爬虫学习伊始,参考网上素材,自己写出来的,比较简单:主要运用了request爬取,正则表达式解析
import requests
import re
import os
from urllib import error
def main():
dirPath = "E:pythongirl-images"
url = "https://www.dbmeinv.com/?pager_offset="
i = 1
j = 0
while i < 10:
url = url + str(i)
try:
result = requests.get(url, timeout=10)
except error.HTTPError as e:
i += 1
continue
else:
text = result.text
list = re.findall('src="(.*?.jpg)"', text, re.S)
if len(list) == 0:
i += 1
continue
else:
for enum in list:
image = requests.get(enum, timeout=7)
filePath = os.path.join(dirPath, "girl_image_" + str(j) + ".jpg")
f = open(filePath, 'wb')
f.write(image.content)
f.close()
j += 1
i += 1
if __name__ == '__main__':
main()结果效果:
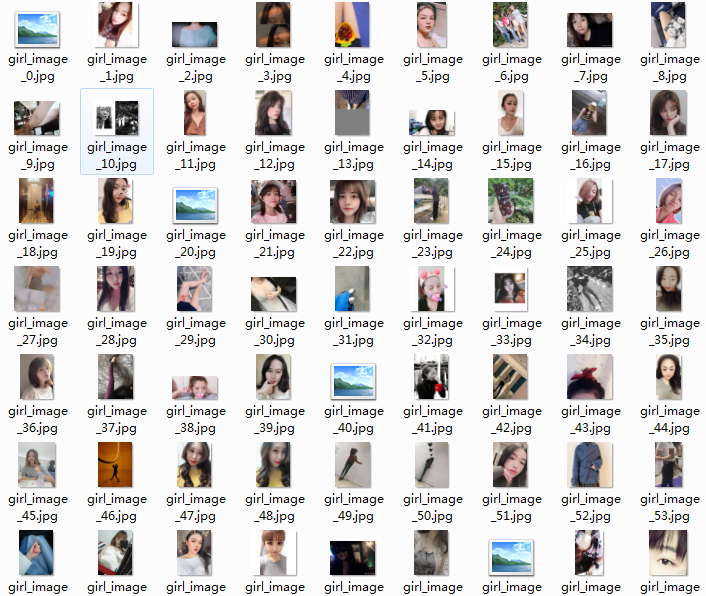
最后
以上就是淡淡黑裤最近收集整理的关于python爬虫篇1:爬妹子图片的全部内容,更多相关python爬虫篇1内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复