这一节主要涉及到的数据挖掘算法是关联规则及Apriori算法。
由此展开电商网站数据分析模型的构建和电商网站商品自动推荐的实现,并扩展到协同过滤算法。
关联规则最有名的故事就是啤酒与尿布的故事,非常有效地说明了关联规则在知识发现和数据挖掘中起的作用和意义。
其中有几个专用词的概念:
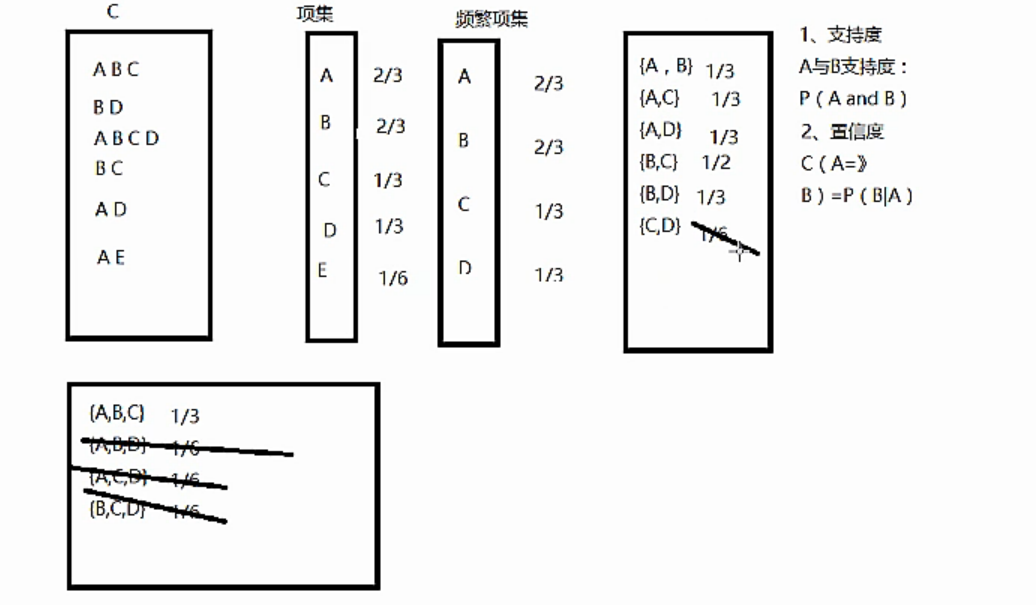
支持度:A与B的支持度Support(A->B)表示为P(A and B)。支持度揭示了A与B同时出现的概率。如果A与B同时出现的概率小,说明A与B的关系不大;如果A与B同时出现的非常频繁,则说明A与B总是相关的。
置信度:如果A发生那么B发生的概率。Confidence(A->B)=support(A->B)/suport(A)。置信度揭示了A出现时,B是否也会出现或有多大概率出现。如果置信度度为100%,则A和B可以捆绑销售了。如果置信度太低,则说明A的出现与B是否出现关系不大。
项集:项的集合称为项集。包含k个项的项集称为k-项集。
如果存在一条关联规则,它的支持度和置信度都大于预先定义好的最小支持度与置信度,我们就称它为强关联规则。强关联规则就可以用来了解项之间的隐藏关系。所以关联分析的主要目的就是为了寻找强关联规则,而Apriori算法则主要用来帮助寻找强关联规则。
Apriori算法的步骤如下:
1.自连接获取候选集。第一轮的候选集就是数据集D中的项,而其他轮次的候选集则是由前一轮次频繁集自连接得到(频繁集由候选集剪枝得到)。
2.对于候选集进行剪枝。如何剪枝呢?候选集的每一条记录T,如果它的支持度小于最小支持度,那么就会被剪掉;此外,如果一条记录T,它的子集有不是频繁集的,也会被剪掉。
一个实际的粗糙例子是:
Apriori的实现如下:
# -*- coding: utf-8 -*-
from __future__ import print_function
import pandas as pd
# 自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):
x = list(map(lambda i: sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i, len(x)):
if x[i][:l - 1] == x[j][:l - 1] and x[i][l - 1] != x[j][l - 1]:
r.append(x[i][:l - 1] + sorted([x[j][l - 1], x[i][l - 1]]))
return r
# 寻找关联规则的函数
def find_rule(d, support, confidence, ms=u'--'):
result = pd.DataFrame(index=['support', 'confidence']) # 定义输出结果
support_series = 1.0 * d.sum() / len(d) # 支持度序列
column = list(support_series[support_series > support].index) # 初步根据支持度筛选
k = 0
while len(column) > 1:
k = k + 1
print(u'n正在进行第%s次搜索...' % k)
column = connect_string(column, ms)
print(u'数目:%s...' % len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only=True) # 新一批支持度的计算函数
# 创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf, column)), index=[ms.join(i) for i in column]).T
support_series_2 = 1.0 * d_2[[ms.join(i) for i in column]].sum() / len(d) # 计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) # 新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column: # 遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j] + i[j + 1:] + i[j:j + 1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) # 定义置信度序列
for i in column2: # 计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))] / support_series[ms.join(i[:len(i) - 1])]
for i in cofidence_series[cofidence_series > confidence].index: # 置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort(['confidence', 'support'], ascending=False) # 结果整理,输出
print(u'n结果为:')
print(result)
return result
主要为连接函数和寻找关联规则的函数,其中需要定义support和confidence的值,需要折中选择这两个值,保证得到满意的结果。
ms为连接符。就是一个循环连接和查找的过程。
下面是使用Apriori算法实现商品个性化的推荐。
# coding = utf-8
# Apriori算法,实现见apriori模块,以下为应用
# 使用Apriori算法实现商品个性化推荐
from apriori import *
import pandas as pda
filename = "/home/hadoop/Downloads/lesson_buy.xls"
dataframe = pda.read_excel(filename, sheetname=0, header=None)
# 转化一下数据
change = lambda x: pda.Series(1, index=x[pda.notnull(x)])
mapok = map(change, dataframe.as_matrix())
data = pda.DataFrame(list(mapok)).fillna(0)
print(data)
# 临界支持度、置信度设置
support = 0.2
confidence = 0.5
# 使用Apriori算法计算关联结果
find_rule(data, support, confidence, "-->")下面是得到的结果:
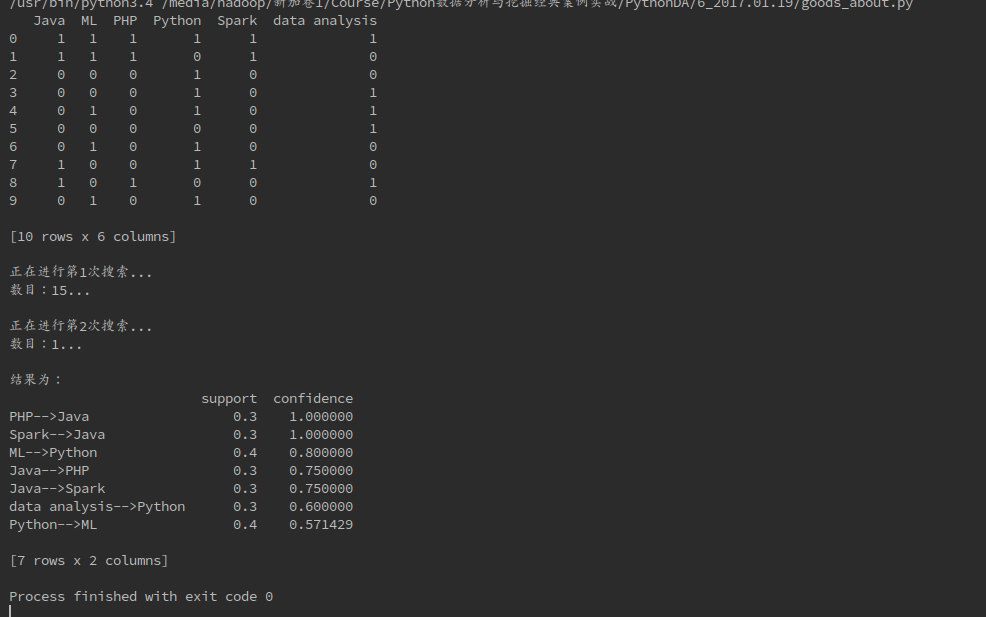
可以通过不同尝试不同的置信度和支持度来获得更可靠的结果。
下面提一下协同过滤算法:

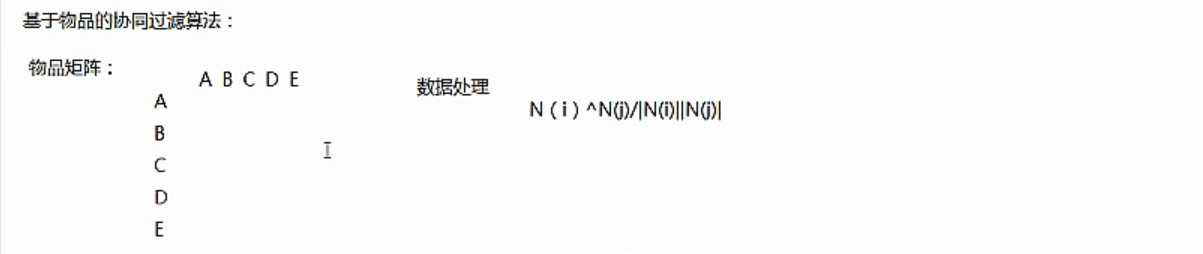
协同过滤算法是将每个点转换为概率的形式,根据倒排表,得到矩阵,计算出同一用户对不同物品感兴趣的概率之后,可以将相似品味的用户喜欢的物品推荐给该用户。比如,上面计算对于用户2,分别对A,D,E感兴趣的概率,然后取最大的推荐给该用户。其中每一个物品的计算方法是求得对该物品感兴趣的用户与用户2之间的相似度,比如,计算用户2对D物品感兴趣的概率,则计算用户2与对D感兴趣的用户1,4,5之间的相似度w之和,其中w的计算方法为余弦公式的计算,w(2,1) = |用户1和用户2的交集|/|用户1|×|用户2|.其中|.|为求模。
协同过滤算法分为两种,一种是基于用户的协同过滤算法,第二种是基于物品的协同过滤算法。
最后
以上就是发嗲金毛最近收集整理的关于python数据分析与挖掘学习笔记(6)-电商网站数据分析及商品自动推荐实战与关联规则算法的全部内容,更多相关python数据分析与挖掘学习笔记(6)-电商网站数据分析及商品自动推荐实战与关联规则算法内容请搜索靠谱客的其他文章。








发表评论 取消回复