基础概念
- 阻塞:(阻塞状态指程序未得到所需计算资源时被挂起的状态)程序在等待某个操作完成期间,自身无法继续干别的事情
- 非阻塞:程序在等待某个操作的过程中,自身不被阻塞,可以继续干别的事情(仅当程序封装的级别可以囊括独立的子程序单元时,程序才可能存在非阻塞状态)
- 同步:为了共同完成某个任务,不同程序单元之间在执行过程中需要靠某种通信方式保持协调一致,此时这些程序单元是同步执行的(有序的)
- 异步:为了完成某个任务,不同程序单元之间无须通信协调,此时不相关的程序单元之间可以是异步的(无序的)
- 多进程:利用多核CPU的优势,同一时间执行多个任务
- 协程(coroutine):本质上是个单进程,但拥有自己的寄存器上下文和栈,可以用来实现异步操作。
协程的用法
环境:Python 3.5+、asyncio库
基础概念
- event_loop:事件循环,可以把函数注册到这个事件循环上,当满足发生条件时,就调用对应的处理方法;
- coroutine(协程):指代协程对象类型。用async关键字定义一个方法,这个方法在调用时不会被立即执行,而是会返回一个协程对象。然后可以将协程对象注册到事件循环中,它就会被事件循环调用。
- task:可以对协程对象进一步封装,返回的task对象会包含运行状态信息。
- future:定义task对象的另一种方式,和task没有本质区别。
定义协程(直接将协程对象注册到事件循环中)
import asyncio
# 导入asyncio包,这样才能使用async和await关键字
async def execute(x):
print('Number:', x)
# 用async定义一个方法,该方法接收一个参数,执行之后就会打印这个参数
coroutine = execute(1)
print('Coroutine:', coroutine)
print('After calling execute')
# 直接调用前面定义的方法,但这个方法不会被执行,而是返回一个协程对象
loop = asyncio.get_event_loop()
# 创建一个事件循环loop对象
loop.run_until_complete(coroutine)
# 调用loop对象的run_until_complete方法将协程对象注册到事件循环中
# 注册完成之后,前面定义并调用的方法才会被执行
print('After calling loop')Coroutine: <coroutine object execute at 0x000001E7D19743C0>
After calling execute
Number: 1
After calling loop
async关键字:async定义的方法会变成一个无法直接执行的协程对象,必须将此对象注册到事件循环中才可以执行!
定义协程(先用create_task方法将协程封装成task对象)
import asyncio
async def execute(x):
print('Number:', x)
return x
coroutine = execute(1)
print('Coroutine:', coroutine)
print('After calling execute')
loop = asyncio.get_event_loop()
# 创建一个事件循环loop对象
task = loop.create_task(coroutine)
# 调用loop对象的create_task方法将协程对象转化成task对象
print('Task:', task)
# 此时打印输出的task对象处于pending(待定)状态
loop.run_until_complete(task)
# 调用loop对象的run_until_complete方法将协程对象注册到事件循环中
print('Task', task)
# 此时打印输出的task对象处于finished状态
print('After calling loop')Coroutine: <coroutine object execute at 0x000001EB521D5440>
After calling execute
Task: <Task pending name='Task-1' coro=<execute() running at D:Pythondemo临时测试2.py:125>>
Number: 1
Task <Task finished name='Task-1' coro=<execute() done, defined at D:Pythondemo临时测试2.py:125> result=1>
After calling loop
定义协程(先用ensure_future方法将协程封装成task对象)
import asyncio
async def execute(x):
print('Number:', x)
return x
coroutine = execute(1)
print('Coroutine:', coroutine)
print('After calling execute')
task = asyncio.ensure_future(coroutine)
# 直接调用asyncio包的ensure_future方法将协程对象转化成task对象(不需要先声明loop对象了)
print('Task:', task)
# 此时打印输出的task对象处于pending(待定)状态
loop = asyncio.get_event_loop()
# 创建一个事件循环loop对象
loop.run_until_complete(task)
# 调用loop对象的run_until_complete方法将协程对象注册到事件循环中
print('Task', task)
# 此时打印输出的task对象处于finished状态
print('After calling loop')Coroutine: <coroutine object execute at 0x0000023C80885440>
After calling execute
Task: <Task pending name='Task-1' coro=<execute() running at D:Pythondemo临时测试2.py:125>>
Number: 1
Task <Task finished name='Task-1' coro=<execute() done, defined at D:Pythondemo临时测试2.py:125> result=1>
After calling loop
给task对象绑定一个回调方法(add_done_callback)
import asyncio
import requests
async def request():
url = 'https://www.baidu.com'
status = requests.get(url)
return status
# 用async定义一个方法,该方法会请求网站获取并返回状态码
def callback(task):
print('Status:', task.result())
# 正常定义一个callback方法,该方法会调用result方法打印出task对象的结果
coroutine = request()
# 接收返回的协程对象
task = asyncio.ensure_future(coroutine)
# 将协程对象封装成一个task对象
task.add_done_callback(callback)
# 给task对象指定一个回调方法
print('Task:', task)
# 打印这个task对象(其中包含运行状态信息,此时为:pending)
loop = asyncio.get_event_loop()
# 创建一个事件循环loop对象
loop.run_until_complete(task)
# 调用loop对象的方法,将task对象注册到事件循环中(注册完,前面定义的方法立刻被执行)
print('Task:', task)
# 再次打印这个task对象(此时的运行状态:finished)Task: <Task pending name='Task-1' coro=<request() running at D:Pythondemo临时测试2.py:148> cb=[callback() at D:Pythondemo临时测试2.py:154]>
Status: <Response [200]>
Task: <Task finished name='Task-1' coro=<request() done, defined at D:Pythondemo临时测试2.py:148> result=<Response [200]>>
实际上,在这个例子中,即使不使用回调方法,在task运行完毕后,也可以直接调用result方法获取结果:
import asyncio
import requests
async def request():
url = 'https://www.baidu.com'
status = requests.get(url)
return status
# 用async定义一个方法,该方法会请求网站获取并返回状态码
coroutine = request()
# 接收返回的协程对象
task = asyncio.ensure_future(coroutine)
# 将协程对象封装成一个task对象
print('Task:', task)
# 打印这个task对象(其中包含运行状态信息,此时为:pending)
loop = asyncio.get_event_loop()
# 创建一个事件循环loop对象
loop.run_until_complete(task)
# 调用loop对象的方法,将task对象注册到事件循环中(注册完,前面定义的方法立刻被执行)
print('Task:', task)
# 再次打印这个task对象(此时的运行状态:finished)
print('Task:', task.result())
# 调用result方法,获取并打印这个task对象的结果
Task: <Task pending name='Task-1' coro=<request() running at D:Pythondemo临时测试2.py:148>>
Task: <Task finished name='Task-1' coro=<request() done, defined at D:Pythondemo临时测试2.py:148> result=<Response [200]>>
Task: <Response [200]>
多任务协程(执行多次请求)
import asyncio
import requests
async def request():
url = 'https://www.baidu.com'
status = requests.get(url)
return status
# 用async定义一个方法,该方法会请求网站获取并返回状态码
tasks = [asyncio.ensure_future(request()) for _ in range(5)]
# 将协程对象封装成一个task对象(重复五次),然后放在tasks列表里面
print('Tasks:', tasks)
# 打印这个tasks对象(其中包含五个task对象及其运行状态信息,此时为:pending)
loop = asyncio.get_event_loop()
# 创建一个事件循环loop对象
loop.run_until_complete(asyncio.wait(tasks))
# 调用loop对象的方法,将tasks列表(经过wait方法封装)注册到事件循环中(注册完,前面定义的方法立刻被执行)
for task in tasks:
print('Task Result', task.result())
# 调用result方法,遍历并打印这五个task对象的结果Tasks: [<Task pending name='Task-1' coro=<request() running at D:Pythondemo临时测试2.py:148>>, <Task pending name='Task-2' coro=<request() running at D:Pythondemo临时测试2.py:148>>, <Task pending name='Task-3' coro=<request() running at D:Pythondemo临时测试2.py:148>>, <Task pending name='Task-4' coro=<request() running at D:Pythondemo临时测试2.py:148>>, <Task pending name='Task-5' coro=<request() running at D:Pythondemo临时测试2.py:148>>]
Task Result <Response [200]>
Task Result <Response [200]>
Task Result <Response [200]>
Task Result <Response [200]>
Task Result <Response [200]>
协程实现
- async关键字:async定义的方法会变成无法直接执行(直接调用会返回一个协程对象),必须将此协程对象注册到事件循环中才可以执行;
- await关键字:可以将耗时等待的操作挂起,让出控制权(如果协程在执行的时候遇到了await,事件循环就会将本协程挂起,转而执行别的协程,直到其他协程挂起或执行完毕);
- aiohttp库:支持异步请求,需要和asyncio配合使用(安装:pip install aiohttp)
await后面的对象(方法)必须为如下格式之一:
- 一个原生协程对象(由async修饰,且支持异步操作)
- 一个生成器(由type.coroutine修饰,并可以返回协程对象)
- 一个迭代器(由包含__await__方法的对象返回的)
aiohttp的官方文档:https://docs.aiohttp.org/en/stable/
import asyncio
import aiohttp
import time
start = time.time()
async def get(url):
session = aiohttp.ClientSession()
# 第一步是非阻塞的,所以会被立马唤醒执行
response = await session.get(url)
# 利用aiohttp库里的ClientSession类的get方法进行请求(加上await关键词声明可挂起)
# 全部task都会来到这里挂起,然后几乎同一时间获得响应
await response.text()
await session.close()
return response
async def request():
url = 'https://www.httpbin.org/delay/5'
print('Waiting for', url)
response = await get(url)
# 整一个get方法都设置为await(可挂起)
print('Get response from', url, 'response', response)
tasks = [asyncio.ensure_future(request()) for _ in range(10)]
# 将协程对象封装成一个task对象(重复十次),然后放在tasks列表里面
loop = asyncio.get_event_loop()
# 创建一个事件循环loop对象
loop.run_until_complete(asyncio.wait(tasks))
# 调用loop对象的方法,将tasks列表(经过wait方法封装)注册到事件循环中(注册完,前面定义的方法立刻被执行)
end = time.time()
print('Cost time:', end - start)Waiting for https://www.httpbin.org/delay/5
Waiting for https://www.httpbin.org/delay/5
Waiting for https://www.httpbin.org/delay/5
Waiting for https://www.httpbin.org/delay/5
Waiting for https://www.httpbin.org/delay/5
Waiting for https://www.httpbin.org/delay/5
Waiting for https://www.httpbin.org/delay/5
Waiting for https://www.httpbin.org/delay/5
Waiting for https://www.httpbin.org/delay/5
Waiting for https://www.httpbin.org/delay/5
Get response from https://www.httpbin.org/delay/5 response <ClientResponse(https://www.httpbin.org/delay/5) [200 OK]>
<CIMultiDictProxy('Date': 'Thu, 24 Feb 2022 13:05:43 GMT', 'Content-Type': 'application/json', 'Content-Length': '367', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true')>
.....
更高并发的测试
import asyncio
import aiohttp
import time
def akb(number):
start = time.time()
async def get(url):
session = aiohttp.ClientSession()
response = await session.get(url)
# 利用aiohttp库里的ClientSession类的get方法进行请求(加上await关键词声明可挂起)
await response.text()
await session.close()
return response
async def request():
url = 'https://www.csdn.net/'
response = await get(url)
tasks = [asyncio.ensure_future(request()) for _ in range(number)]
# 将协程对象封装成一个task对象(重复十次),然后放在tasks列表里面
loop = asyncio.get_event_loop()
# 创建一个事件循环loop对象
loop.run_until_complete(asyncio.wait(tasks))
# 调用loop对象的方法,将tasks列表(经过wait方法封装)注册到事件循环中(注册完,前面定义的方法立刻被执行)
end = time.time()
print('Number:', number, 'Cost time:', end - start)
for number in [1, 10, 50, 100, 500]:
akb(number)Number: 1 Cost time: 2.363093376159668
Number: 10 Cost time: 2.376859188079834
Number: 50 Cost time: 3.716461420059204
Number: 100 Cost time: 7.078423500061035
Number: 500 Cost time: 15.283033847808838
使用异步爬虫可以在短时间内实现成千上百次的网络请求!
aiohttp的基本使用方法(客户端部分)
关键模块:
- asyncio模块:实现对TCP、UDP、SSL协议的异步操作(必须导入的库,因为实现异步爬取需要启动协程,同时协程需要借助于事件循环才能启动);
- aiohttp模块:是一个基于asyncio的异步HTTP网络请求模块。
aiohttp模块提供的服务端和客户端:
- 服务端:利用服务端可以搭建一个支持异步处理的服务器,用来处理请求并返回响应(类似于Django、Flask、Tornado等一些Web服务器);
- 客户端:用来发起请求,类似于requests(发起一个HTTP请求然后获取响应),区别在于requests发起的是同步的网络请求,aiohttp则是异步的。
基本实例(GET请求):
import aiohttp
import asyncio
async def fetch(session, url):
# 每个异步方法前都要统一加async来修饰
async with session.get(url) as response:
# with as语句用于声明一个上下文管理器,帮助自动分配和释放资源
# with as语句同样需要加async来修饰(代表声明一个支持异步的上下文管理器)
return await response.text(), response.status
# 对于返回协程对象的操作,需要加上await来修饰
# response.text()返回的是协程对象
# response.status返回的直接是一个数值
async def main():
async with aiohttp.ClientSession() as session:
html, status = await fetch(session, 'https://www.csdn.net')
print(f'html: {html[:100]}...')
print(f'status: {status}')
if __name__ == '__main__':
loop = asyncio.get_event_loop()
# 创建事件循环对象
loop.run_until_complete(main())
# 将协程对象注册到事件循环中基本实例2(GET请求+URL参数设置)
import aiohttp
import asyncio
async def main():
params = {'name': 'germey', 'age': 25}
async with aiohttp.ClientSession() as session:
async with session.get('https://www.httpbin.org/get', params=params) as response:
print(await response.text())
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
# 声明事件循环对象,将方法注册其中并运行
{
"args": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "www.httpbin.org",
"User-Agent": "Python/3.9 aiohttp/3.8.1",
"X-Amzn-Trace-Id": "Root=1-6217aad9-6711f6a8646bbf54671998f1"
},
"origin": "116.66.127.55",
"url": "https://www.httpbin.org/get?name=germey&age=25"
}
基本实例3(POST请求)
对于表单提交,其对应的请求头中的Content-Type为application/x-www-form-urlencoded
import aiohttp
import asyncio
async def main():
data = {'name': 'germey', 'age': 25}
async with aiohttp.ClientSession() as session:
async with session.post('https://www.httpbin.org/post', data=data) as response:
print(await response.text())
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
# 声明事件循环对象,将方法注册其中并运行
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "18",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "www.httpbin.org",
"User-Agent": "Python/3.9 aiohttp/3.8.1",
"X-Amzn-Trace-Id": "Root=1-6217ab09-717e0f595b6720491faa7623"
},
"json": null,
"origin": "116.66.127.55",
"url": "https://www.httpbin.org/post"
}
对于POST JSON数据提交,其对应的请求中的Content-Type为application/json,需要将post方法里面的data参数改成json
import aiohttp
import asyncio
async def main():
data = {'name': 'germey', 'age': 25}
async with aiohttp.ClientSession() as session:
async with session.post('https://www.httpbin.org/post', json=data) as response:
print(await response.text())
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
# 声明事件循环对象,将方法注册其中并运行{
"args": {},
"data": "{"name": "germey", "age": 25}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "29",
"Content-Type": "application/json",
"Host": "www.httpbin.org",
"User-Agent": "Python/3.9 aiohttp/3.8.1",
"X-Amzn-Trace-Id": "Root=1-6217ac9b-05b45563594b0c367b7f302d"
},
"json": {
"age": 25,
"name": "germey"
},
"origin": "116.66.127.55",
"url": "https://www.httpbin.org/post"
}
其他请求类型
session.post('https://www.httpbin.org/post', data=data)
session.put('https://www.httpbin.org/put', data=data)
session.delete('https://www.httpbin.org/delete')
session.head('https://www.httpbin.org/get')
session.options('https://www.httpbin.org/get')
session.patch('https://www.httpbin.org/patch', data=data)
# 只需要把对应的方法和参数替换一下就行获取响应中的信息
import aiohttp
import asyncio
async def main():
data = {'name': 'germey', 'age': 25}
async with aiohttp.ClientSession() as session:
async with session.post('https://www.httpbin.org/post', data=data) as response:
print('status:', response.status)
# 获取响应中的状态码
print('headers', response.headers)
# 获取响应中的响应头
print('body', await response.text())
# 获取响应中的响应体
print('bytes', await response.read())
# 获取响应中的二进制格式响应体
print('json', await response.json())
# 获取响应中的JSON格式响应体
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
# 声明事件循环对象,将方法注册其中并运行有些字段前面要加await,有些不需要。原则就是:如果返回的是一个协程对象,那么就要加。
具体可以看aiohttp的API,其链接为: https://docs.aiohttp.org/en/stable/client_reference.html
status: 200
headers <CIMultiDictProxy('Date': 'Thu, 24 Feb 2022 16:10:30 GMT', 'Content-Type': 'application/json', 'Content-Length': '510', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true')>
body {
"args": {},
"data": "",
"files": {},
"form": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "18",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "www.httpbin.org",
"User-Agent": "Python/3.9 aiohttp/3.8.1",
"X-Amzn-Trace-Id": "Root=1-6217adf6-6003f76d24e8c82b28fec349"
},
"json": null,
"origin": "116.66.127.55",
"url": "https://www.httpbin.org/post"
}bytes b'{n "args": {}, n "data": "", n "files": {}, n "form": {n "age": "25", n "name": "germey"n }, n "headers": {n "Accept": "*/*", n "Accept-Encoding": "gzip, deflate", n "Content-Length": "18", n "Content-Type": "application/x-www-form-urlencoded", n "Host": "www.httpbin.org", n "User-Agent": "Python/3.9 aiohttp/3.8.1", n "X-Amzn-Trace-Id": "Root=1-6217adf6-6003f76d24e8c82b28fec349"n }, n "json": null, n "origin": "116.66.127.55", n "url": "https://www.httpbin.org/post"n}n'
json {'args': {}, 'data': '', 'files': {}, 'form': {'age': '25', 'name': 'germey'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Content-Length': '18', 'Content-Type': 'application/x-www-form-urlencoded', 'Host': 'www.httpbin.org', 'User-Agent': 'Python/3.9 aiohttp/3.8.1', 'X-Amzn-Trace-Id': 'Root=1-6217adf6-6003f76d24e8c82b28fec349'}, 'json': None, 'origin': '116.66.127.55', 'url': 'https://www.httpbin.org/post'}
超时设置
import aiohttp
import asyncio
async def main():
timeout = aiohttp.ClientTimeout(total=1)
async with aiohttp.ClientSession(timeout=timeout) as session:
async with session.get('https://www.httpbin.org/get') as response:
print('status:', response.status)
# 获取响应中的状态码
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
# 声明事件循环对象,将方法注册其中并运行如果1秒内能响应就返回:200,否则就会抛出asyncio.exceptions.TimeoutError类型错误
(声明ClientTimeout时还有其他参数可以用:connect、socket_connect)
并发限制
(参考链接:https://www.cnblogs.com/lymmurrain/p/13805690.html)
import asyncio
import aiohttp
url = 'https://www.baidu.com'
num = 5
# 设置控制并发数
semaphore = asyncio.Semaphore(num)
# 生成控制并发对象
async def scrape_api():
async with semaphore:
print('scraping', url)
async with session.get(url) as response:
await asyncio.sleep(2)
return len(await response.text())
async def main():
print(await asyncio.gather(*[scrape_api() for _ in range(20)]))
async def create_session():
return aiohttp.ClientSession()
if __name__ == '__main__':
loop = asyncio.get_event_loop()
# 创建事件循环
session = loop.run_until_complete(create_session())
# 先用async定义一个方法,将其返回的协程对象注入事件循环
loop.run_until_complete(main())
# 先用async定义好主函数,将其返回的协程对象注入事件循环
loop.run_until_complete(session.close())
# 要手动关闭自己创建的session,并且client.close()是个协程,得用事件循环关闭
loop.run_until_complete(asyncio.sleep(3))
# 在关闭loop之前要给aiohttp一点时间关闭session,调用asyncio的sleep方法
loop.close()aiohttp异步爬取实战
目标网站:
- http://spa5.scrape.center/
网站特性:
- 包含数千本图书信息,网站数据时JavaScript渲染而得的,数据可以通过Ajax接口获得。
爬取目标:
- 使用aiohttp爬取全站的的图书数据
- 将数据通过异步的方式保存到MongoDB中
环境:
- Python3.7以上+MongoDB数据库+asyncio、aiohttp、motor等模块库
- 注意:motor的连接声明和pymongo类似,保存数据的调用方法也基本一致,区别在于motor支持异步操作。
页面分析:

- 列表页的Ajax请求接口格式为:https://spa5.scrape.center/api/book/?limit={limit}&offset={offset}
- 其中limit的值代表每一页包含多少本书,offset的值为每一页的偏移量,计算公式为offset=limit*(page-1),如第一页的offset值为0,第二页的offset值为18

- 在列表页Ajax接口返回的数据中,results字段包含了当前页面全部图片的信息,其中的id可以用来进一步请求详情页
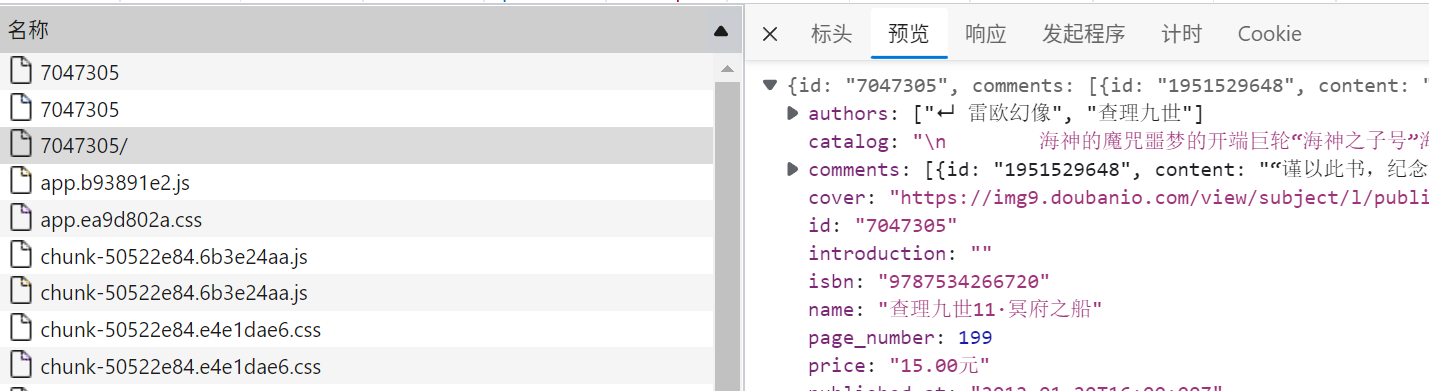
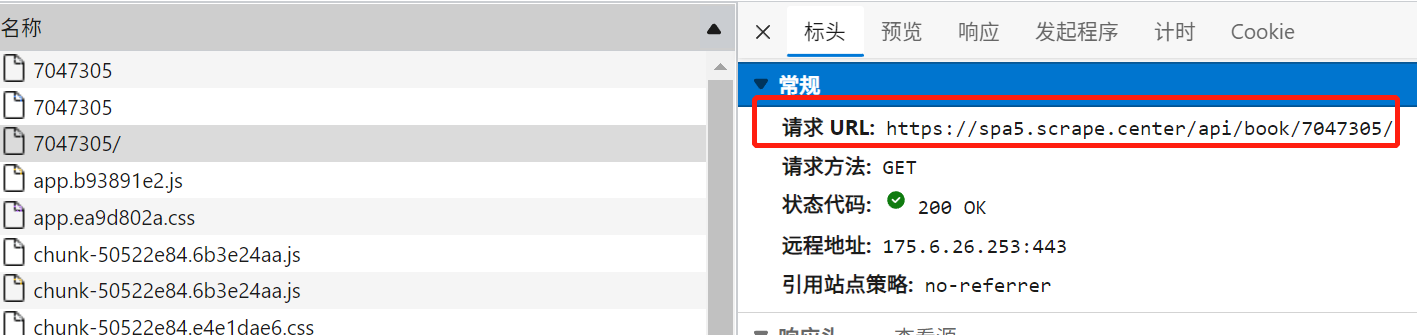
- 详情页的Ajax请求接口格式为:https://spa5.scrape.center/api/book/{id};
- 其中的id就是列表页中,图书对应的id,可以从这个接口中获取图书的详情内容。
实现思路
- 异步爬取所有列表页,将所有列表页的爬取任务集合在一起,并将其声明为由task组成的列表,进行异步爬取
- 拿到上一步列表页的所有内容并解析,将所有图书的id信息组合为所有详情页的爬取任务集合,并将其声明为task组成的列表,进行异步爬取,同时爬取结构也已异步方式存储到MongoDB中。
- (两个阶段需要串行执行,并非性能最佳的方式)
代码:
import asyncio
import aiohttp
import logging
import json
from motor.motor_asyncio import AsyncIOMotorClient
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
# 定义报告信息的打印格式
INDEX_URL = 'https://spa5.scrape.center/api/book/?limit=18&offset={offset}'
# 索引页链接格式
DETAIL_URL = 'https://spa5.scrape.center/api/book/{id}'
# 详情页链接格式
PAGE_SIZE = 18
# 索引页链接的翻页偏移量
PAGE_NUMBER = 5
# 需要爬取页码的数量
CONCURRENCY = 5
# 并发量
semaphore = asyncio.Semaphore(CONCURRENCY)
# 基于并发量声明一个信号标,用来控制最大并发数量
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'books'
MONGO_COLLECTION_NAME = 'books'
# 设置MongoDB数据库的连接信息(链接、数据库名、集合名)
client = AsyncIOMotorClient(MONGO_CONNECTION_STRING)
db = client[MONGO_DB_NAME]
collection = db[MONGO_COLLECTION_NAME]
# 基于连接信息,声明连接MongoDB数据库需要用到的对象
async def scrape_api(url):
# 定义一个异步的、通用的scrape方法(索引页和详情页的爬取都可以用)
# 请求并返回url的JSON格式的响应结果
async with semaphore:
# 开启一个异步上下文管理器,引入信号标
try:
logging.info('scraping %s', url)
# 调用info方法,报告当前的运行状态(在爬哪一个链接?)
async with session.get(url) as response:
# 用get方法请求这个url
return await response.json()
# 返回响应的JSON格式的结果
except aiohttp.ClientError:
# 引入异常处理,捕获ClientError
logging.error('error occurred while scraping %s', url, exc_info=True)
# 调用error方法,报告当前爬取出错的链接信息
async def main():
global session
session = aiohttp.ClientSession()
# 声明一个session对象,并声明为全局变量(这样就不用在各个方法里面传递session了)
scrape_index_tasks = [asyncio.ensure_future(scrape_index(page)) for page in range(1, PAGE_NUMBER + 1)]
# 由所有爬取索引页的task组成的列表(要爬取N页,就调用scrape_index方法生成N个task,然后这些task会组成一个列表)
results = await asyncio.gather(*scrape_index_tasks)
# 调用gather方法,将task列表传入其中,收集scrape_index返回的所有结果并赋值为results
logging.info('results %s', json.dumps(results, ensure_ascii=False, indent=2))
# 调用info方法打印爬取信息(将JSON格式的results转化为字符串)
# 使用json.dumps可以实现漂亮打印,其中indent控制缩进的空格数(默认输出ascii格式字符,想要正确输出中文就要改为False)
ids = []
for index_data in results:
# 遍历从results中提取到的字段
if not index_data:
continue
# 如果提取的是空值,直接跳过这一轮
for item in index_data.get('results'):
ids.append(item.get('id'))
# 如果提取到的index_data为非空,就遍历这个索引页中的id信息,汇总到ids列表中
scrape_detail_tasks = [asyncio.ensure_future(scrape_detail(id)) for id in ids]
# 由所有爬取详情页的task组成的列表(遍历ids中的id,传入scrape_detail方法,生成task对象)
await asyncio.wait(scrape_detail_tasks)
# 调用asyncio的wait方法,并将声明的列表传入其中,就可开启爬取详情页(效果和gather方法一样)
await session.close()
async def scrape_index(page):
url = INDEX_URL.format(offset=PAGE_SIZE * (page - 1))
# 格式化索引页url
return await scrape_api(url)
# 调用通用的scrape_api方法,请求并返回当前索引页的页面(JSON格式的resp)
async def scrape_detail(id):
url = DETAIL_URL.format(id=id)
# 格式化详情页url
data = await scrape_api(url)
# 调用通用的scrape_api方法,请求并返回当前详情页的页面(JSON格式的resp)
await save_data(data)
# 调用save_data方法,异步保存url中提取到的信息
async def save_data(data):
# 定义数据保存方法
logging.info('saving data %s', data)
# 打印数据保存信息
if data:
return await collection.update_one(
{
'id': data.get('id')
},
{
"$set": data
}, upsert=True)
# 这里此采用update_one(更新)的方式进行数据插入,依据的唯一标识就是从data中提取到的图书id
# $set参数表示只操作更新data字典里面有的数据,原本就存在的字段不会更新也不会删除(如果不用$set就会被全部被替换)
# upsert=True表示如果根据条件(这里是id)查询不到对应数据的话,就会执行插入操作
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
# 将main方法注册到事件循环中<完>
最后
以上就是害羞凉面最近收集整理的关于异步爬虫:协程的基本原理基础概念的全部内容,更多相关异步爬虫:协程内容请搜索靠谱客的其他文章。








发表评论 取消回复