我是靠谱客的博主 快乐花生,这篇文章主要介绍如何加快爬虫速度1. 多线程2. 多进程3. 线程池和进程池4. 线程池实例:爬取新发地5. 协程6. 多任务异步协程实现7. aiohttp模块详解8. 实例:爬一本小说9. 综合实例:抓取一部电影,现在分享给大家,希望可以做个参考。
文章目录
- 1. 多线程
- 2. 多进程
- 3. 线程池和进程池
- 4. 线程池实例:爬取新发地
- 5. 协程
- 6. 多任务异步协程实现
- 7. aiohttp模块详解
- 8. 实例:爬一本小说
- 9. 综合实例:抓取一部电影
- 9.1 常识普及
- 9.2 简单实例
1. 多线程
- 线程:操作系统为程序准备内存用于存储变量等,内存可以称作某进程(资源单位),进程内部有多个线程(执行单位)在运行。
- 一个进程里面至少有一主线程,为提高程序效率可以多线程并行。
- 只有进程,无线程那就无法运行程序。
from threading import Thread
## 方法1:
# def func():
# for i in range(100):
# print("func", i)
#
#
# if __name__ == "__main__":
# t = Thread(target=func) # 创建线程,并给线程安排任务
# t.start() # 可以开始执行该线程,具体执行时间由CPU决定
# for j in range(100):
# print("main", j)
## 方法2:
class MyThread(Thread):
def run(self): # 原本就存在的一个函数,当线程可以被执行后,CPU会运行run()
for i in range(1000):
print("MyThread", i)
if __name__ == "__main__":
t = MyThread()
# t.run() #方法的调用,仍是单线程
t.start() # 开启线程
for j in range(1000):
print("main", j)
运行结果摘录:
MyThreadmain 860
main 861
main 862
main 863
507
MyThread 508
main 864
main 865MyThread
509main
866
mainMyThread 510
MyThread 511
MyThread867
512
main 868MyThread
main 513869
from threading import Thread
# 涉及到开辟2个线程
def func(name):
for i in range(100):
print(name, i)
if __name__ == "__main__":
t1 = Thread(target=func, args=("JAY",)) # 传参数必须是元组 只有 1 个元素的 tuple 定义时必须加一个逗号,消除歧义
t1.start() # 可以开始执行该线程,具体执行时间由CPU决定
t2 = Thread(target=func, args=("JJ",)) # 传参数必须是元组
t2.start() # 可以开始执行该线程,具体执行时间由CPU决定
for j in range(100):
print("main", j)
结果摘录
JAY 40
JAY 41
JAY 42
17
main 18
main 19JJ 7
JJ 8
JJ 9
JJ 10
JJ 11
2. 多进程
- 开辟进程消耗的资源比线程多得多,因此较为少用
from multiprocessing import Process
def func():
for i in range(1000):
print("子进程", i)
if __name__ == "__main__":
p = Process(target=func)
p.start()
for j in range(1000):
print("主进程", j)
3. 线程池和进程池
- 线程池:一次性开辟多个线程,用户直接给线程池提交任务,具体哪个线程执行任务用户不关心(线程任务调度线程池决定)
- 经过试验,类似下面这种简单的任务,划分线程池反而速度更慢,线程池数目越少速度越快
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def fn(name):
for i in range(1000):
print(name, i)
if __name__ == "__main__":
# 创建线程池,里面有50个线程
with ThreadPoolExecutor(50) as t:
for i in range(100):
t.submit(fn, name=f"线程{i}")
# 等待线程中的任务执行完毕后才可继续,称为线程守护
print("done!")
结果摘录
线程82 992989
线程86 996
线程73 997 987990
线程92 949963
线程94974
线程78 985988
线程78
线程73 998
线程73991线程92 989
线程83 线程85 994线程89
线程82 986
线程78 999
4. 线程池实例:爬取新发地
# 1. 提取单个页面数据
# 2. 使用线程池,多页面同时抓取
import requests
from lxml import etree
import csv
import time
from concurrent.futures import ThreadPoolExecutor
f = open('data3.csv', 'w', encoding='utf-8', newline='')
# encoding 防乱码
# newline 防空行
csvwriter = csv.writer(f)
def download_page(url):
resp = requests.get(url)
# print(resp.text)
html = etree.HTML(resp.text)
table = html.xpath("/html/body/div[2]/div[4]/div[1]/table")[0]
# trs = table.xpath("./tr")[1:] #抛弃第0行表头
trs = table.xpath("./tr[position()>1]")
# print(len(trs)) # 获取行数
for tr in trs:
txt = tr.xpath("./td/text()")
# 对数据做简单处理 去掉 \ /
txt = (item.replace('\', '').replace('/', '') for item in txt) # 元组
# print(txt)
# print(list(txt))
csvwriter.writerow(list(txt))
# csvwriter.writerows(list(txt))
print(url, "提取完毕!")
timestamp1 = time.time()
if __name__ == "__main__":
for i in range(1, 200): #效率极差
download_page(f"http://www.xinfadi.com.cn/marketanalysis/0/list/{i}.shtml")
# 单线程 200页面 time cost 72.68099999427795 s
# # 创建线程池
# with ThreadPoolExecutor(50) as t:
# for i in range(1, 200): # 199*20=3980
# t.submit(download_page, f"http://www.xinfadi.com.cn/marketanalysis/0/list/{i}.shtml")
print("totally done!")
f.close() # 必须有,否则无法将内存数据写入硬盘
timestamp2 = time.time()
print('time cost',timestamp2-timestamp1,'s')
# 50线程 200页面 time cost 7.562999963760376 s
# 50线程 200页面 time cost 5.9710001945495605 s
# 50线程 200页面 time cost 6.567000150680542 s
5. 协程
- time.sleep(3)期间,程序让当前的线程处于阻塞状态,CPU不为程序工作,程序运行效率低
- input()用户输入数据前、requests.get()网络请求返回数据前,程序也是处于阻塞状态。
- 程序处于IO操作时候,线程往往会处于阻塞状态。
- 协程:应该通过程序设计,设法将CPU抢回来,让程序遇到IO操作时候,CPU切换到其他任务。在微观上是任务间的切换(切换条件一般是IO操作);宏观上是多个任务一起在执行,实际上是多任务异步操作。这些都可以在单线程的前提下完成。
6. 多任务异步协程实现
import asyncio
import time
async def func1():
print('I'm Sam')
# time.sleep(3) # 当程序出现同步操作(time.sleep),那就会打断异步
await asyncio.sleep(3) # 异步操作的sleep
# await 将任务挂起
print('I'm Sam')
async def func2():
print('I'm Amy')
# time.sleep(2)
await asyncio.sleep(2) # 异步操作的sleep
print('I'm Amy')
async def func3():
print('I'm Daming')
# time.sleep(4)
await asyncio.sleep(4) # 异步操作的sleep
print('I'm Daming')
t1 = time.time()
if __name__ == "__main__":
f1 = func1()
f2 = func2()
f3 = func3()
tasks = [
f1, f2, f3
]
g = func1() # 此时的函数是异步协程函数,函数执行的结果是一个协程对象,想运行必须借助 asyncio 库
# print(g)
# <coroutine object func at 0x000000000358A440>
# asyncio.run(g) # 单独执行g
asyncio.run(asyncio.wait(tasks))
t2 = time.time()
print(t2-t1)
# 使用同步延时 sleep() 打断异步 等效于同步串行执行 程序耗时 9.001000165939331s
# 使用异步延时 并将任务挂起 await asyncio.sleep() 整个程序耗时取决于睡眠时间最长的任务 程序耗时 4.01800012588501s
- 使用下面的方法将 tasks封装在 main() 中
async def main():
# 让几个任务同时运行 有2种方法:
# 1
# f1 = func1()
# await f1 # 一般 await 挂起操作放在协程对象之前
# 2 推荐
tasks = [
# func1(), # py3.8 之前的写法 ,这种写法是在 await asyncio.wait(tasks) 后才开始执行
# func2(),
# func3()
asyncio.create_task(func1()), #py3.8之后需要将协程对象包装为task之后才能丢给 await asyncio.wait(tasks)
asyncio.create_task(func2()), # 这种写法是在此时开始执行的
asyncio.create_task(func3()) # 两种写法达到的效果一样
]
await asyncio.wait(tasks)
if __name__ == '__main__':
t1 = time.time()
asyncio.run(main())
t2 = time.time()
print(t2-t1)
import asyncio
import time
async def download(url):
print("开始下载")
await asyncio.sleep(2) # 模拟网络请求 request.get() 是同步的
print("下载完毕")
async def main():
urls = [
"https://www.baidu.com",
"https://www.4399.com",
"https://www.163.com"
]
tasks = []
for url in urls:
d = download(url) # 返回协程对象
tasks.append(d) # 最终有3个协程对象
await asyncio.wait(tasks) # 异步执行
if __name__ == '__main__':
asyncio.run(main())
7. aiohttp模块详解
- 协程应用实例:单线程
import asyncio
import time
import aiohttp
urls = [
"https://desk-fd.zol-img.com.cn/t_s960x600c5/g5/M00/01/0E/ChMkJ1bKwXGIUrLyAAfjqjOWSooAALGYQKHP0QAB-PC392.jpg",
"https://desk-fd.zol-img.com.cn/t_s960x600c5/g5/M00/01/0E/ChMkJlbKwXGIGSnmAAen2sAtvfQAALGYQKYjaEAB6fy435.jpg",
"https://desk-fd.zol-img.com.cn/t_s960x600c5/g6/M00/07/07/ChMkKmCcnFyIGqspABJoMloQWhQAAOv7gCrhqIAEmhK099.jpg"
]
async def aiodownload(url):
name = url.rsplit('/', 1)[1] # 从右侧开始切,取[1]位置的内容
# aiohttp.ClientSession() # 等价于 request.get()
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
with open(name, mode='wb') as f:
# aiofiles 可以异步下载
# resp.text() 返回源码
f.write(await resp.content.read()) # 读取内容是异步的 需要 await 挂起
f.close()
print(name, 'done!')
async def main():
tasks = []
for url in urls:
tasks.append(aiodownload(url))
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
8. 实例:爬一本小说
# 检查网页,在 network 中查看网页请求
# 将其中的 %22 替换 为 "
# Request URL: http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"}
# 章节内容
# Request URL: http://dushu.baidu.com/api/pc/getChapterContent?data={"book_id":"4306063500","cid":"4306063500|11348571","need_bookinfo":1}
import json
import requests
import asyncio
import aiohttp
import aiofiles
# 1. 同步操组:访问 getCatalog 拿到所有章节的 cid 和名称
# 2. 异步操作:访问 getChapterContent 下载所有文字内容
async def aiodownload(cid, book_id, title):
data = {
"book_id": book_id,
"cid": f"{book_id}|{cid}",
"need_bookinfo": 1
}
data = json.dumps(data) # 转为字符串
url = f"http://dushu.baidu.com/api/pc/getChapterContent?data={data}"
async with aiohttp.ClientSession() as session: # 创建异步回话
async with session.get(url) as resp: # 获取异步响应
dic = await resp.json()
# 在 network 中 preview 中所显现的层级结构是 json
async with aiofiles.open('novel/' + title +'.txt', mode='w', encoding='utf-8')as f:
await f.write(dic['data']['novel']['content']) # 小说内容写出
await f.close()
async def getCatalog(url):
resp = requests.get(url)
# print(resp.text)
dic = resp.json()
tasks = []
for item in dic['data']['novel']['items']: # items就是每一个章节的名称和cid
title = item['title']
cid = item['cid']
# 每一个 cid 就是一个异步任务
# print(cid,title)
tasks.append(aiodownload(cid, book_id, title))
await asyncio.wait(tasks)
if __name__ == '__main__':
book_id = '4306063500'
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + book_id + '"}'
asyncio.run(getCatalog(url))
print('done!')
9. 综合实例:抓取一部电影
9.1 常识普及
- 用户上传 -> 转码(将视频做处理,2k,1080,标清)->切片处理(把单个大文件进行拆分)->充分利用服务器带宽、减轻用户网络压力
- 需要一个文件记录切片顺序和存放路径(都存在M3U/M3U8文件),找到这个文件视频抓取就问题不大了
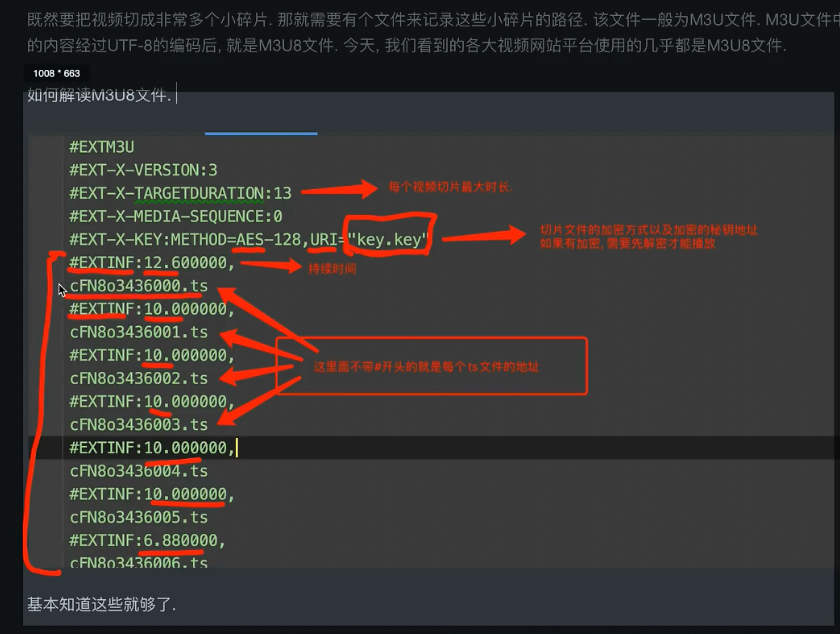
- 图片中没有#的部分是链接,后面的 ts 是切片的意思。综合起来就是切片视频的地址。
- 抓取视频步骤:
-
- 找到M3U8文件
-
- 下载ts文件
-
- 将ts文件合并为一个mp4文件(编程、PR)
-
9.2 简单实例
- 一般网页源代码中不会有video标签,而是页面视频通过js脚本动态生成的video标签。
- 在network中的XHR中找到的URL:https://m3api.awenhao.com/index.php?note=kkR4wpy8f6ncabt7xqes2&raw=1&n.m3u8
- note后的kkR4wpy8f6ncabt7xqes2是服务器给客户端的一个实时校验码,客户端访问m3u8文件的时候必须带着这个校验码。
- 步骤:
- 拿到页面源码
- 从源码提取到m3u8的URL
- 下载m3u8
- 根据m3u8文件,下载视频
- 整合视频
最后
以上就是快乐花生最近收集整理的关于如何加快爬虫速度1. 多线程2. 多进程3. 线程池和进程池4. 线程池实例:爬取新发地5. 协程6. 多任务异步协程实现7. aiohttp模块详解8. 实例:爬一本小说9. 综合实例:抓取一部电影的全部内容,更多相关如何加快爬虫速度1.内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。
![[Python爬虫]爬虫性能优化-线程池爬虫性能优化-线程池](https://www.shuijiaxian.com/files_image/reation/bcimg19.png)







发表评论 取消回复