一、背景
SVM(2010),MV-RNN(2012),CNN(2014),FCM(2014),CR-CNN(2015),DepNN(2015)。
理论上,RNN可以任意长度的序列进行建模。但由于梯度消失/梯度爆炸问题。实际上无法实现。LSTM引入门控机制,改进了RNN,从而获得了对长序列建模的能力。
本文提出了双向长短时记忆网络(BLSTM)来对包含所有单词完整、顺序信息的句子进行建模。同时,还使用从词汇资源(如WordNet)或NLP系统(如依赖解析器和命名实体识别器(NER)中获取的特征。在SemEval-2010上的实验结果表明,仅将单词嵌入作为输入特征的基于BLSTM的方法就可以达到最先进的性能,引入更多的特征可以进一步提高性能。
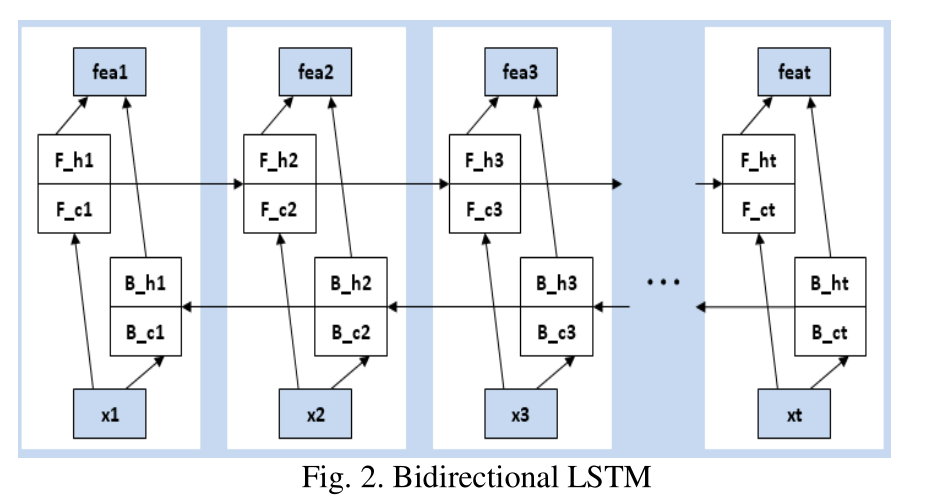
F:Forward
B:Backward
h:hidden
c:cell
二、模型
1.Initial Feature Extraction(初始特征提取)
word features
position features
POS features
NER features
hypernyms(WNSYN) features
DEP features
Relative DEP features
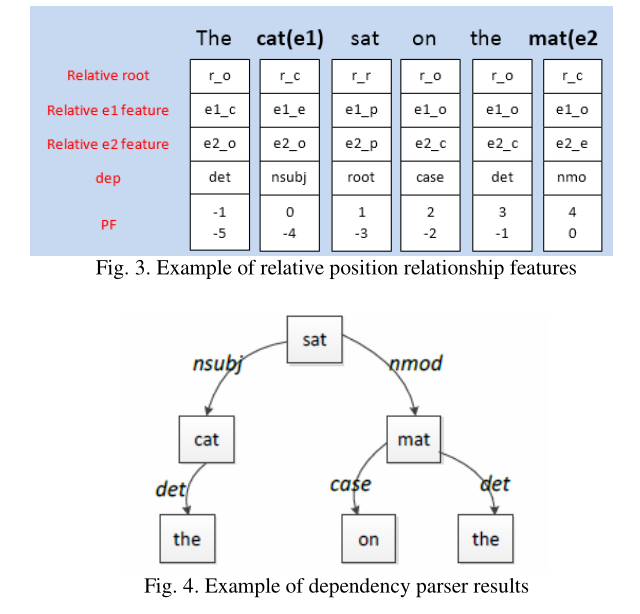
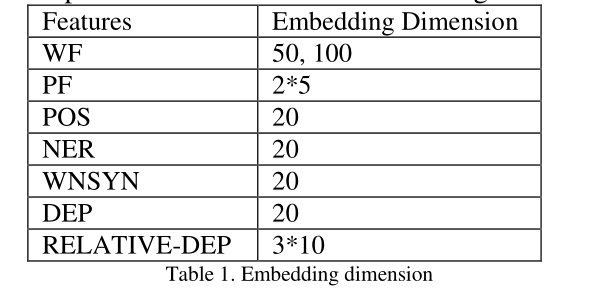
2.Feature Embedding(特征嵌入)
对于句子中第i个词:
word embedding为riw。其余特征的embedding为rikj,j代表第j种特征。
最终的embedding为
xi=[riw,rik1,rik2,…,rikm]
在本文中,m=6。(除Word embedding外,还有6种特征)。
3.BLSTM-based Sentence Level Representation(基于双向LSTM的句子级表示)
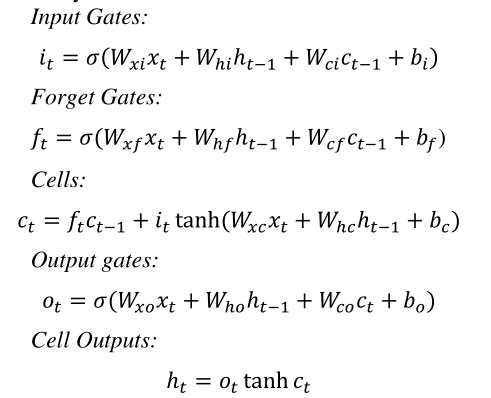
经网络计算,句子中第i个词的输出为:
Fi=[F_hi,F_ci,B_hi,B_ci]
F:Forward
B:Backward
h:hidden
c:cell
4.Constructing Feature Vector(构建特征向量)(新颖)
受Zeng(2014)的启发,本文也提取Lexical level features 和 Sentence level features,并将二者连接,构成最终的特征向量。
Lexical level features:
代表两个实体的向量
Lexical level features = [xe1,Fe1,xe2,Fe1]
Sentence level features:
按照两个实体e1和e2将整个句子划分为3个部分:A,B,C。
在A和B之间,B和C之间分别运用Max Pooling,得到向量m1和m2。将二者连接得到
Sentence level features = m = [m1,m2]
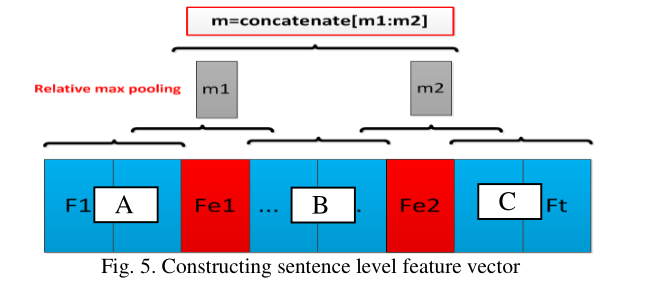
以这种方式构建句子层次特征向量的动机是为了加强两个实体之间的语境的影响,它通常包含更多的指示关系的信息。
5.Classifying(分类)
使用一个多层感知机(MLP),也即前馈神经网络,来将lexical level features 和 sentence level features组合,并生成最终的特征向量用于分类。
三、实验结果
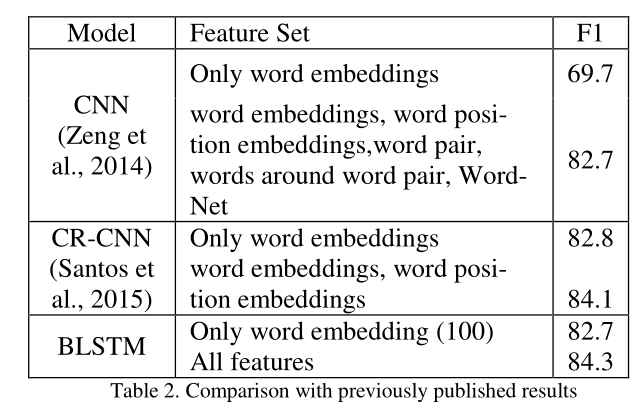


最后
以上就是故意书本最近收集整理的关于Bidirectional Long Short-Term Memory Networks for Relation Classification(PACLIC 2015)论文阅读笔记的全部内容,更多相关Bidirectional内容请搜索靠谱客的其他文章。


![[ACL2016]Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification](https://www.shuijiaxian.com/files_image/reation/bcimg9.png)





发表评论 取消回复