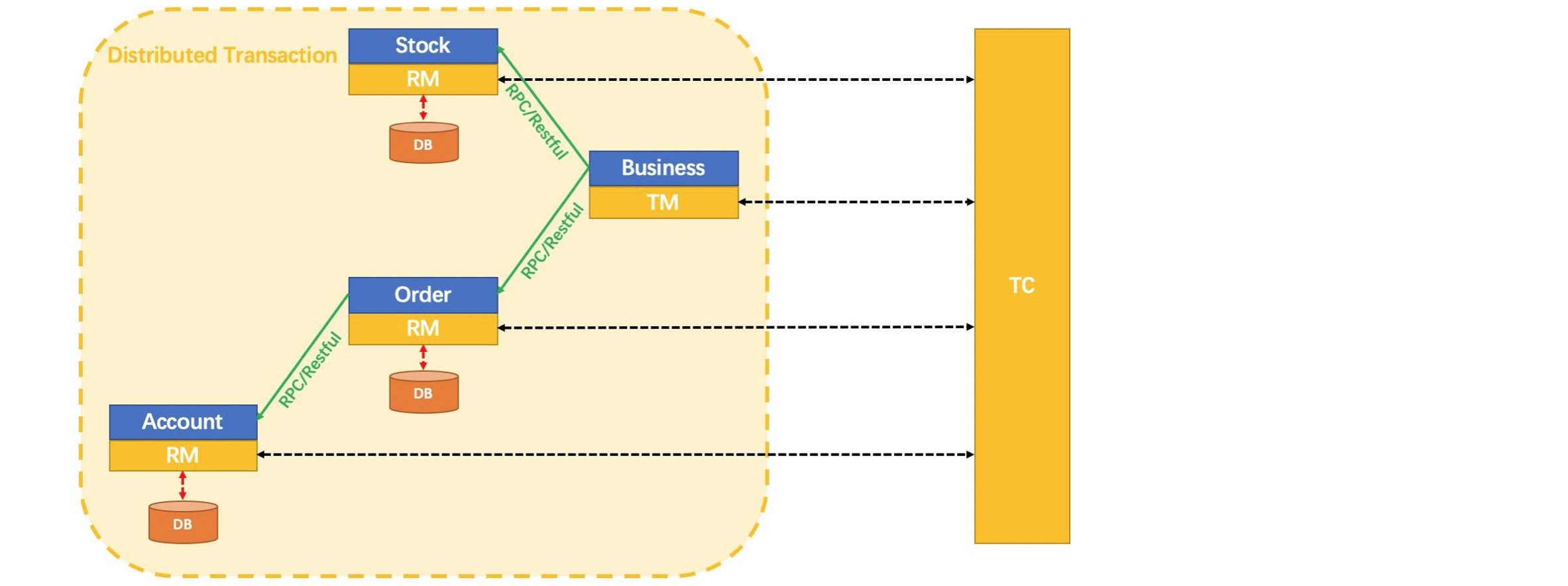
官网给出的是这样的一个架构图,那么图中的RM、TM、TC代表着什么意思呢?
- RM(Resource Manager):用于直接执行本地事务的提交和回滚。
- TM(Transaction Manager):TM是分布式事务的核心管理者。比如现在我们需要在借阅服务中开启全局事务,来让其自身、图书服务、用户服务都参与进来,也就是说一般全局事务发起者就是TM。
- TC(Transaction Manager)这个就是我们的Seata服务器,用于全局控制,比如在XA模式下就是一个协调者的角色,而一个分布式事务的启动就是由TM向TC发起请求,TC再来与其他的RM进行协调操作。
TM请求TC开启一个全局事务,TC会生成一个XID作为该全局事务的编号,XID会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起;RM请求TC将本地事务注册为全局事务的分支事务,通过全局事务的XID进行关联;TM请求TC告诉XID对应的全局事务是进行提交还是回滚;TC驱动RM将XID对应的自己的本地事务进行提交还是回滚;
Seata支持4种事务模式,官网文档:https://seata.io/zh-cn/docs/overview/what-is-seata.html
-
AT:本质上就是2PC的升级版,在 AT 模式下,用户只需关心自己的 “业务SQL”
- 一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
- 二阶段如果确认提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可,当然如果需要回滚,那么就用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
-
TCC:和我们上面讲解的思路是一样的。
-
XA:同上,但是要求数据库本身支持这种模式才可以。
-
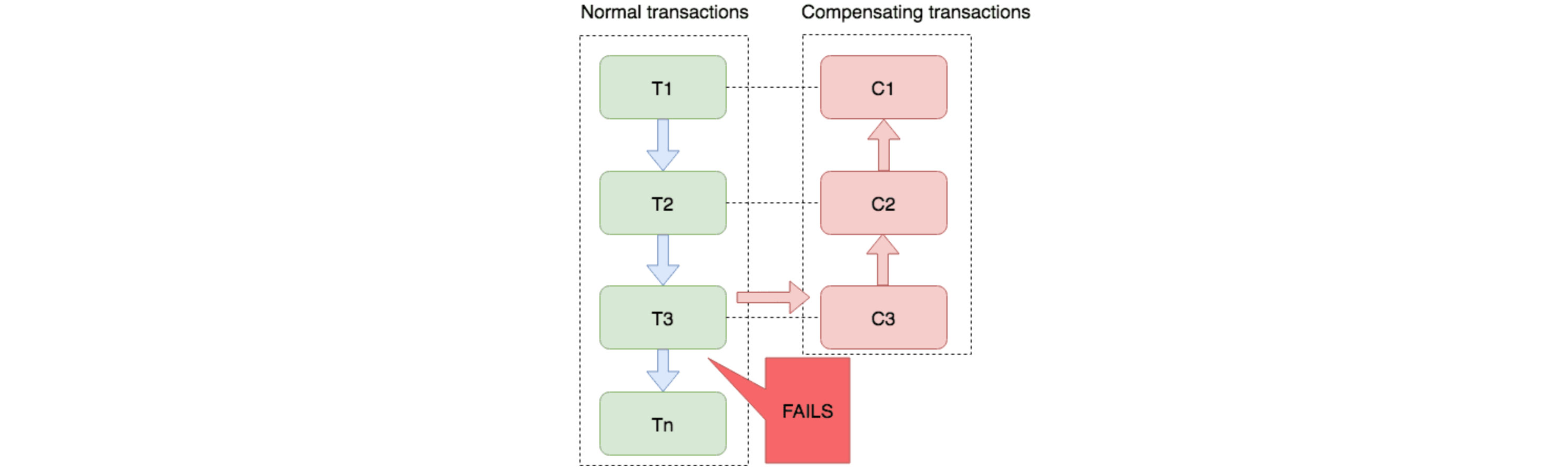
Saga:用于处理长事务,每个执行者需要实现事务的正向操作和补偿操作:
那么,以AT模式为例,我们的程序如何才能做到不对业务进行侵入的情况下实现分布式事务呢?实际上,Seata客户端,是通过对数据源进行代理实现的,使用的是DataSourceProxy类,所以在程序这边,我们只需要将对应的代理类注册为Bean即可(0.9版本之后支持自动进行代理,不用我们手动操作)
接下来,我们就以AT模式为例进行讲解。
使用file模式部署
Seata也是以服务端形式进行部署的,然后每个服务都是客户端,服务端下载地址:https://github.com/seata/seata/releases/download/v1.4.2/seata-server-1.4.2.zip
把源码也下载一下:https://github.com/seata/seata/archive/refs/heads/develop.zip
下载完成之后,放入到IDEA项目目录中,添加启动配置,这里端口使用8868:

Seata服务端支持本地部署或是基于注册发现中心部署(比如Nacos、Eureka等),这里我们首先演示一下最简单的本地部署,不需要对Seata的配置文件做任何修改。
Seata存在着事务分组机制:
- 事务分组:seata的资源逻辑,可以按微服务的需要,在应用程序(客户端)对自行定义事务分组,每组取一个名字。
- 集群:seata-server服务端一个或多个节点组成的集群cluster。 应用程序(客户端)使用时需要指定事务逻辑分组与Seata服务端集群(默认为default)的映射关系。
为啥要设计成通过事务分组再直接映射到集群?干嘛不直接指定集群呢?获取事务分组到映射集群的配置。这样设计后,事务分组可以作为资源的逻辑隔离单位,出现某集群故障时可以快速failover,只切换对应分组,可以把故障缩减到服务级别,但前提也是你有足够server集群。
接着我们需要将我们的各个服务作为Seate的客户端,只需要导入依赖即可:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
然后添加配置:
seata:
service:
vgroup-mapping:
# 这里需要对事务组做映射,默认的分组名为 应用名称-seata-service-group,将其映射到default集群
# 这个很关键,一定要配置对,不然会找不到服务
bookservice-seata-service-group: default
grouplist:
default: localhost:8868
这样就可以直接启动了,但是注意现在只是单纯地连接上,并没有开启任何的分布式事务。
现在我们接着来配置开启分布式事务,首先在启动类添加注解,此注解会添加一个后置处理器将数据源封装为支持分布式事务的代理数据源(虽然官方表示配置文件中已经默认开启了自动代理,但是UP主实测1.4.2版本下只能打注解的方式才能生效):
@EnableAutoDataSourceProxy
@SpringBootApplication
public class BookApplication {
public static void main(String[] args) {
SpringApplication.run(BookApplication.class, args);
}
}
接着我们需要在开启分布式事务的方法上添加@GlobalTransactional注解:
@GlobalTransactional
@Override
public boolean doBorrow(int uid, int bid) {
//这里打印一下XID看看,其他的服务业添加这样一个打印,如果一会都打印的是同一个XID,表示使用的就是同一个事务
System.out.println(RootContext.getXID());
if(bookClient.bookRemain(bid) < 1)
throw new RuntimeException("图书数量不足");
if(userClient.userRemain(uid) < 1)
throw new RuntimeException("用户借阅量不足");
if(!bookClient.bookBorrow(bid))
throw new RuntimeException("在借阅图书时出现错误!");
if(mapper.getBorrow(uid, bid) != null)
throw new RuntimeException("此书籍已经被此用户借阅了!");
if(mapper.addBorrow(uid, bid) <= 0)
throw new RuntimeException("在录入借阅信息时出现错误!");
if(!userClient.userBorrow(uid))
throw new RuntimeException("在借阅时出现错误!");
return true;
}
还没结束,我们前面说了,Seata会分析修改数据的sql,同时生成对应的反向回滚SQL,这个回滚记录会存放在undo_log 表中。所以要求每一个Client 都有一个对应的undo_log表(也就是说每个服务连接的数据库都需要创建这样一个表,这里由于我们三个服务都用的同一个数据库,所以说就只用在这个数据库中创建undo_log表即可),表SQL定义如下:
CREATE TABLE `undo_log`
(
`id`
BIGINT(20)
NOT NULL AUTO_INCREMENT,
`branch_id`
BIGINT(20)
NOT NULL,
`xid`
VARCHAR(100) NOT NULL,
`context`
VARCHAR(128) NOT NULL,
`rollback_info` LONGBLOB
NOT NULL,
`log_status`
INT(11)
NOT NULL,
`log_created`
DATETIME
NOT NULL,
`log_modified`
DATETIME
NOT NULL,
`ext`
VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8;
创建完成之后,我们现在就可以启动三个服务了,我们来测试一下当出现异常的时候是不是会正常回滚:


首先第一次肯定是正常完成借阅操作的,接着我们再次进行请求,肯定会出现异常:

如果能在栈追踪信息中看到seata相关的包,那么说明分布式事务已经开始工作了,通过日志我们可以看到,出现了回滚操作:

并且数据库中确实是回滚了扣除操作:

这样,我们就通过Seata简单地实现了分布式事务。
使用nacos模式部署
前面我们实现了本地Seata服务的file模式部署,现在我们来看看如何让其配合Nacos进行部署,利用Nacos的配置管理和服务发现机制,Seata能够更好地工作。
我们先单独为Seata配置一个命名空间:

我们打开conf目录中的registry.conf配置文件:
registry {
# 注册配置
# 可以看到这里可以选择类型,默认情况下是普通的file类型,也就是本地文件的形式进行注册配置
# 支持的类型如下,对应的类型在下面都有对应的配置
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
# 采用nacos方式会将seata服务端也注册到nacos中,这样客户端就可以利用服务发现自动找到seata服务
# 就不需要我们手动指定IP和端口了,不过看似方便,坑倒是不少,后面再说
nacos {
# 应用名称,这里默认就行
application = "seata-server"
# Nacos服务器地址
serverAddr = "localhost:8848"
# 这里使用的是SEATA_GROUP组,一会注册到Nacos中就是这个组
group = "SEATA_GROUP"
# 这里就使用我们上面单独为seata配置的命名空间,注意填的是ID
namespace = "89fc2145-4676-48b8-9edd-29e867879bcb"
# 集群名称,这里还是使用default
cluster = "default"
# Nacos的用户名和密码
username = "nacos"
password = "nacos"
}
#...
注册信息配置完成之后,接着我们需要将配置文件也放到Nacos中,让Nacos管理配置,这样我们就可以对配置进行热更新了,一旦环境需要变化,只需要直接在Nacos中修改即可。
config {
# 这里我们也使用nacos
# file、nacos 、apollo、zk、consul、etcd3
type = "nacos"
nacos {
# 跟上面一样的配法
serverAddr = "127.0.0.1:8848"
namespace = "89fc2145-4676-48b8-9edd-29e867879bcb"
group = "SEATA_GROUP"
username = "nacos"
password = "nacos"
# 这个不用改,默认就行
dataId = "seataServer.properties"
}
接着,我们需要将配置导入到Nacos中,我们打开一开始下载的源码script/config-center/nacos目录,这是官方提供的上传脚本,我们直接运行即可(windows下没对应的bat就很蛋疼,可以使用git命令行来运行一下),这里我们使用这个可交互的版本:
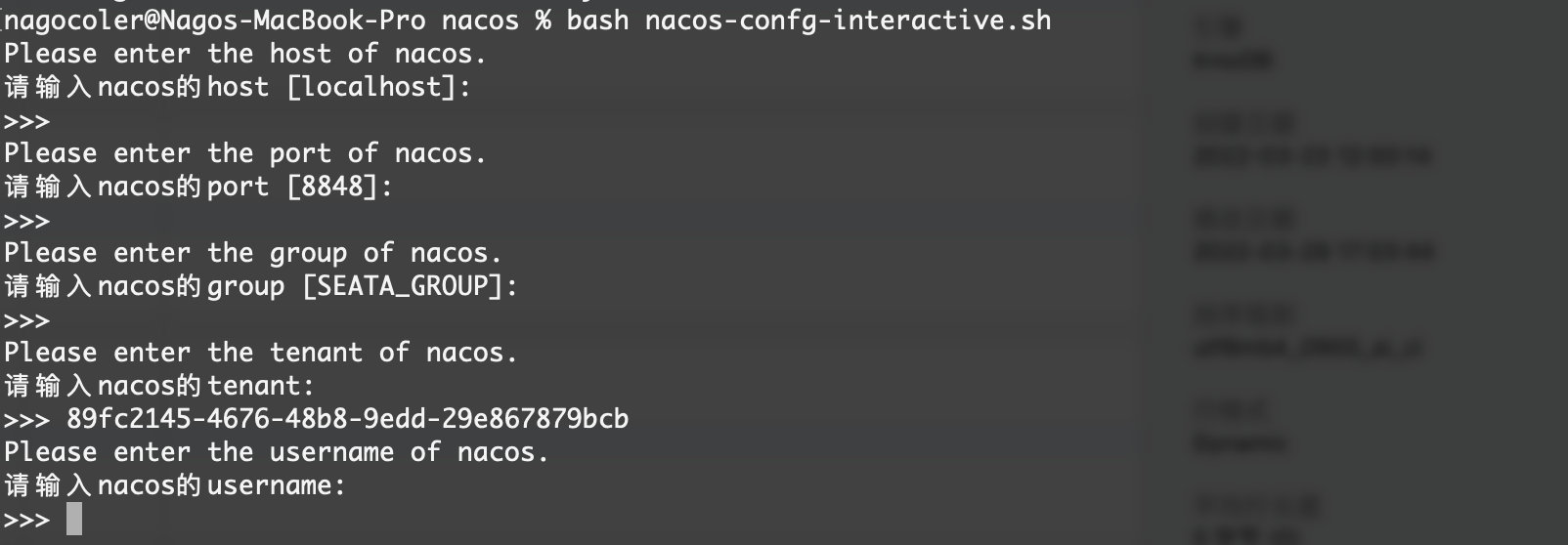
按照提示输入就可以了,不输入就使用的默认值,不知道为啥最新版本有四个因为参数过长还导入失败了,就离谱,不过不影响。
导入成功之后,可以在对应的命名空间下看到对应的配置(为啥非要一个一个配置项单独搞,就不能写一起吗):
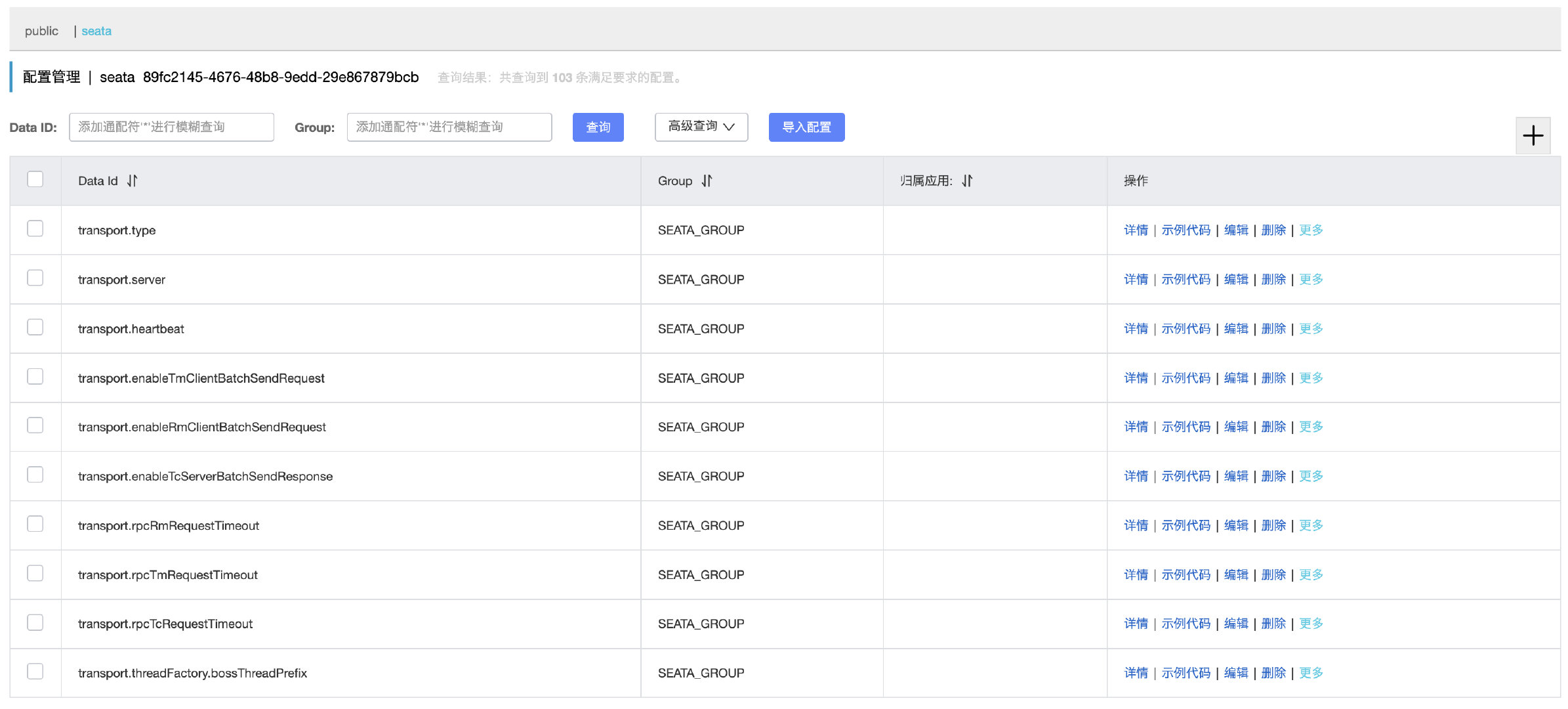
注意,还没完,我们还需要将对应的事务组映射配置也添加上,DataId格式为service.vgroupMapping.事务组名称,比如我们就使用默认的名称,值全部依然使用default即可:

现在我们就完成了服务端的Nacos配置,接着我们需要对客户端也进行Nacos配置:
seata:
# 注册
registry:
# 使用Nacos
type: nacos
nacos:
# 使用Seata的命名空间,这样才能正确找到Seata服务,由于组使用的是SEATA_GROUP,配置默认值就是,就不用配了
namespace: 89fc2145-4676-48b8-9edd-29e867879bcb
username: nacos
password: nacos
# 配置
config:
type: nacos
nacos:
namespace: 89fc2145-4676-48b8-9edd-29e867879bcb
username: nacos
password: nacos
现在我们就可以启动这三个服务了,可以在Nacos中看到Seata以及三个服务都正常注册了:


接着我们就可以访问一下服务试试看了:

可以看到效果和上面是一样的,不过现在我们的注册和配置都继承在Nacos中进行了。
我们还可以配置一下事务会话信息的存储方式,默认是file类型,那么就会在运行目录下创建file_store目录,我们可以将其搬到数据库中存储,只需要修改一下配置即可:

将store.session.mode和store.mode的值修改为db
接着我们对数据库信息进行一下配置:
- 数据库驱动
- 数据库URL
- 数据库用户名密码
其他的默认即可:
接着我们需要将对应的数据库进行创建,创建seata数据库,然后直接CV以下语句:
-- -------------------------------- The script used when storeMode is 'db' --------------------------------
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid`
VARCHAR(128) NOT NULL,
`transaction_id`
BIGINT,
`status`
TINYINT
NOT NULL,
`application_id`
VARCHAR(32),
`transaction_service_group` VARCHAR(32),
`transaction_name`
VARCHAR(128),
`timeout`
INT,
`begin_time`
BIGINT,
`application_data`
VARCHAR(2000),
`gmt_create`
DATETIME,
`gmt_modified`
DATETIME,
PRIMARY KEY (`xid`),
KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(
`branch_id`
BIGINT
NOT NULL,
`xid`
VARCHAR(128) NOT NULL,
`transaction_id`
BIGINT,
`resource_group_id` VARCHAR(32),
`resource_id`
VARCHAR(256),
`branch_type`
VARCHAR(8),
`status`
TINYINT,
`client_id`
VARCHAR(64),
`application_data`
VARCHAR(2000),
`gmt_create`
DATETIME(6),
`gmt_modified`
DATETIME(6),
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(
`row_key`
VARCHAR(128) NOT NULL,
`xid`
VARCHAR(128),
`transaction_id` BIGINT,
`branch_id`
BIGINT
NOT NULL,
`resource_id`
VARCHAR(256),
`table_name`
VARCHAR(32),
`pk`
VARCHAR(36),
`status`
TINYINT
NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',
`gmt_create`
DATETIME,
`gmt_modified`
DATETIME,
PRIMARY KEY (`row_key`),
KEY `idx_status` (`status`),
KEY `idx_branch_id` (`branch_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE IF NOT EXISTS `distributed_lock`
(
`lock_key`
CHAR(20) NOT NULL,
`lock_value`
VARCHAR(20) NOT NULL,
`expire`
BIGINT,
primary key (`lock_key`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('HandleAllSession', ' ', 0);

完成之后,重启Seata服务端即可:

看到了数据源初始化成功,现在已经在使用数据库进行会话存储了。
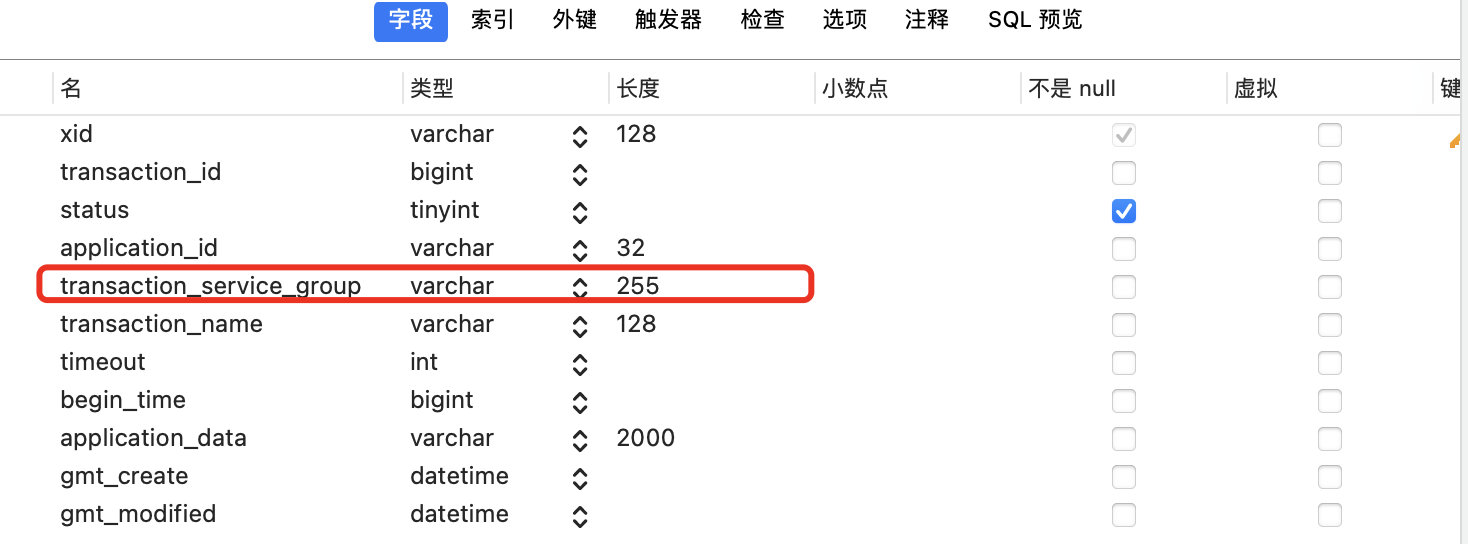
如果Seata服务端出现报错,可能是我们自定义事务组的名称太长了:

将globle_table表的字段transaction_server_group长度适当增加一下即可:
到此,关于基于nacos模式下的Seata部署,就完成了。
虽然我们这里实现了分布式事务,但是还是给各位同学提出一个问题(可以把自己所认为的结果打在弹幕上),就我们目前这样的程序设计,在高并发下,真的安全吗?比如同一时间100个同学抢同一个书,但是我们知道同一个书就只有3本,如果这时真的同时来了100个请求要借书,会正常地只借出3本书吗?如果不正常,该如何处理?
最后
以上就是懦弱水杯最近收集整理的关于SpringCloud笔记(二)微服务进阶微服务进阶的全部内容,更多相关SpringCloud笔记(二)微服务进阶微服务进阶内容请搜索靠谱客的其他文章。








发表评论 取消回复