一、前言
发表于2017年的ijcai文章,主要采用了FM结合注意力机制进行物品的推荐,也取得了较好的效果;
论文地址为:https://www.ijcai.org/proceedings/2017/0435.pdf
二、算法原理
(1)首先介绍一下模型的整体框架对于因子分解的结果赋予一个权重,这个权重通过学习获得,来表示对不同特征交叉之间的关注度;
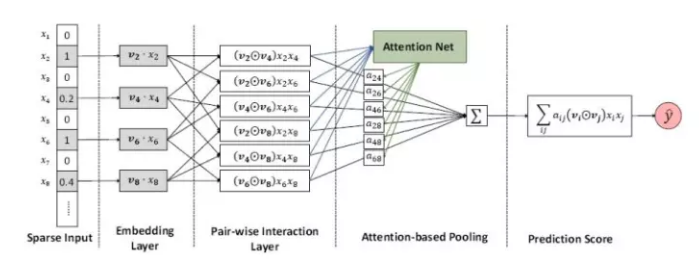
(2)整个模型可以通过如下公式来表述;其中包含一阶部分和有注意力机制的二阶部分;
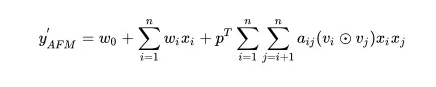
(3)注意力部分的实现,下面是注意力机制实现的一种方式,叫做乘性注意力机制,具体实现可以参考代码,然后同通过一个softmax层,进行归一化之后得到一个权重;
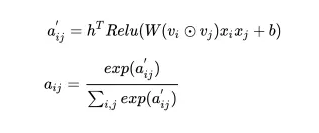
(4)模型中采用的损失函数如下所示;
(5)模型的改进策略,查看过其他大佬的文章,由于二次项部分的特征交叉之后没有通过一个DNN层,可能没有更好的学习到更深层的交叉特征,所以可以添加一个DNN层,可能会得到一个更好的结果;
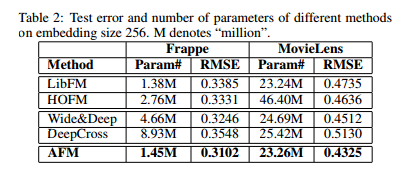
三、实验效果
实验对比了不同的模型的实验效果,如下图为原论文中的收敛效果示意图;
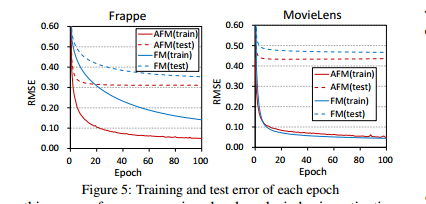
论文中说明了deepcross在这里边效果是最差的,分析了原因为可能是因为层数较深,模型复杂度高已经出现了过拟合的问题,
所以在有时候并不是模型深度越深效果就是越好的;
四、代码实现
代码实现部分只实现核心部分的注意力机制这块,其他部分需要自行补充;
from tensorflow.python.keras.layers import Layer
from tensorflow.python.keras.initializers import glorot_normal, Zeros
import tensorflow as tf
import itertools
class afm(Layer):
def __init__(self, attention_size=4, seed=1024, **kwargs):
self.seed = seed
self.attention_size = attention_size
super(afm, self).__init__(**kwargs)
def build(self, input_shape):
embed_size = input_shape[-1].value
self.att_w = self.add_weight(name='att weights', shape=(embed_size, self.attention_size), initializer=glorot_normal(self.seed))
self.att_b = self.add_weight(name='att bias', shape=(self.attention_size, ), initializer=Zeros())
self.projection_h = self.add_weight(name='projection_h', shape=(self.attention_size, 1), initializer=glorot_normal(self.seed))
self.projection_p = self.add_weight(name='projection_p', shape=(embed_size, 1), initializer=Zeros())
self.tensordot = tf.keras.layers.Lambda(lambda x : tf.tensordot(x[0], x[1], axes=(-1, 0)))
super(afm, self).build(input_shape)
def call(self, inputs):
embed_vec_list = inputs
row = []
col = []
for r, w in itertools.combinations(embed_vec_list, 2):
row.append(r)
col.append(w)
p = tf.concat(row, axis=1)
q = tf.concat(col, axis=1)
inner_product = p * q
att_tmp = tf.nn.relu(tf.nn.bias_add(tf.tensordot(inner_product, self.att_w, axes=(-1, 0)), self.att_b))
self.att_normalized = tf.nn.softmax(tf.tensordot(att_tmp, self.projection_h, axes=[-1, 0]), dim=1)
att_output = tf.reduce_sum(self.att_normalized * inner_product, axis=1)
att_output = tf.keras.layers.Dropout(0.2, seed=self.seed)
afm_out = tf.tensordot(att_output, self.projection_p)
return afm_out
最后
以上就是呆萌美女最近收集整理的关于推荐系统系列:AFM模型算法原理和代码实现的全部内容,更多相关推荐系统系列内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复